
演算法導論 第七章:快速排序 筆記(快速排序的描述、快速排序的效能、快速排序的隨機化版本、快速排序分析)
快速排序的最壞情況時間複雜度為Θ(n^2)。雖然最壞情況時間複雜度很差,但是快速排序通常是實際排序應用中最好的選擇,因為它的平均效能很好。它的期望執行時間複雜度為Θ(n lg n),而且Θ(n lg n)中蘊含的常數因子非常小,而且它還是原址排序的。
快速排序是一種排序演算法,對包含n個數的輸人陣列,最壞情況執行時間為Θ(n^2) 。雖然這個最壞情況執行時間比較差,但快速排序通常是用於排序的最佳的實用選擇,這是因為其平均效能相當好:期望的執行時間為Θ(nlgn), 且Θ(nlgn)記號中隱含的常數因子很小。另外, 它還能夠進行就地排序,在虛存環境中也能很好地工作。
快速排序的描述:
快速排序也採用分治法進行排序,首先在陣列中選擇一個元素P,根據元素P將陣列劃分為兩個子陣列,在元素P左側的子陣列的所有元素都小於或等於該元素P,右側的子陣列的所有元素都大於元素P。
下面是對一個典型子陣列A[p...r]排序的分治過程的三個步驟:
分解:
陣列A[p..r]被劃分為兩個子陣列A[p..q-1]和A[q+1..r]使得A[p..q-1]中的每個元素都小於等於A(q),而且,元素A(q)小於等於A[q+1..r]中的元素。下標q也在這個劃分過程中進行計算。
解決:
通過遞迴呼叫快速排序,對子陣列A[p..q-1]和A[q+1...r]排序。
合併:
因為兩個子陣列是就地排序的,將它們的合併不需要操作:整個陣列A [ p.. r ] 己排序。
虛擬碼:
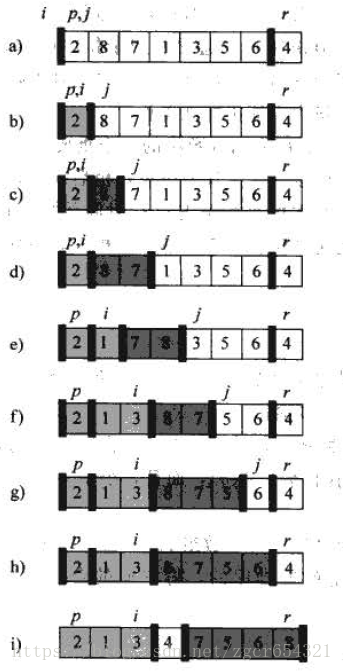
//快速排序 QUICKSORT(A,p,r) if p < r //當陣列中只剩一個元素時,退出遞迴,陣列已經有序 q <- PARTITION(A,p,r) QUICKSORT(A,p,q-1) //對小於等於A[q]的元素進行遞迴 QUICKSORT(A,q+1,r) //對大於A[q]的元素進行遞迴 //陣列劃分 PARTITION(A,p,r) x <- A[r] //將A[r]選取為“主元” i <- p - 1 //因為可能不存在小於等於A[r]的元素,所以i的值由p-1開始 for j <- p to r-1 if A[j] <= x i <- i + 1 //小於等於x的元素增加一個 exchange A[i] <-> A[j] //i+1後,i指向了一個大於x的元素,此時,j指向的是一個小於等於x的元素,交換這兩個元素的位置,使其符合規則 exchange A[i+1] <-> A[r] //r前所有元素比較完後,將A[r]置於正確位置:兩個子陣列的交界處 return i + 1 //返回"主元"的位置
如:


習題:
7.1-2:
當陣列A[p.. r] 中的元素均相同時, PARTITION返回的q值是什麼?修改PARTITION,使得當陣列A[p.. r] 中所有元素的值相同時, q = (p+r)/2 。
返回最後一個元素r 。
修改PARTITION:
PARTITION_1(A,p,r) x <- A[r] i <- p - 1 count <- 0 //加入一個計數器 for j <- p to r - 1 if A[j]<= x if A[i] == x count = count + 1 i <- i + 1 exchange A[i] <-> A[j] if count == r - p + 1 return (p + r)/2 exchange A[i + 1] <-> A[r] return i + 1
快速排序的效能:
快速排序的執行時間依賴於劃分是否平衡,如果劃分平衡,那麼快速排序演算法效能與歸併排序一樣,如果劃分不平衡,那麼快速排序的效能就接近於插入排序了。
最壞情況劃分(不平衡):
最壞情況下,每次劃分的兩個子問題都分別包含了n-1個元素和0個元素。劃分操作的時間複雜度是 Θ(n),因為對一個大小為0的陣列進行遞迴呼叫後,返回了T(n)=O(1),故演算法的執行時間可遞迴的表示為:
T(n) = T(n-1) + T(0) + Θ(n) =T(n-1) + Θ(n)
該遞迴式的解為:T(n) =Θ(n^2)。因此,最壞情況下,也就是陣列中元素已經排好序的時候,快速排序的時間複雜度為Θ(n^2),而在同樣的情況下,插入排序的時間複雜度為O(n)。
最好情況劃分(最平衡):
最好的情況下,每次劃分都是平均的劃分為n/2個元素子陣列,此時遞迴式為:
T(n) = 2T(n/2) +T(0) + Θ(n)
該式的解為T(n) = Θ(nlgn)。
快速排序的平均執行時間更接近於其最好情況,而非最壞情況。
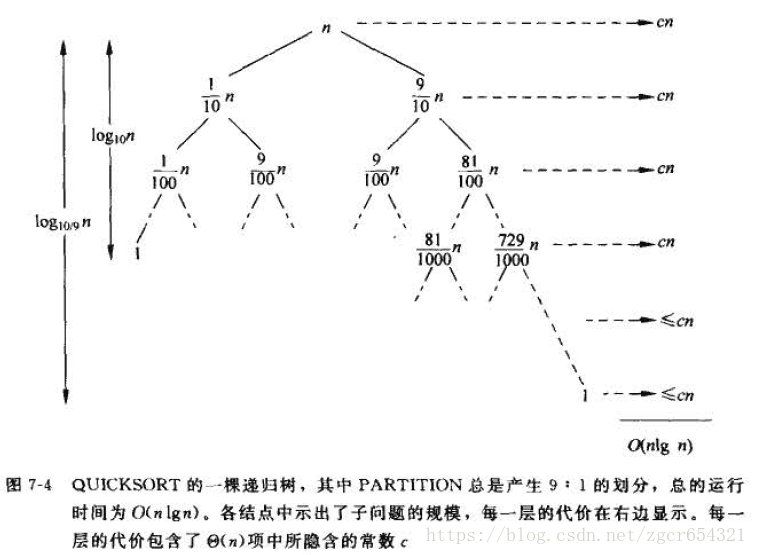
事實上,任何一種常數比例的劃分都會產生深度為Θ(nlgn)的遞迴樹,其中每一層的代價都是O(n),因此,只要劃分是常數比例的,演算法的執行時間總是O(nlgn)。
如:
例如,假設劃分過程總是產生9 : 1 的劃分,乍一看這種劃分很不平衡,這時,快速排序執行時間的遞迴式為
T(n) <= T(9n/10) + T(n/10) + cn
該樹每一層的代價都是cn, 直到在深度
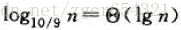
當資料量很小的時候,比如只有十幾個元素的小型序列,快排的優勢並不明顯,甚至比插入排序慢。但是一旦資料多,它的優勢就充分發揮出來了。
C++ STL 中的sort函式,就充分發揮了快排的優勢,並且取長補短,在資料量大時採用QuickSort,分段遞迴排序。一旦分段後的資料量小於某個門檻,為避免QuickSort遞迴呼叫帶來過大的額外負荷,就改用插入排序。如果遞迴層次過深,還會改用HeapSort(堆排序)。所以說,C++的“混合兵種”sort的效能肯定會比C的qsort好。
習題:
7.2-1:
利用代換法證明: 遞迴式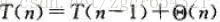
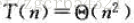
這裡只證明上界,下界可類似證明。
猜測
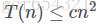
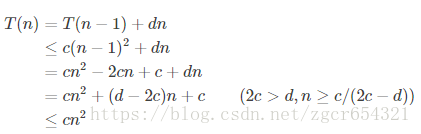
綜合上下界有T(n)=Θ(n2)。
7.2-2:
當陣列A 的所有元素都具有相同值時, QUICKSORT 的執行時間是什麼?
當陣列A的所有元素都具有相同值時,此時出現最壞情況,每次劃分會出現大小為0和n−1的子陣列,此時時間複雜度為Θ(n2)。
快速排序的隨機化版本:
當輸入的資料是隨機排列的時候,快速排序的時間複雜度是O(nlgn)。但是在實際中,輸入並不總是隨機的,因此需要在演算法中引入隨機性,可以對輸入進行重新排列是演算法實現隨機化, 也可以進行隨機抽樣,隨機抽樣是從陣列A[p…r]中隨機選擇一個元素作為主元。
虛擬碼:
Randomized-Partition(A, p, r)
i <- Random(p, r)
exchange A[r] <-> A[i]
return Partition(A, p, r)
Randomized-Quick-sort(A, p, r)
if p < r
q <- Randomized-Partition(A, p, r)
Randomized-Quick-sort(A, p, q-1)
Randomized-Quick-sort(A, q+1, r)
使用尾遞迴優化快速排序:
傳統的遞迴演算法在很多時候被視為洪水猛獸. 它的名聲狼籍, 好像永遠和低效聯絡在一起,尾遞迴是極其重要的,不用尾遞迴,函式的堆疊耗用難以估量,需要儲存很多中間函式的堆疊。
QUICKSORT演算法包含兩個對其自身的遞迴呼叫,即呼叫PARTITION後,左邊的子陣列和右邊的子陣列分別被遞迴排序。
QUICKSORT中的第二次遞迴呼叫並不是必須的,可以用迭代控制結構來代替它,這種技術叫做“尾遞迴”,大多數的編譯器也使用了這項技術。
下面的虛擬碼模擬了尾遞迴:
QUICKSORT'(A, p, r)
while p < r
do ▸ Partition and sort left subarray.
q <- PARTITION(A, p, r)
QUICKSORT'(A, p, q - 1)
p <- q + 1注意第一行是while而不是if。
上面的版本在最壞的情況下,就是劃分不好的時候,遞迴深度為O(n)。
我們還可以進一步優化,用二分思想,為了使最壞情況下棧的深度為Θ(lgn),我們必須讓PARTITION後左邊的子陣列為原來陣列的一半大小,這樣遞迴的深度最多為Θ(lgn)。
一種處理方案:
首先求得(A, p, r)的中位數,作為PARTITION的樞軸元素,這樣可以保證左右兩邊的元素的個數儘可能的均衡。
因為求中位數的過程MEDIAN的時間複雜度為Θ(n),因此可以保證演算法的期望的時間複雜度O(nlgn)不變。
優化後的尾遞迴快排:
QUICKSORT (A, p, r)
while p < r
do Partition and sort the small subarray Prst
q <- PARTITION(A,p,r)
if q - p < r - q
then QUICKSORT (A, p, q - 1)
p <- q + 1
else QUICKSORT (A, q + 1,r)
r <- q - 1除此之外,快排還可以有優化:
三數取中:
從子陣列中隨機選出三個元素,取其中間數作為主元,不過這隻能影響快速排序時間複雜度O(nlgn)的常數因子。
非遞迴方法:
即模擬遞迴,這樣可以完全消去遞迴的呼叫。
三劃分快速排序:
基本思想是,在劃分階段以V=A[r]為基準,將帶排序陣列A[p..r]劃分為左、中、右三段A[p,j],A[j+1..q-1],A[q..r],其中左段陣列元素值小於V,中斷陣列等於V,有段陣列元素大於V。其後,演算法對左右兩段陣列遞迴排序。 這個方法對於有大量相同資料的陣列排序效率有很大的提高,即使沒有大量相同元素,也不降低原快排演算法的效率。
快速排序分析:
利用RANDOMIZED-PARTITION,快速排序演算法期望的執行時間當元素值不同時,為O(nlgn)。

習題:
7.4-1:
證明:在遞迴式: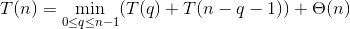
使用代換法。
猜測 T(n) <= c*n^2,c為某個常數。
選擇足夠大的c,使得 c*(2*n-1)可以支配Θ(n), T(n) <= c*n^2成立。
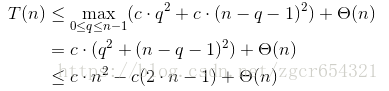
7.4-4:
證明:RANDOMIZED-QUICKSORT 演算法的期望執行時間是Ω(nlgn)。
