
稀疏表示的高光譜分類
下圖是一個稀疏表示模型
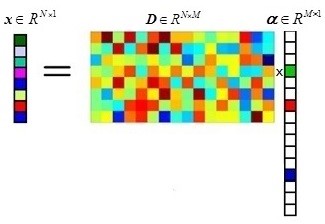
1.稀疏系數: 最右邊的α, 白色小格子表示0,有色小格子表示非0數(0,1),稀疏的意思就是非零系數很少。
2.字典:相信大家在做科研的時候,應該都聽說過字典Dictionary,那什麽是字典呢?字典,從名稱來看,可以用來查詢的字典,那查詢什麽呢?查詢(或者叫匹配)字典當中的訓練樣本。訓練樣本是一種模版,是一種已知類別的樣本。
字典的構成:我現在告訴你字典的一列表示一個訓練樣本,它可以屬於某一個類,那麽圖中的M列就有M個訓練樣本。結合前面的高光譜圖像知識,高光譜圖像數據的一個像素就相當於字典中的一列(或者一個訓練樣本)了。現在你應該大概知道怎麽獲取訓練樣本了吧。
字典的構建
3.稀疏系數如何表示樣本: 如果把非零數有色格子在系數中的行數表示測試樣本x在字典D中匹配到的訓練樣本(模版)對應的列數 的相似性,那相似性最大的那個列數(或行數)所屬的列是不是就是我們的最佳分類結果?是的,這就是稀疏表示的概念。
樣本:樣本一直會是以一個向量的形式表示的。對於高光譜圖像,樣本就可以是一個光譜維的像素。對於人臉識別,樣本就可以是一張二維人臉轉換成一維之後的向量。其他的就依此類推了。
前面我們已經了解了高光譜圖像分類的一些基本概念,那這篇文章當中將講解高光譜圖像分類具體的流程是怎麽樣的。
以下是高光譜圖像分類的具體步驟:
1.導入indian_pines高光譜圖像三維數據(具體數據可以網上下載),將三維圖像數據轉換成二維圖像矩陣,二維矩陣中每一列是一個樣本。
2.導入indian_pines_gt高光譜圖像的二維樣本標定圖,在圖中按比例為每個類選取訓練樣本的位置,並到1步中選取二維矩陣中選取對應的列作為訓練樣本。剩下別的位置就作為測試樣本了。
3.為每個測試樣本求解稀疏表示系數。具體方法有OMP算法等,該方法網上可查,或者參考一些國外大牛的論文(最好不要看中國人寫的文獻,我現在覺得國人為了刷分類精度,論文灌水太嚴重,自己沒搞清算法就開始瞎掰搞論文)。4.根據稀疏表示系數,還原測試樣本信號。原始樣本與復原樣本在每一類情況下的誤差,選誤差最小的類作為最佳分類結果。
5.
稀疏表示的高光譜分類