
Java進階專題(二十一) 訊息中介軟體架構體系(3)-- Kafka研究
阿新 • • 發佈:2021-01-18
# 前言
Kafka 是一款分散式訊息釋出和訂閱系統,具有高效能、高吞吐量的特點而被廣泛應用與大資料傳輸場景。它是由 LinkedIn 公司開發,使用 Scala 語言編寫,之後成為 Apache 基金會的一個頂級專案。kafka 提供了類似 JMS 的特性,但是在設計和實現上是完全不同的,而且他也不是 JMS 規範的實現。
# Kafka簡介
## kafka產生背景
kafka 作為一個訊息系統,早起設計的目的是用作 LinkedIn 的活動流(Activity Stream)和運營資料處理管道(Pipeline)。活動流資料是所有的網站對使用者的使用情況做分析的時候要用到的最常規的部分,活動資料包括頁面的訪問量(PV)、被檢視內容方面的資訊以及搜尋內容。這種資料通常的處理方式是先把各種活動以日誌的形式寫入某種檔案,然後週期性的對這些檔案進行統計分析。運營資料指的是伺服器的效能資料(CPU、IO 使用率、請求時間、服務日誌等)。
## Kafka應用場景
由於 kafka 具有更好的吞吐量、內建分割槽、冗餘及容錯性的優點(kafka 每秒可以處理幾十萬訊息),讓 kafka 成為了一個很好的大規模訊息處理應用的解決方案。
所以在企業級應用長,主要會應用於如下幾個方面
**行為跟蹤**:kafka 可以用於跟蹤使用者瀏覽頁面、搜尋及其他行為。通過釋出-訂閱模式實時記錄到對應的 topic中,通過後端大資料平臺接入處理分析,並做更進一步的實時處理和監控
**日誌收集**:日誌收集方面,有很多比較優秀的產品,比如 Apache Flume,很多公司使用kafka 代理日誌聚合。日誌聚合表示從伺服器上收集日誌檔案,然後放到一個集中的平臺(檔案伺服器)進行處理。在實際應用開發中,我們應用程式的 log 都會輸出到本地的磁碟上,排查問題的話通過 linux 命令來搞定,如果應用程式組成了負載均衡叢集,並且叢集的機器有幾十臺以上,那麼想通過日誌快速定位到問題,就是很麻煩的事情了。所以一般都會做一個日誌統一收集平臺管理 log 日誌用來快速查詢重要應用的問題。所以很多公司的套路都是把應用日誌幾種到 kafka 上,然後分別匯入到 es 和 hdfs 上,用來做實時檢索分析和離線統計資料備份等。而另一方面,kafka 本身又提供了很好的 api 來整合日誌並且做日誌收集
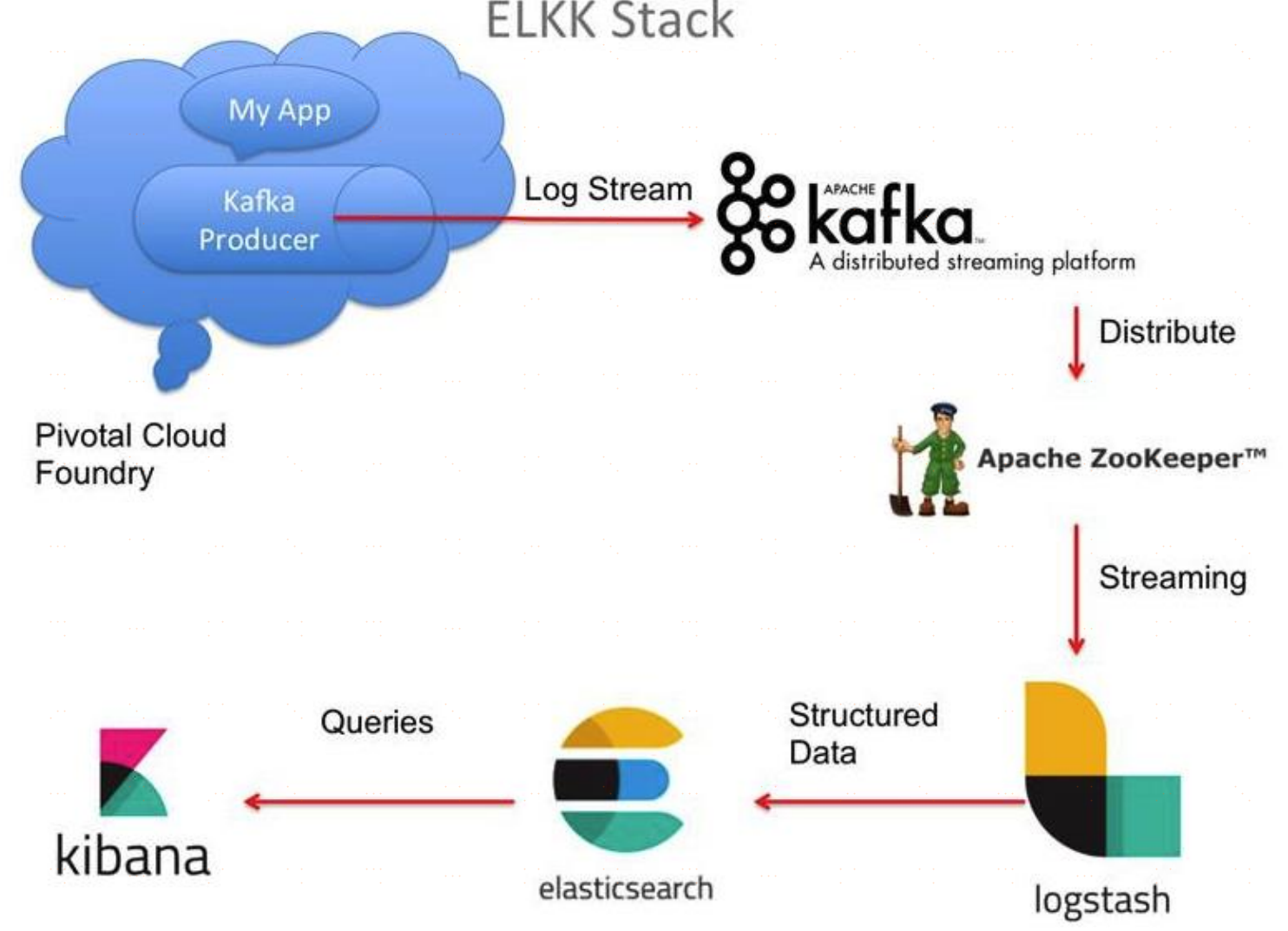
## kafka架構
一個典型的 kafka 叢集包含若干 Producer(可以是應用節點產生的訊息,也可以是通過Flume 收集日誌產生的事件),若干個 Broker(kafka 支援水平擴充套件)、若干個 Consumer Group,以及一個 zookeeper 叢集。kafka 通過 zookeeper 管理叢集配置及服務協同。
Producer 使用 push 模式將訊息釋出到 broker,consumer 通過監聽使用 pull 模式從broker 訂閱並消費訊息。多個 broker 協同工作,producer 和 consumer 部署在各個業務邏輯中。三者通過zookeeper 管理協調請求和轉發。這樣就組成了一個高效能的分散式訊息釋出和訂閱系統。圖上有一個細節是和其他 mq 中介軟體不同的點,producer 傳送訊息到 broker的過程是 push,而 consumer 從 broker 消費訊息的過程是 pull,主動去拉資料。而不是 broker 把資料主動傳送給 consumer
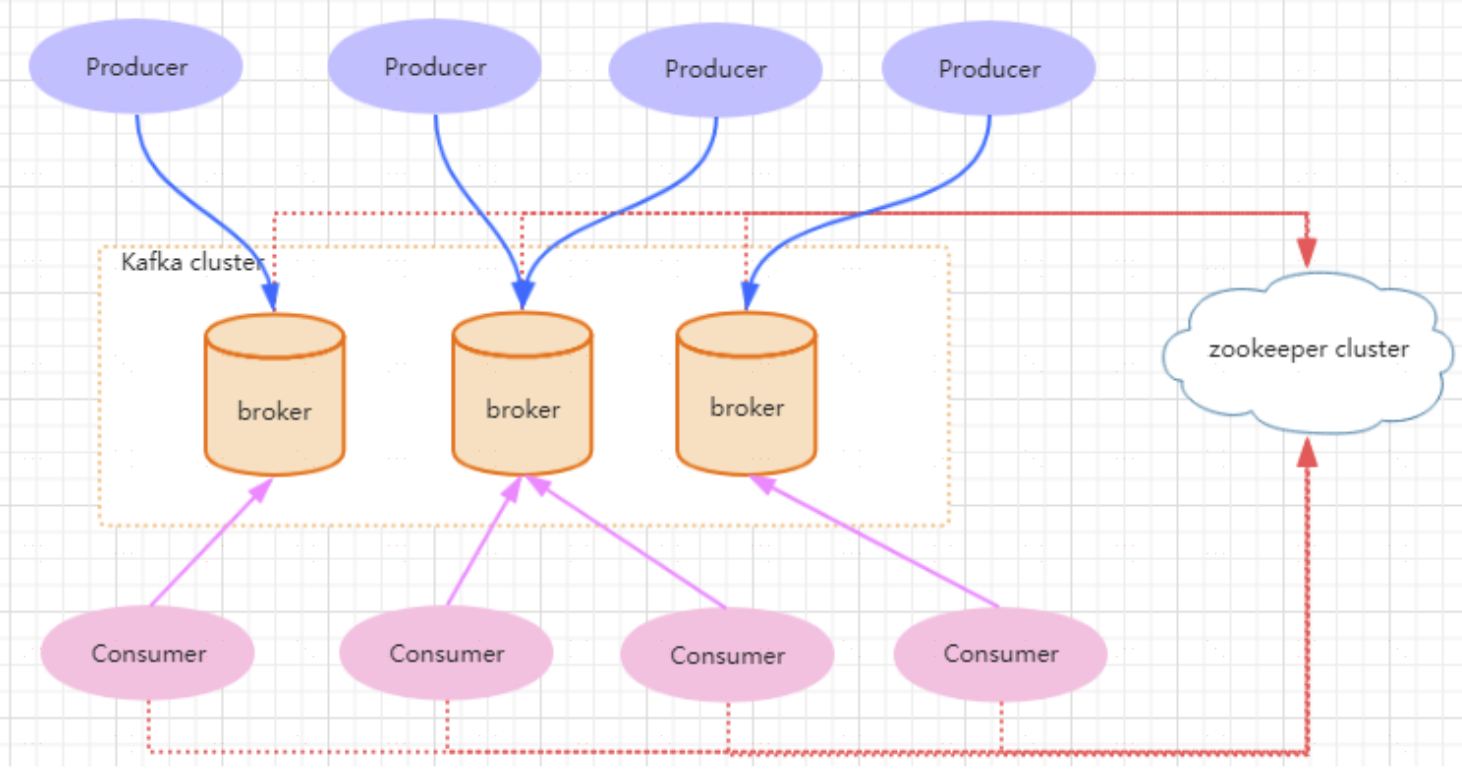
**名詞解釋**:
**Topic**
Kafka將訊息分門別類,每一類的訊息稱之為一個主題(Topic)。
**Producer**
釋出訊息的物件稱之為主題生產者(Kafka topic producer)
**Consumer**
訂閱訊息並處理髮布的訊息的物件稱之為主題消費者(consumers)
**Broker**
已釋出的訊息儲存在一組伺服器中,稱之為Kafka叢集。叢集中的每一個伺服器都是一個代理(Broker)。 消費者可以訂閱一個或多個主題(topic),並從Broker拉資料,從而消費這些已釋出的訊息。
## Topic和Log
Topic是釋出的訊息的類別名,一個topic可以有零個,一個或多個消費者訂閱該主題的訊息。
對於每個topic,Kafka叢集都會維護一個分割槽log,就像下圖中所示:
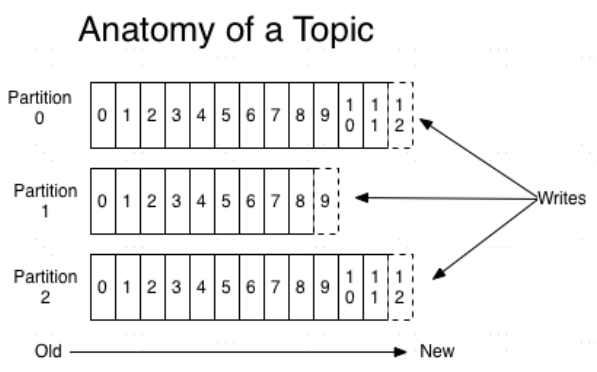
每一個分割槽都是一個順序的、不可變的訊息佇列, 並且可以持續的新增。分割槽中的訊息都被分了一個序列號,稱之為偏移量(offset),在每個分割槽中此偏移量都是唯一的。
Kafka叢集保持所有的訊息,直到它們過期(無論訊息是否被消費)。實際上消費者所持有的僅有的元資料就是這個offset(偏移量),也就是說offset由消費者來控制:正常情況當消費者消費訊息的時候,偏移量也線性的的增加。但是實際偏移量由消費者控制,消費者可以將偏移量重置為更早的位置,重新讀取訊息。可以看到這種設計對消費者來說操作自如,一個消費者的操作不會影響其它消費者對此log的處理。
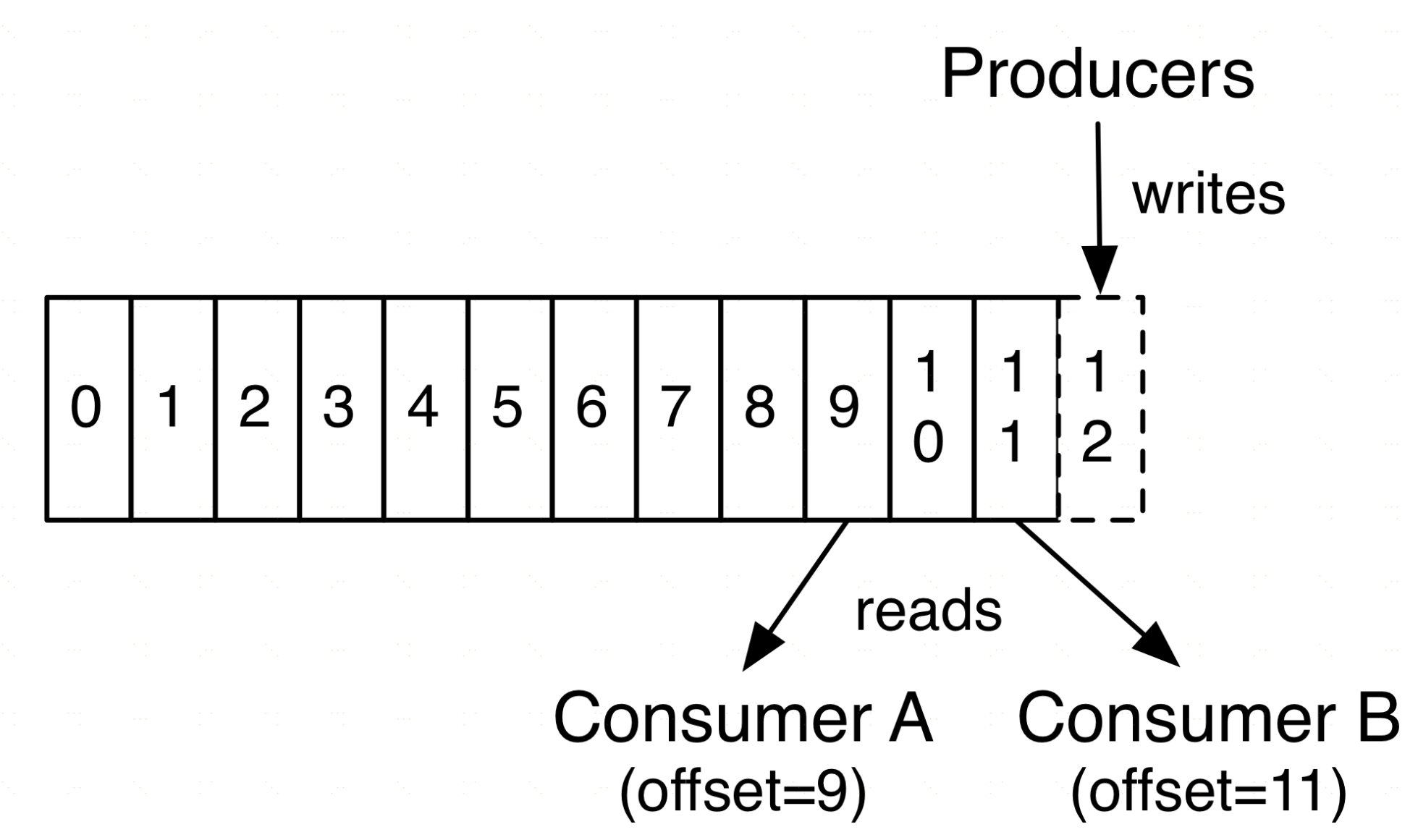
再說說分割槽。Kafka中採用分割槽的設計有幾個目的。一是可以處理更多的訊息,不受單臺伺服器的限制。Topic擁有多個分割槽意味著它可以不受限的處理更多的資料。第二,分割槽可以作為並行處理的單元,稍後會談到這一點。
## 分散式
Log的分割槽被分佈到叢集中的多個伺服器上。每個伺服器處理它分到的分割槽。 根據配置每個分割槽還可以複製到其它伺服器作為備份容錯。 每個分割槽有一個leader,零或多個follower。Leader處理此分割槽的所有的讀寫請求,而follower被動的複製資料。如果leader宕機,其它的一個follower會被推舉為新的leader。 一臺伺服器可能同時是一個分割槽的leader,另一個分割槽的follower。 這樣可以平衡負載,避免所有的請求都只讓一臺或者某幾臺伺服器處理。
## 生產者
生產者往某個Topic上釋出訊息。生產者也負責選擇釋出到Topic上的哪一個分割槽。最簡單的方式從分割槽列表中輪流選擇。也可以根據某種演算法依照權重選擇分割槽。開發者負責如何選擇分割槽的演算法。
## 消費者
通常來講,訊息模型可以分為兩種, 佇列和釋出-訂閱式。 佇列的處理方式是 一組消費者從伺服器讀取訊息,一條訊息只有其中的一個消費者來處理。在釋出-訂閱模型中,訊息被廣播給所有的消費者,接收到訊息的消費者都可以處理此訊息。Kafka為這兩種模型提供了單一的消費者抽象模型: 消費者組 (consumer group)。 消費者用一個消費者組名標記自己。 一個釋出在Topic上訊息被分發給此消費者組中的一個消費者。 假如所有的消費者都在一個組中,那麼這就變成了queue模型。 假如所有的消費者都在不同的組中,那麼就完全變成了釋出-訂閱模型。 更通用的, 我們可以建立一些消費者組作為邏輯上的訂閱者。每個組包含數目不等的消費者, 一個組內多個消費者可以用來擴充套件效能和容錯。正如下圖所示:
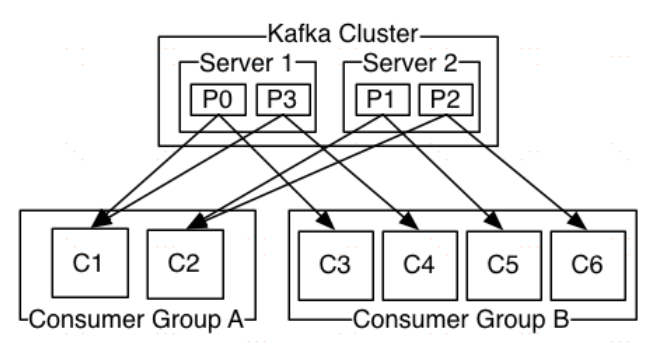
2個kafka叢集託管4個分割槽(P0-P3),2個消費者組,消費組A有2個消費者例項,消費組B有4個。
正像傳統的訊息系統一樣,Kafka保證訊息的順序不變。 再詳細扯幾句。傳統的佇列模型保持訊息,並且保證它們的先後順序不變。但是, 儘管伺服器保證了訊息的順序,訊息還是非同步的傳送給各個消費者,消費者收到訊息的先後順序不能保證了。這也意味著並行消費將不能保證訊息的先後順序。用過傳統的訊息系統的同學肯定清楚,訊息的順序處理很讓人頭痛。如果只讓一個消費者處理訊息,又違背了並行處理的初衷。 在這一點上Kafka做的更好,儘管並沒有完全解決上述問題。 Kafka採用了一種分而治之的策略:分割槽。 因為Topic分割槽中訊息只能由消費者組中的唯一一個消費者處理,所以訊息肯定是按照先後順序進行處理的。但是它也僅僅是保證Topic的一個分割槽順序處理,不能保證跨分割槽的訊息先後處理順序。 所以,如果你想要順序的處理Topic的所有訊息,那就只提供一個分割槽。
# Docker搭建kafka
## 下載以下三個映象
```shell
docker pull wurstmeister/zookeeper
docker pull wurstmeister/kafka
docker pull sheepkiller/kafka-manager
```
kafka-manager是kafka的視覺化管理工具
## 啟動容器
```shell
docker run -d --name zookeeper --publish 2181:2181 \--volume /etc/localtime:/etc/localtime \--restart=always \wurstmeister/zookeeper
```
```shell
docker run -d --name kafka --publish 9082:9092 \--link zookeeper:zookeeper \--env KAFKA_BROKER_ID=100 \--env HOST_IP=127.0.0.1 \--env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \--env KAFKA_ADVERTISED_HOST_NAME=192.168.1.108 \--env KAFKA_ADVERTISED_PORT=9082 \--restart=always \--volume /etc/localtime:/etc/localtime \wurstmeister/kafka
```
```shell
docker run -d --name kafka-manager \--link zookeeper:zookeeper \--link kafka:kafka -p 9001:9000 \--restart=always \--env ZK_HOSTS=zookeeper:2181 \sheepkiller/kafka-manager
```
## 訪問
http://127.0.0.1:9001
##新增Cluster
## 檢視介面
搭建完畢,頁面其他功能自己摸索下
# Kafka快速入門
```java
//以下Spring Boot應用程式將三個訊息傳送到一個主題,接收它們,然後停止:
@SpringBootApplication
public class Application implements CommandLineRunner {
public static Logger logger = LoggerFactory.getLogger(Application.class);
public static void main(String[] args) {
SpringApplication.run(Application.class, args).close();
}
@Autowired
private KafkaTemplate template;
private final CountDownLatch latch = new CountDownLatch(3);
@Override
public void run(String... args) throws Exception {
this.template.send("myTopic", "foo1");
this.template.send("myTopic", "foo2");
this.template.send("myTopic", "foo3");
latch.await(60, TimeUnit.SECONDS);
logger.info("All received");
}
@KafkaListener(topics = "myTopic")
public void listen(ConsumerRecord cr) throws Exception {
logger.info(cr.toString());
latch.countDown();
}
}
```
# Kafka進階
##通訊原理
訊息是 kafka 中最基本的資料單元,在 kafka 中,一條訊息由 key、 value 兩部分構成,在傳送一條訊息時,我們可以指定這個 key,那麼 producer 會根據 key 和 partition 機制來判斷當前這條訊息應該傳送並存儲到哪個 partition 中。我們可以根據需要進行擴充套件 producer 的 partition 機制。
#### 訊息預設的分發機制
預設情況下,kafka 採用的是 hash 取模的分割槽演算法。如果Key 為 null,則會隨機分配一個分割槽。這個隨機是在這個引數”metadata.max.age.ms”的時間範圍內隨機選擇一個。對於這個時間段內,如果 key 為 null,則只會傳送到唯一的分割槽。這個值值哦預設情況下是 10 分鐘更新一次。
關於 Metadata ,這個之前沒講過,簡單理解就是T opic/Partition 和 broker 的對映關係,每一個 topic 的每一個 partition,需要知道對應的 broker 列表是什麼, leader是誰、 follower 是誰。這些資訊都是儲存在 Metadata 這個類裡面。
#### 消費端如何消費指定的分割槽
```java
//通過下面的程式碼,就可以消費指定該 topic 下的 0 號分割槽。其他分割槽的資料就無法接收
//消費指定分割槽的時候,不需要再訂閱
//kafkaConsumer.subscribe(Collections.singletonList(topic));
//消費指定的分割槽
TopicPartition topicPartition=new
TopicPartition(topic,0);
kafkaConsumer.assign(Arrays.asList(topicPartit
ion));
```
###消費原理
在實際生產過程中,每個 topic 都會有多個 partitions,多個 partitions 的好處在於,一方面能夠對 broker 上的資料進行分片有效減少了訊息的容量從而提升 io 效能。另外一方面,為了提高消費端的消費能力,一般會通過多個consumer 去消費同一個 topic ,也就是消費端的負載均衡機制,也就是我們接下來要了解的,在多個partition 以及多個 consumer 的情況下,消費者是如何消費訊息的同時,在上一節課,我們講了, kafka 存在 consumer group的 概 念 , 也 就是 group.id 一樣 的 consumer ,這些consumer 屬於一個 consumer group,組內的所有消費者協調在一起來消費訂閱主題的所有分割槽。當然每一個分割槽只能由同一個消費組內的 consumer 來消費,那麼同一個consumer group 裡面的 consumer 是怎麼去分配該消費哪個分割槽裡的資料的呢?如下圖所示, 3 個分割槽, 3 個消費者,那麼哪個消費者消分哪個分割槽?
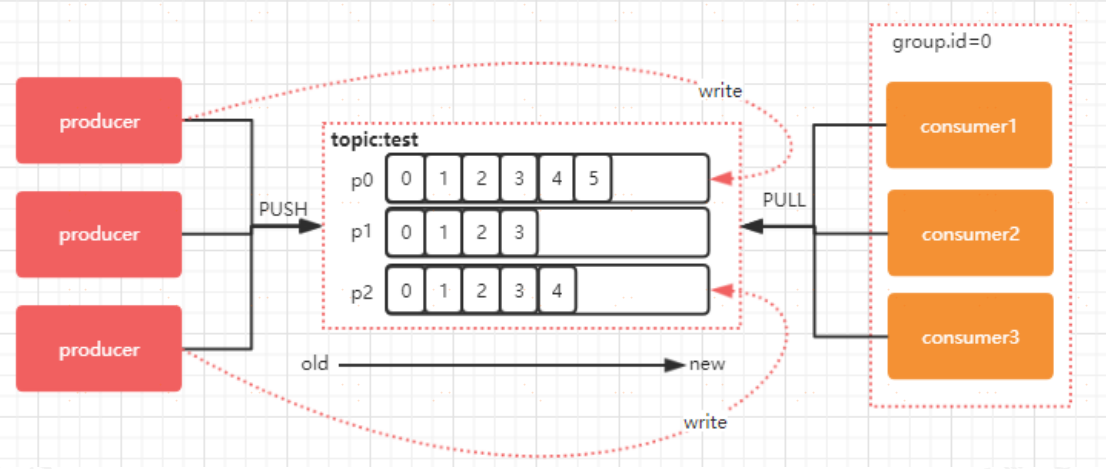
**分割槽分配策略**
在 kafka 中,存在兩種分割槽分配策略,一種是 Range(預設)、另 一 種 另 一 種 還 是 RoundRobin ( 輪 詢 )。 通過partition.assignment.strategy 這個引數來設定。
**Range strategy(範圍分割槽)**
Range 策略是對每個主題而言的,首先對同一個主題裡面的分割槽按照序號進行排序,並對消費者按照字母順序進行排序。假設我們有 10 個分割槽,3 個消費者,排完序的分割槽將會是 0, 1, 2, 3, 4, 5, 6, 7, 8, 9;消費者執行緒排完序將會是C1-0, C2-0, C3-0。然後將 partitions 的個數除於消費者執行緒的總數來決定每個消費者執行緒消費幾個分割槽。如果除不盡,那麼前面幾個消費者執行緒將會多消費一個分割槽。在我們的例子裡面,我們有 10 個分割槽,3 個消費者執行緒, 10 / 3 = 3,而且除不盡,那麼消費者執行緒 C1-0 將會多消費一個分割槽,所以最後分割槽分配的結果看起來是這樣的:
C1-0 將消費 0, 1, 2, 3 分割槽
C2-0 將消費 4, 5, 6 分割槽
C3-0 將消費 7, 8, 9 分割槽
假如我們有 11 個分割槽,那麼最後分割槽分配的結果看起來是這樣的:
C1-0 將消費 0, 1, 2, 3 分割槽
C2-0 將消費 4, 5, 6, 7 分割槽
C3-0 將消費 8, 9, 10 分割槽
假如我們有 2 個主題(T1 和 T2),分別有 10 個分割槽,那麼最後分割槽分配的結果看起來是這樣的:
C1-0 將消費 T1 主題的 0, 1, 2, 3 分割槽以及 T2 主題的 0, 1, 2, 3 分割槽
C2-0 將消費 T1 主題的 4, 5, 6 分割槽以及 T2 主題的 4, 5, 6 分割槽
C3-0 將消費 T1 主題的 7, 8, 9 分割槽以及 T2 主題的 7, 8, 9 分割槽
可以看出,C1-0 消費者執行緒比其他消費者執行緒多消費了 2 個分割槽,這就是 Range strategy 的一個很明顯的弊端
**RoundRobin strategy(輪詢分割槽)**
輪詢分割槽策略是把所有 partition 和所有 consumer 執行緒都列出來,然後按照 hashcode 進行排序。最後通過輪詢演算法分配 partition 給消費執行緒。如果所有 consumer 例項的訂閱是相同的,那麼 partition 會均勻分佈。
在我們的例子裡面,假如按照 hashCode 排序完的 topicpartitions 組依次為 T1-5, T1-3, T1-0, T1-8, T1-2, T1-1, T1-4, T1-7, T1-6, T1-9,我們的消費者執行緒排序為 C1-0, C1-1, C2-0, C2-1,最後分割槽分配的結果為:
C1-0 將消費 T1-5, T1-2, T1-6 分割槽;
C1-1 將消費 T1-3, T1-1, T1-9 分割槽;
C2-0 將消費 T1-0, T1-4 分割槽;
C2-1 將消費 T1-8, T1-7 分割槽;
使用輪詢分割槽策略必須滿足兩個條件
1. 每個主題的消費者例項具有相同數量的流
2. 每個消費者訂閱的主題必須是相同的
**什麼時候會觸發這個策略呢?**
當出現以下幾種情況時,kafka 會進行一次分割槽分配操作,
也就是 kafka consumer 的 rebalance
1. 同一個 consumer group 內新增了消費者
2. 消費者離開當前所屬的 consumer group,比如主動停機或者宕機
3. topic 新增了分割槽(也就是分割槽數量發生了變化)
kafka consuemr 的 rebalance 機制規定了一個 consumergroup 下的所有 consumer 如何達成一致來分配訂閱 topic的每個分割槽。而具體如何執行分割槽策略,就是前面提到過的兩種內建的分割槽策略。而 kafka 對於分配策略這塊,提供了可插拔的實現方式, 也就是說,除了這兩種之外,我們還可以建立自己的分配機制。
**什麼時候會觸發這個策略呢?**
當出現以下幾種情況時,kafka 會進行一次分割槽分配操作,也就是 kafka consumer 的 rebalance
1. 同一個 consumer group 內新增了消費者
2. 消費者離開當前所屬的 consumer group,比如主動停機或者宕機
3. topic 新增了分割槽(也就是分割槽數量發生了變化)kafka consuemr 的 rebalance 機制規定了一個 consumergroup 下的所有 consumer 如何達成一致來分配訂閱 topic的每個分割槽。而具體如何執行分割槽策略,就是前面提到過的兩種內建的分割槽策略。而 kafka 對於分配策略這塊,提供了可插拔的實現方式, 也就是說,除了這兩種之外,我們還可以建立自己的分配機制。
**誰來執行 Rebalance 以及管理 consumer 的 group 呢?**
Kafka 提供了一個角色: coordinator 來執行對於 consumer group 的管理,Kafka 提供了一個角色:coordinator 來執行對於 consumer group 的管理,當 consumer group 的第一個 consumer 啟動的時候,它會去和 kafka server 確定誰是它們組的 coordinator。之後該 group 內的所有成員都會和該 coordinator 進行協調通訊
**如何確定 coordinator**
consumer group 如何確定自己的 coordinator 是誰呢, 消費 者 向 kafka 集 群 中 的 任 意 一 個 broker 發 送 一 個GroupCoordinatorRequest 請求,服務端會返回一個負載最 小 的 broker 節 點 的 id , 並 將 該 broker 設 置 為coordinator
**JoinGroup 的過程**
在 rebalance 之前,需要保證 coordinator 是已經確定好了的,整個 rebalance 的過程分為兩個步驟,Join 和 Syncjoin: 表示加入到 consumer group 中,在這一步中,所有的成員都會向 coordinator 傳送 joinGroup 的請求。一旦所有成員都發送了 joinGroup 請求,那麼 coordinator 會選擇一個 consumer 擔任 leader 角色,並把組成員資訊和訂閱資訊傳送消費者
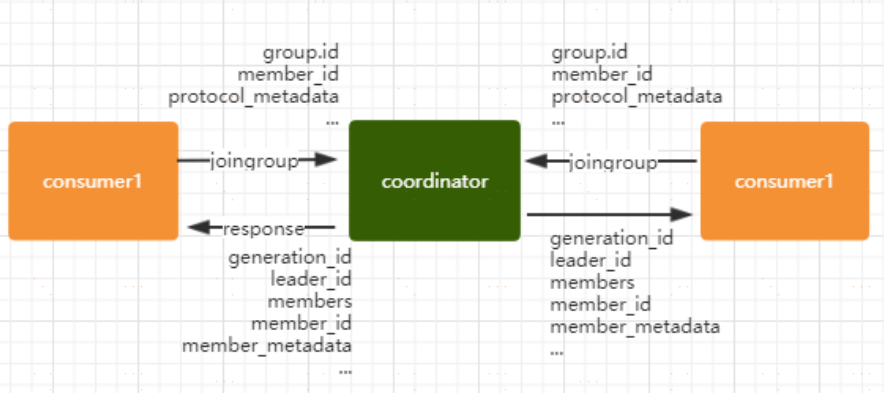
protocol_metadata: 序列化後的消費者的訂閱資訊
leader_id: 消費組中的消費者,coordinator 會選擇一個座位 leader,對應的就是 member_id
member_metadata 對應消費者的訂閱資訊
members:consumer group 中全部的消費者的訂閱資訊
generation_id: 年代資訊,類似於之前講解 zookeeper 的時候的 epoch 是一樣的,對於每一輪 rebalance ,
generation_id 都會遞增。主要用來保護 consumer group。隔離無效的 offset 提交。也就是上一輪的 consumer 成員無法提交 offset 到新的 consumer group 中。
**Synchronizing Group State 階段**
完成分割槽分配之後,就進入了 Synchronizing Group State階段,主要邏輯是向 GroupCoordinator 傳送SyncGroupRequest 請求,並且處理 SyncGroupResponse響應,簡單來說,就是 leader 將消費者對應的 partition 分配方案同步給 consumer group 中的所有 consumer
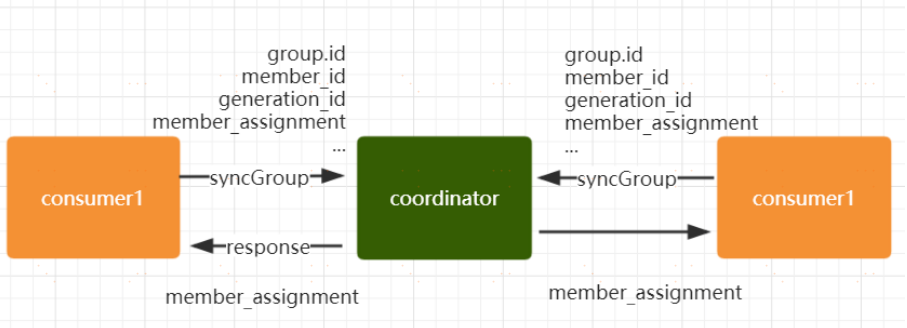
每個消費者都會向 coordinator 傳送 syncgroup 請求,不過只有 leader 節點會發送分配方案,其他消費者只是打打醬油而已。當 leader 把方案發給 coordinator 以後,coordinator 會把結果設定到 SyncGroupResponse 中。這樣所有成員都知道自己應該消費哪個分割槽。
➢ consumer group 的分割槽分配方案是在客戶端執行的!Kafka 將這個權利下放給客戶端主要是因為這樣做可以有更好的靈活性
#### 如何儲存消費端的消費位置
**什麼是 offset**
前面在講partition 的時候,提到過 offset, 每個 topic可以劃分多個分割槽(每個 Topic 至少有一個分割槽),同一topic 下的不同分割槽包含的訊息是不同的。每個訊息在被新增到分割槽時,都會被分配一個 offset(稱之為偏移量),它是訊息在此分割槽中的唯一編號, kafka 通過 offset 保證訊息在分割槽內的順序, offset 的順序不跨分割槽,即 kafka 只保證在同一個分割槽內的訊息是有序的; 對於應用層的消費來說,每次消費一個訊息並且提交以後,會儲存當前消費到的最近的一個 offset。那麼 offset 儲存在哪裡?
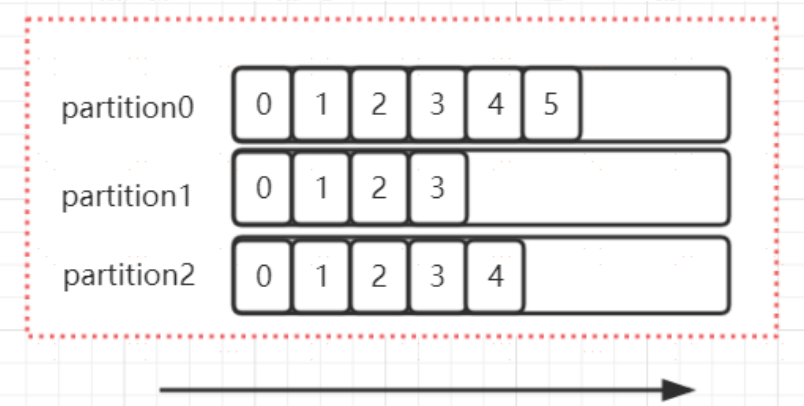
**offset 在哪裡維護?**
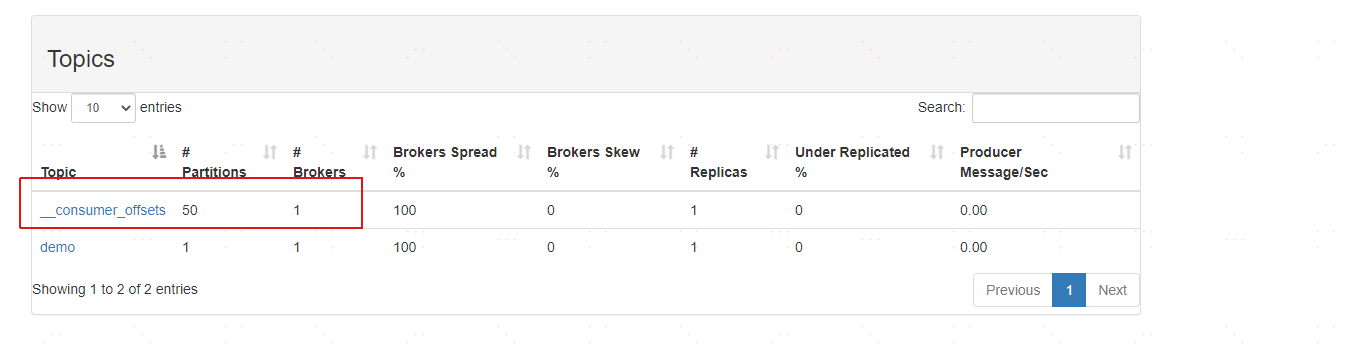
在 kafka 中,提供了一個__consumer_offsets_的一個topic ,把 offset 信 息 寫 入 到 這 個 topic 中。
_consumer_offsets——按儲存了每個 consumer group某一時刻提交的 offset 資訊。 consumer_offsets 預設有50 個分割槽。
###訊息的儲存原理
**訊息的儲存路徑**
訊息傳送端傳送訊息到 broker 上以後,訊息是如何持久化的呢?那麼接下來去分析下訊息的儲存
首先我們需要了解的是, kafka 是使用日誌檔案的方式來儲存生產者和傳送者的訊息,每條訊息都有一個 offset 值來表示它在分割槽中的偏移量。 Kafka 中儲存的一般都是海量的訊息資料,為了避免日誌檔案過大,Log 並不是直接對應在一個磁碟上的日誌檔案,而是對應磁碟上的一個目錄,這個目錄的明明規則是_比如建立一個名為 firstTopic 的 topic,其中有 3 個 partition,那麼在 kafka 的資料目錄(/tmp/kafka-log)中就有 3 個目錄,firstTopic-0~3
**多個分割槽在叢集中的分配**
如果我們對於一個 topic,在叢集中建立多個 partition,那麼 partition 是如何分佈的呢?
1.將所有 N Broker 和待分配的 i 個 Partition 排序
2.將第 i 個 Partition 分配到第(i mod n)個 Broker 上
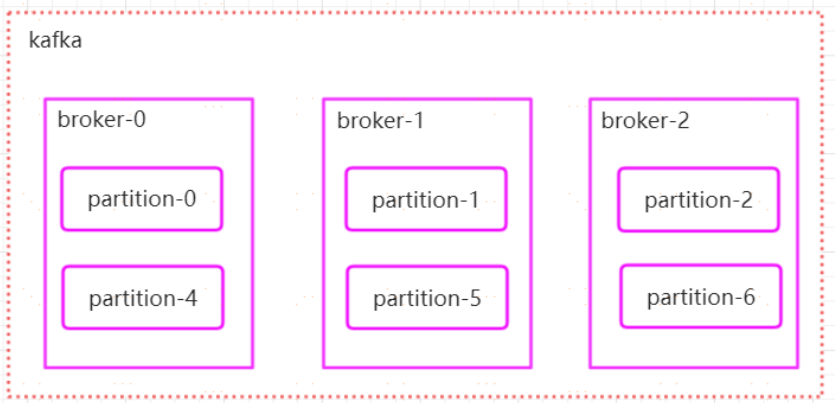
瞭解到這裡的時候,大家再結合前面講的訊息分發策略,就應該能明白訊息傳送到 broker 上,訊息會儲存到哪個分割槽中,並且消費端應該消費哪些分割槽的資料了。
**訊息寫入的效能**
我們現在大部分企業仍然用的是機械結構的磁碟,如果把訊息以隨機的方式寫入到磁碟,那麼磁碟首先要做的就是定址,也就是定位到資料所在的實體地址,在磁碟上就要找到對應的柱面、磁頭以及對應的扇區;這個過程相對記憶體來說會消耗大量時間,為了規避隨機讀寫帶來的時間消耗, kafka 採用順序寫的方式儲存資料。即使是這樣,但是頻繁的 I/O 操作仍然會造成磁碟的效能瓶頸,所以 kafka還有一個性能策略
#### 頁快取
順序寫入是Kafka高吞吐量的一個原因,當然即使採用的是磁碟的順序寫入,那麼也是沒有辦法和記憶體相比的。因為為了再一次提高Kakfa的吞吐量,Kafka採用了Memory Mapped Files
(後面簡稱mmap)也被翻譯成記憶體對映檔案 ,它的工作原理是直接利用作業系統的page cache 來實現檔案到實體記憶體的直接對映,完成對映之後你對實體記憶體的操作會被同步到硬碟上(作業系統在適當的時候)。
作業系統本身有一層快取,叫做page cache,是在記憶體裡的快取,我們也可以稱之為os cache,意思就是作業系統自己管理的快取。你在寫入磁碟檔案的時候,可以直接寫入這個os cache裡,也就是僅僅寫入記憶體中,接下來由作業系統自己決定什麼時候把os cache裡的資料真的刷入磁
盤檔案中(每5秒檢查一次是否需要將頁快取資料同步到磁碟檔案)。僅僅這一個步驟,就可以將磁碟檔案寫效能提升很多了,因為其實這裡相當於是在寫記憶體,不是在寫磁碟.
####**零拷貝**
訊息從傳送到落地儲存,broker 維護的訊息日誌本身就是檔案目錄,每個檔案都是二進位制儲存,生產者和消費者使用相同的格式來處理。在消費者獲取訊息時,伺服器先從硬碟讀取資料到記憶體,然後把記憶體中的資料原封不動的通過 socket 傳送給消費者。雖然這個操作描述起來很簡單,但實際上經歷了很多步驟。
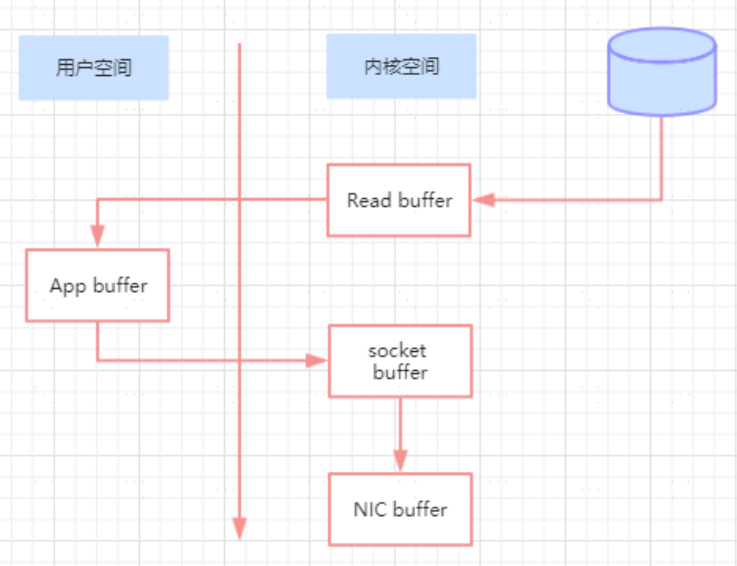
▪ 作業系統將資料從磁碟讀入到核心空間的頁快取
▪ 應用程式將資料從核心空間讀入到使用者空間快取中
▪ 應用程式將資料寫回到核心空間到 socket 快取中
▪ 作業系統將資料從 socket 緩衝區複製到網絡卡緩衝區,以便將資料經網路發出
這個過程涉及到 4 次上下文切換以及 4 次資料複製,並且有兩次複製操作是由 CPU 完成。但是這個過程中,資料完全沒有進行變化,僅僅是從磁碟複製到網絡卡緩衝區。
通過“**零拷貝**”技術,可以去掉這些沒必要的資料複製操作,同時也會減少上下文切換次數。現代的 unix 作業系統提供一個優化的程式碼路徑,用於將資料從頁快取傳輸到 socket;在 Linux 中,是通過 sendfile 系統呼叫來完成的。Java 提供了訪問這個系統呼叫的方法: FileChannel.transferTo API
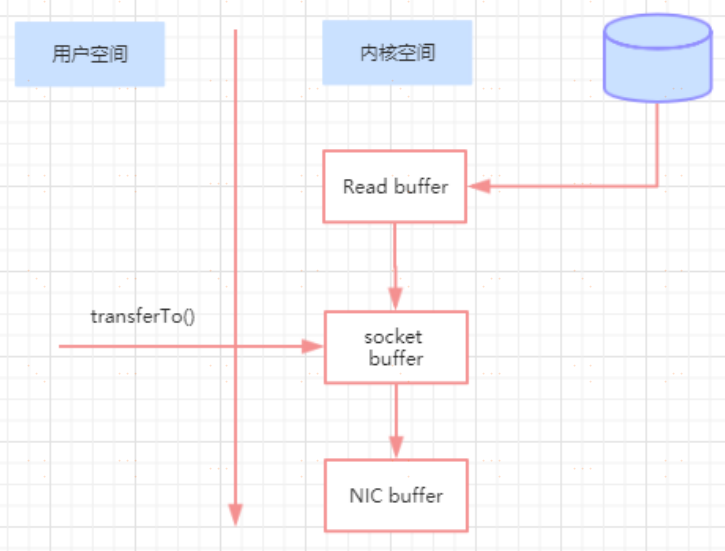
使用 sendfile,只需要一次拷貝就行,允許作業系統將資料直接從頁快取傳送到網路上。所以在這個優化的路徑中,只有最後一步將資料拷貝到網絡卡快取中是需要的
#### 訊息的檔案儲存機制
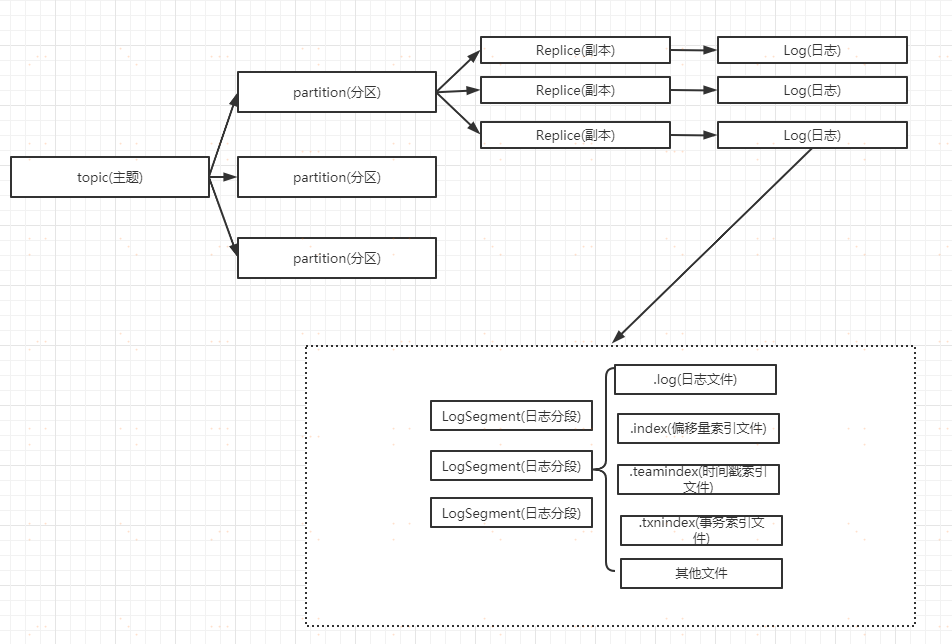
前面我們知道了一個 topic 的多個 partition 在物理磁碟上的儲存路徑,那麼我們再來分析日誌的儲存方式。通過如下命令找到對應 partition 下的日誌內容
```shell
[root@localhost ~]# ls /tmp/kafka-logs/firstTopic-1/00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex leader-epochcheckpoint
```
kafka 是通過分段的方式將 Log 分為多個 LogSegment,LogSegment 是一個邏輯上的概念,一個 LogSegment 對應磁碟上的一個日誌檔案和一個索引檔案,其中日誌檔案是用來記錄訊息的。索引檔案是用來儲存訊息的索引。那麼這個 LogSegment 是什麼呢?
**LogSegment**
假設 kafka 以 partition 為最小儲存單位,那麼我們可以想象當 kafka producer 不斷髮送訊息,必然會引起 partition檔案的無線擴張,這樣對於訊息檔案的維護以及被消費的訊息的清理帶來非常大的挑戰,所以 kafka 以 segment 為單位又把 partition 進行細分。每個 partition 相當於一個巨型檔案被平均分配到多個大小相等的 segment 資料檔案中(每個 segment 檔案中的訊息不一定相等),這種特性方便已經被消費的訊息的清理,提高磁碟的利用率。
➢ log.segment.bytes=107370 ( 設定分段大小 ), 預設是1gb,我們把這個值調小以後,可以看到日誌分段的效果
➢ 抽取其中 3 個分段來進行分析

segment file 由 2 大部分組成,分別為 index file 和 data file,此 2 個檔案一一對應,成對出現,字尾".index"和“.log”分別表示為 segment 索引檔案、資料檔案.segment 檔案命名規則:partion 全域性的第一個 segment從 0 開始,後續每個 segment 檔名為上一個 segment檔案最後一條訊息的 offset 值進行遞增。數值最大為 64 位long 大小,20 位數字字元長度,沒有數字用 0 填。
**segment 中 index 和 log 的對應關係**
從所有分段中,找一個分段進行分析為了提高查詢訊息的效能,為每一個日誌檔案新增 2 個索引索引檔案: OffsetIndex 和 TimeIndex,分別對應*.index以及*.timeindex, TimeIndex 索引檔案格式:它是對映時間戳和相對offset
```shell
查 看 索 引 內 容 : sh kafka-run-class.sh
kafka.tools.DumpLogSegments --files /tmp/kafkalogs/test-0/00000000000000000000.index --print-datalog
```
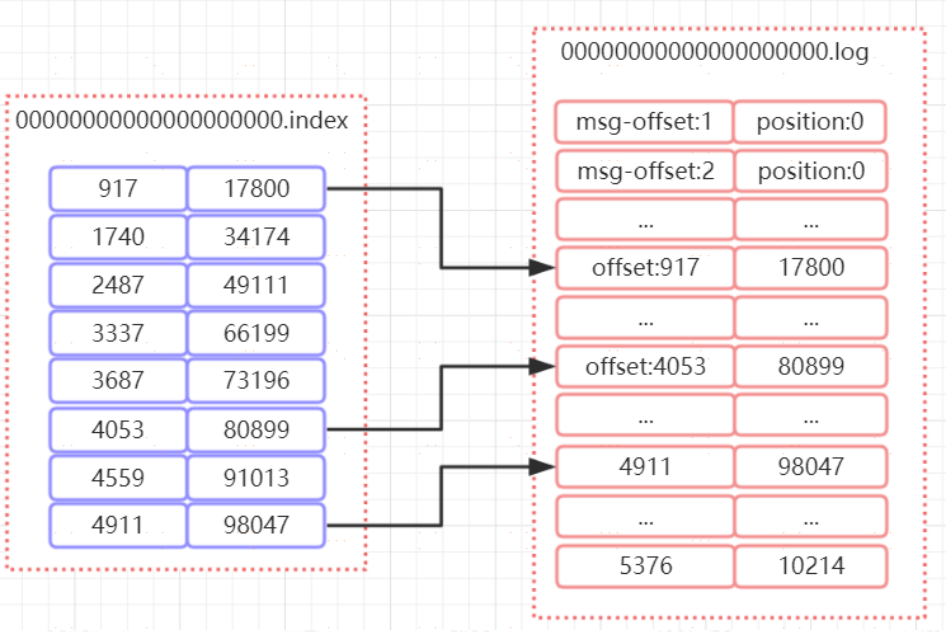
如圖所示,index 中儲存了索引以及物理偏移量。 log 儲存了訊息的內容。索引檔案的元資料執行對應資料檔案中
message 的物理偏移地址。舉個簡單的案例來說,以[4053,80899]為例,在 log 檔案中,對應的是第 4053 條記錄,物理偏移量( position )為 80899. position 是ByteBuffer 的指標位置
#### 在 partition 中如何通過 offset 查詢 message
1. 根據 offset 的值,查詢 segment 段中的 index 索引檔案。由於索引檔案命名是以上一個檔案的最後一個offset 進行命名的,所以,使用二分查詢演算法能夠根據offset 快速定位到指定的索引檔案。
2. 找到索引檔案後,根據 offset 進行定位,找到索引檔案中的符合範圍的索引。(kafka 採用稀疏索引的方式來提高查詢效能)
3. 得到 position 以後,再到對應的 log 檔案中,從 position出開始查詢 offset 對應的訊息,將每條訊息的 offset 與目標 offset 進行比較,直到找到訊息
比如說,我們要查詢 offset=2490 這條訊息,那麼先找到00000000000000000000.index, 然後找到[2487,49111]這個索引,再到 log 檔案中,根據 49111 這個 position 開始查詢,比較每條訊息的 offset 是否大於等於 2490。最後查詢到對應的訊息以後返回
#### 日誌清除策略
前面提到過,日誌的分段儲存,一方面能夠減少單個檔案內容的大小,另一方面,方便 kafka 進行日誌清理。日誌的清理策略有兩個
1. 根據訊息的保留時間,當訊息在 kafka 中儲存的時間超過了指定的時間,就會觸發清理過程
2. 根據 topic 儲存的資料大小,當 topic 所佔的日誌檔案大小大於一定的閥值,則可以開始刪除最舊的訊息。 kafka會啟動一個後臺執行緒,定期檢查是否存在可以刪除的訊息
通過 log.retention.bytes 和 log.retention.hours 這兩個引數來設定,當其中任意一個達到要求,都會執行刪除。預設的保留時間是:7 天
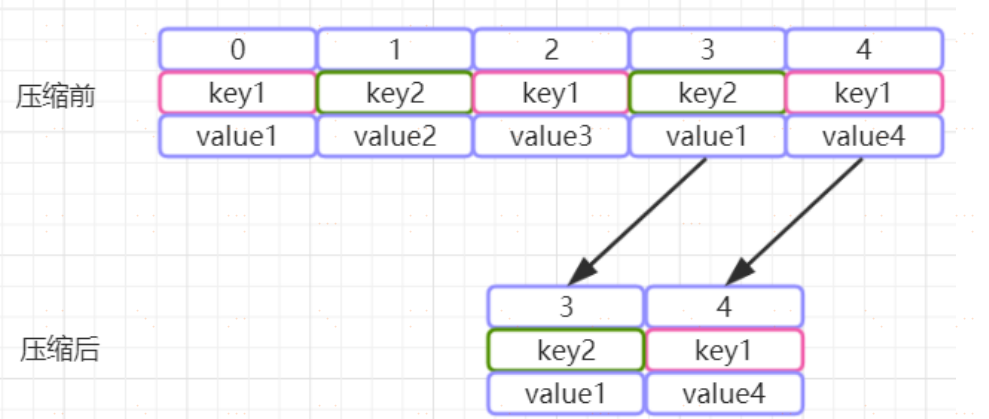
#### 日誌壓縮策略
Kafka 還提供了“日誌壓縮(Log Compaction)”功能,通過這個功能可以有效的減少日誌檔案的大小,緩解磁碟緊張的情況,在很多實際場景中,訊息的 key 和 value 的值之間的對應關係是不斷變化的,就像資料庫中的資料會不斷被修改一樣,消費者只關心 key 對應的最新的 value。 因此,我們可以開啟 kafka 的日誌壓縮功能,服務端會在後臺啟動啟動 Cleaner 執行緒池,定期將相同的 key 進行合併,只保留最新的 value 值。日誌的壓縮原理是
### partition 的高可用副本機制
我們已經知道 Kafka 的每個 topic 都可以分為多個 Partition,並且多個 partition 會均勻分佈在叢集的各個節點下。雖然這種方式能夠有效的對資料進行分片,但是對於每個partition 來說,都是單點的,當其中一個 partition 不可用的時候,那麼這部分訊息就沒辦法消費。所以 kafka 為了提高 partition 的可靠性而提供了副本的概念(Replica) ,通過副本機制來實現冗餘備份。每個分割槽可以有多個副本,並且在副本集合中會存在一個leader 的副本,所有的讀寫請求都是由 leader 副本來進行處理。剩餘的其他副本都做為 follower 副本,follower 副本 會 從 leader 副 本 同 步 消 息 日 志 。 這 個 有 點 類 似zookeeper 中 leader 和 follower 的概念,但是具體的時間方式還是有比較大的差異。所以我們可以認為,副本集會存在一主多從的關係。
一般情況下,同一個分割槽的多個副本會被均勻分配到叢集中的不同 broker 上,當 leader 副本所在的 broker 出現故障後,可以重新選舉新的 leader 副本繼續對外提供服務。通過這樣的副本機制來提高 kafka 叢集的可用性。
#### 副本分配演算法
將所有 N Broker 和待分配的 i 個 Partition 排序.
將第 i 個 Partition 分配到第(i mod n)個 Broker 上.
將第 i 個 Partition 的第 j 個副本分配到第((i + j) mod n)個Broker 上.
#### kafka 副本機制中的幾個概念
Kafka 分割槽下有可能有很多個副本(replica)用於實現冗餘,從而進一步實現高可用。副本根據角色的不同可分為 3 類:
leader 副本:響應 clients 端讀寫請求的副本
follower 副本:被動地備份 leader 副本中的資料,不能響應 clients 端讀寫請求。
ISR 副本:包含了 leader 副本和所有與 leader 副本保持同步的 follower 副本——如何判定是否與 leader 同步後面會提到每個 Kafka 副本物件都有兩個重要的屬性:LEO 和HW。注意是所有的副本,而不只是 leader 副本。
LEO:即日誌末端位移(log end offset),記錄了該副本底層日誌(log)中下一條訊息的位移值。注意是下一條訊息!也就是說,如果 LEO=10,那麼表示該副本儲存了 10 條訊息,位移值範圍是[0, 9]。另外, leader LEO 和follower LEO 的更新是有區別的。我們後面會詳細說
HW:即上面提到的水位值。對於同一個副本物件而言,其
HW 值不會大於 LEO 值。小於等於 HW 值的所有訊息都被認為是“ 已備份” 的(replicated )。同理, leader 副本和follower 副本的 HW 更新是有區別的
#### 副本協同機制
剛剛提到了,訊息的讀寫操作都只會由 leader 節點來接收和處理。follower 副本只負責同步資料以及當 leader 副本所在的 broker 掛了以後,會從 follower 副本中選取新的leader。
請求首先由 Leader 副本處理,之後 follower 副本會從leader 上拉取寫入的訊息,這個過程會有一定的延遲,導致 follower 副本中儲存的訊息略少於 leader 副本,但是隻要沒有超出閾值都可以容忍。但是如果一個 follower 副本出現異常,比如宕機、網路斷開等原因長時間沒有同步到訊息,那這個時候, leader 就會把它踢出去。 kafka 通過 ISR集合來維護一個分割槽副本資訊
**ISR**
ISR 表示目前“可用且訊息量與 leader 相差不多的副本集合,這是整個副本集合的一個子集”。怎麼去理解可用和相差不多這兩個詞呢?具體來說,ISR 集合中的副本必須滿足兩個條件
1. 副本所在節點必須維持著與 zookeeper 的連線
2. 副本最後一條訊息的 offset 與 leader 副本的最後一條訊息的 offset 之 間 的 差 值 不 能 超 過 指 定 的 閾值(replica.lag.time.max.ms)replica.lag.time.max.ms:如果該 follower 在此時間間隔內一直沒有追上過 leader 的所有訊息,則該 follower 就會被剔除 isr 列表
➢ ISR 數 據 保 存 在 Zookeeper 的/brokers/topics//partitions//state 節點中
**HW&LEO**
關於 follower 副本同步的過程中,還有兩個關鍵的概念,HW(HighWatermark)和 LEO(Log End Offset). 這兩個引數跟 ISR 集合緊密關聯。 HW 標記了一個特殊的 offset,當消費者處理訊息的時候,只能拉去到 HW 之前的訊息, HW之後的訊息對消費者來說是不可見的。也就是說,取partition 對應 ISR 中最小的 LEO 作為 HW,consumer 最多隻能消費到 HW 所在的位置。每個 replica 都有 HW,leader 和 follower 各自維護更新自己的 HW 的狀態。一條訊息只有被 ISR 裡的所有 Follower 都從 Leader 複製過去才會被認為已提交。這樣就避免了部分資料被寫進了Leader,還沒來得及被任何 Follower 複製就宕機了,而造成資料丟失(Consumer 無法消費這些資料)。而對於Producer 而言,它可以選擇是否等待訊息 commit,這可以通過 acks 來設定。這種機制確保了只要 ISR 有一個或以上的 Follower,一條被 commit 的訊息就不會丟失。
###資料的同步過程
瞭解了副本的協同過程以後,還有一個最重要的機制,就是資料的同步過程。它需要解決
1. 怎麼傳播訊息
2. 在向訊息傳送端返回 ack 之前需要保證多少個 Replica
已經接收到這個訊息
資料的處理過程是
Producer 在 發 布 消 息 到 某 個 Partition 時 ,先通過ZooKeeper 找到該 Partition 的 Leader 【 get /brokers/topics//partitions/2/state】,然後無論該Topic 的 Replication Factor 為多少(也即該 Partition 有多少個 Replica), Producer 只將該訊息傳送到該 Partition 的Leader。 Leader 會將該訊息寫入其本地 Log。每個 Follower都從 Leader pull 資料。這種方式上, Follower 儲存的資料順序與 Leader 保持一致。 Follower 在收到該訊息並寫入其Log 後,向 Leader 傳送 ACK。一旦 Leader 收到了 ISR 中的所有 Replica 的 ACK,該訊息就被認為已經 commit 了,Leader 將增加 HW(HighWatermark)並且向 Producer 傳送ACK。
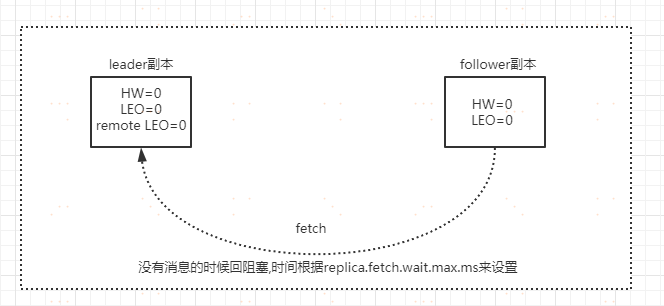
**初始狀態**
初始狀態下,leader 和 follower 的 HW 和 LEO 都是 0,leader 副本會儲存 remote LEO,表示所有 follower LEO,也會被初始化為 0,這個時候,producer 沒有傳送訊息。follower 會不斷地個 leader 傳送 FETCH 請求,但是因為沒有資料,這個請求會被 leader 寄存,當在指定的時間之後會 強 制 完 成 請 求 , 這 個 時 間 配 置 是(replica.fetch.wait.max.ms),如果在指定時間內 producer有訊息傳送過來,那麼 kafka 會喚醒 fetch 請求,讓 leader繼續處理
這裡會分兩種情況,第一種是 leader 處理完 producer 請求之後,follower 傳送一個 fetch 請求過來、第二種是follower 阻塞在 leader 指定時間之內,leader 副本收到producer 的請求。這兩種情況下處理方式是不一樣的。先來看第一種情況
**一、follower 的 fetch 請求是當 leader 處理訊息以後執行的**
leader 處理完 producer 請求之後,follower 傳送一個fetch 請求過來 。狀態圖如下
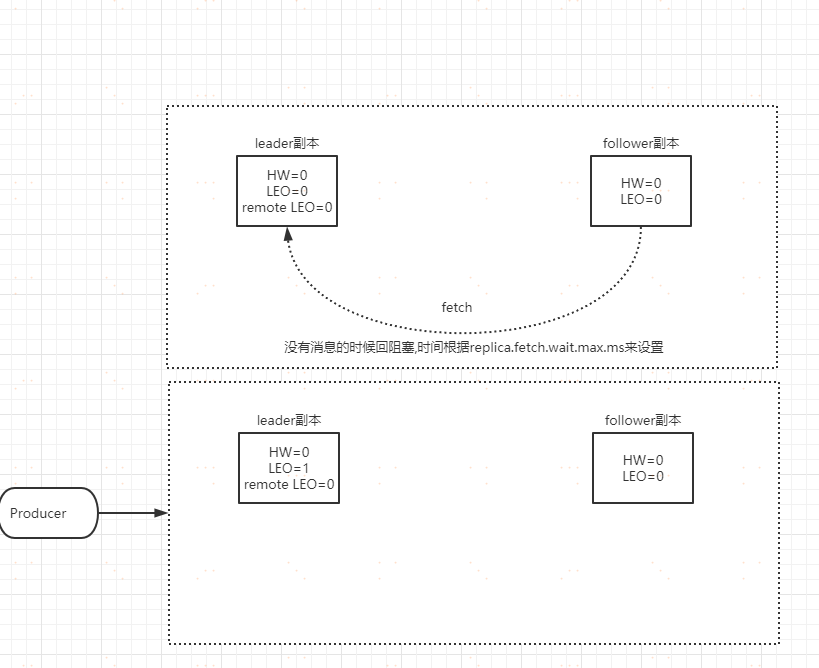
**leader 副本收到請求以後,會做幾件事情**
1. 把訊息追加到 log 檔案,同時更新 leader 副本的 LEO
2. 嘗試更新 leader HW 值。這個時候由於 follower 副本還沒有傳送 fetch 請求,那麼 leader 的 remote LEO 仍然是 0。leader 會比較自己的 LEO 以及 remote LEO 的值發現最小值是 0,與 HW 的值相同,所以不會更新 HW
**follower fetch 訊息**
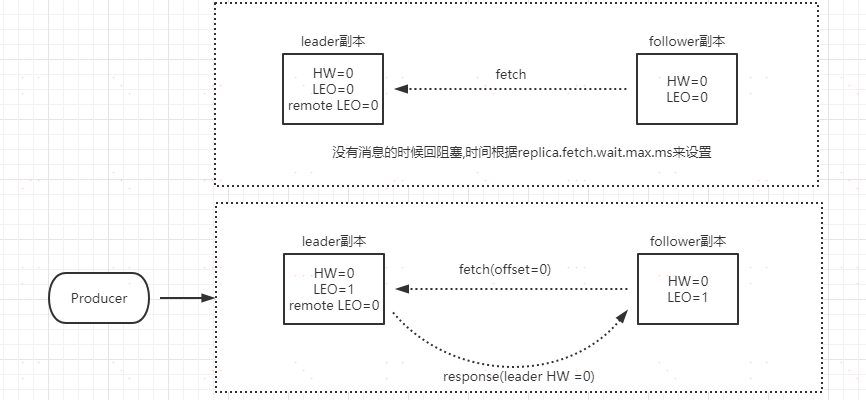
**follower 傳送 fetch 請求,leader 副本的處理邏輯是:**
1. 讀取 log 資料、更新 remote LEO=0(follower 還沒有寫入這條訊息,這個值是根據 follower 的 fetch 請求中的offset 來確定的)
2. 嘗試更新 HW,因為這個時候 LEO 和 remoteLEO 還是不一致,所以仍然是 HW=0
3. 把訊息內容和當前分割槽的 HW 值傳送給 follower 副本follower 副本收到 response 以後
1. 將訊息寫入到本地 log,同時更新 follower 的 LEO
2. 更新 follower HW,本地的 LEO 和 leader 返回的 HW進行比較取小的值,所以仍然是 0第一次互動結束以後, HW 仍然還是 0,這個值會在下一次follower 發起 fetch 請求時被更新
**follower 發第二次 fetch 請求,leader 收到請求以後**
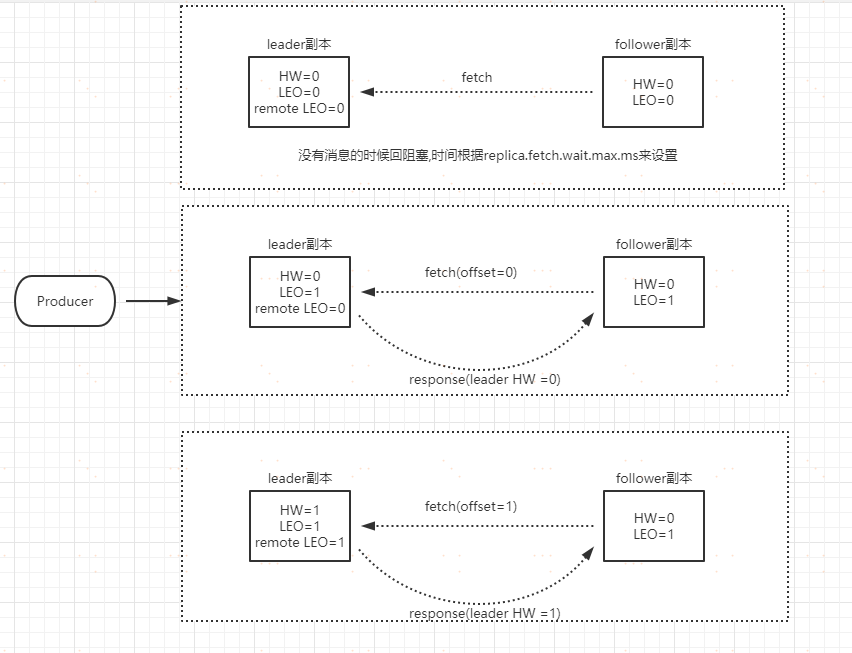
1. 讀取 log 資料
2. 更新 remote LEO=1, 因為這次 fetch 攜帶的 offset 是1.
3. 更新當前分割槽的 HW,這個時候 leader LEO 和 remoteLEO 都是 1,所以 HW 的值也更新為 1
4. 把資料和當前分割槽的 HW 值返回給 follower 副本,這個時候如果沒有資料,則返回為空
follower 副本收到 response 以後
1. 如果有資料則寫本地日誌,並且更新 LEO
2. 更新 follower 的 HW 值 到目前為止,資料的同步就完成了,意味著消費端能夠消費 offset=0 這條訊息。
**二、follower 的 fetch 請求是直接從阻塞過程中觸發**
前面說過,由於 leader 副本暫時沒有資料過來,所以follower 的 fetch 會被阻塞,直到等待超時或者 leader 接收到新的資料。當 leader 收到請求以後會喚醒處於阻塞的fetch 請求。處理過程基本上和前面說的一直
1. leader 將訊息寫入本地日誌,更新 Leader 的 LEO
2. 喚醒 follower 的 fetch 請求
3. 更新 HWkafka 使用 HW 和 LEO 的方式來實現副本資料的同步,本身是一個好的設計,但是在這個地方會存在一個數據丟失的問題,當然這個丟失只出現在特定的背景下。我們回想一下, HW 的值是在新的一輪 FETCH 中才會被更新。我們分析下這個過程為什麼會出現資料丟失
### 資料丟失問題
####問題描述
前提: min.insync.replicas=1 的時候。 ->設定 ISR 中的最小副本數是多少,預設值為 1, 當且僅當 acks 引數設定為-1(表示需要所有副本確認) 時,此引數才生效. 表達的含義是,至少需要多少個副本同步才能表示訊息是提交的所以,當 min.insync.replicas=1 的時候一旦訊息被寫入 leader 端 log 即被認為是“已提交”,而延遲一輪 FETCH RPC 更新 HW 值的設計使得 follower HW值是非同步延遲更新的,倘若在這個過程中 leader 發生變更,那麼成為新 leader 的 follower 的 HW 值就有可能是過期的,使得 clients 端認為是成功提交的訊息被刪除。
#### 資料丟失的解決方案
在 kafka0.11.0.0 版本以後,提供了一個新的解決方案,使用 leader epoch 來解決這個問題, leader epoch 實際上是一對之(epoch,offset), epoch 表示 leader 的版本號,從 0開始,當 leader 變更過 1 次時 epoch 就會+1,而 offset 則對應於該 epoch 版本的 leader 寫入第一條訊息的位移。比如說(0,0) ; (1,50); 表示第一個 leader 從 offset=0 開始寫訊息,一共寫了 50 條,第二個 leader 版本號是 1,從 50 條處開始寫訊息。這個資訊儲存在對應分割槽的本地磁碟檔案中,文 件 名 為 : /tml/kafka-log/topic/leader-epochcheckpointleader broker 中會儲存這樣的一個快取,並定期地寫入到一個 checkpoint 檔案中。
當 leader 寫 log 時它會嘗試更新整個快取——如果這個leader 首次寫訊息,則會在快取中增加一個條目;否則就不做更新。而每次副本重新成為 leader 時會查詢這部分快取,獲取出對應 leader 版本的 offset
#### 如何處理所有的 Replica 不工作的情況
在 ISR 中至少有一個 follower 時,Kafka 可以確保已經commit 的資料不丟失,但如果某個 Partition 的所有Replica 都宕機了,就無法保證資料不丟失了
1. 等待 ISR 中的任一個 Replica“活”過來,並且選它作為Leader
2. 選擇第一個“活”過來的 Replica(不一定是 ISR 中的)作為 Leader這就需要在可用性和一致性當中作出一個簡單的折衷。如果一定要等待 ISR 中的 Replica“活”過來,那不可用的時間就可能會相對較長。而且如果 ISR 中的所有 Replica 都無法“活”過來了,或者資料都丟失了,這個 Partition 將永遠不可用。
選擇第一個 “ 活 ” 過來的 Replica 作為 Leader ,而這個Replica 不是 ISR 中的 Replica,那即使它並不保證已經包含了所有已 commit 的訊息,它也會成為 Leader 而作為consumer 的資料來源(前文有說明,所有讀寫都由 Leader完成)。
#### ISR 的設計原理
在所有的分散式儲存中,冗餘備份是一種常見的設計方式,而常用的模式有同步複製和非同步複製,按照 kafka 這個副本模型來說如果採用同步複製,那麼需要要求所有能工作的 Follower 副本都複製完,這條訊息才會被認為提交成功,一旦有一個follower 副本出現故障,就會導致 HW 無法完成遞增,訊息就無法提交,消費者就獲取不到訊息。這種情況下,故障的Follower 副本會拖慢整個系統的效能,設定導致系統不可用.
如果採用非同步複製, leader 副本收到生產者推送的訊息後,就認為次訊息提交成功。follower 副本則非同步從 leader 副本同步。這種設計雖然避免了同步複製的問題,但是假設所有follower 副本的同步速度都比較慢他們儲存的訊息量遠遠落後於 leader 副本。而此時 leader 副本所在的 broker 突然宕機,則會重新選舉新的 leader 副本,而新的 leader 副本中沒有原來 leader 副本的訊息。這就出現了訊息的丟失。
kafka 權衡了同步和非同步的兩種策略,採用 ISR 集合,巧妙解決了兩種方案的缺陷:當 follower 副本延遲過高, leader 副本則會把該 follower 副本提出 ISR 集合,訊息依然可以快速提交。當 leader 副本所在的 broker 突然宕機,會優先將 ISR 集合中follower 副本選舉為 leader,新 leader 副本包含了 HW 之前的全部訊息,這樣就避免了訊息的丟失。
###Kafka順序性保證
Kafka保證訊息順序性的特點如下所示:
topic中的資料分割為一個或多個partition。每個topic至少有一個partition。在單個partition中的資料是有序的,如果訊息分散在不同的partition,Kafka 無法保證其順序性。但只需要確保要求順序性的若干訊息傳送到同一個partiton,即可滿足其順序性。並且在進行訊息消費的時候,需要確保消費者是進行單執行緒消費。
要保證若干訊息傳送到同一個partiton中,那麼我們就需要在傳送訊息的時候指定一個分割槽的id,那麼這樣的話訊息就被髮送到同一個分割槽中。
```java
// 傳送訊息到指定的分割槽,保證分割槽的訊息順序性
public static void sendMessageToDestPartition() {
for(int x = 0; x < 5; x++) {
// Kafka訊息的非同步傳送
String msg = "Kakfa環境測試...." + x;
kafkaTemplate.send("test",0, "order",
msg).addCallback((obj) -> 對應的序號的值加1。
broker端會在記憶體中為每一對維護一個序列號。對於收到的每一條訊息,會存在這樣的幾種情
況:
1、SN_new = SN_old + 1時,broker才會接收它。
2、SN_new < SN_old + 1,那麼說明訊息被重複寫入,broker可以直接將其丟棄。
3、SN_new > SN_old + 1,那麼說明中間有資料尚未寫入,出現了亂序,暗示可能有訊息丟失,對應的生產者會丟擲OutOfOrderSquenceException,這個異常時一個嚴重的異常。冪等性不能跨分割槽實現。
**相關知識**
冪等性並不能跨多個分割槽運作,比如我們現在要想傳送3個訊息,當第二個訊息傳送完畢以後程式報錯了,這樣第三個訊息就沒有傳送成功,當下一次在呼叫這個方法傳送資料的時候,就會導致訊息重複傳送(失去了冪等性)。而事務可以彌補這個缺憾,事務可以保證對多個分割槽寫入操作的原子性。操作的原子性是指多個操作要麼全部成功,要麼全部失敗,不存在部分成功部分失敗的可能。為了實現事務,應用程式必須提供唯一的transactionalId,這個引數通過客戶
端程式來進行設定。如下所示:
```yaml
spring.kafka.producer.transaction-id-prefix=order_tx. # 表示開啟事務機制
```
並且事務機制的使用需要冪等性的支援,所以我們還需要開啟冪等性:enable.idempotence = true。如果沒有開啟冪等性的支援,就會報錯,如下所示:
```shell
Caused by: org.apache.kafka.common.config.ConfigException: Cannot set a transactional.id without also enabling idempotence.
```
事務機制實現的兩種方式:
1、第一種方式
```java
// 事務訊息傳送的第一種方式
public static void sendTransactionMessageMethod01() {
// 傳送事務訊息
kafkaTemplate.executeInTransaction((operations) ->{
// 傳送訊息
kafkaTemplate.send("itcast", 0, "order", "事務訊息----> 1")
;
kafkaTemplate.send("itcast", 0, "order", "事務訊息----> 2")
;
// 產生異常程式碼
int a = 1 / 0;
kafkaTemplate.send("itcast", 0, "order", "事務訊息----> 3")
;
// 返回true,表示傳送成功
return true;
}) ;
LOGGER.info("send transaction message to local cache success ");
}
```
2、第二種方式
```java
@Transactional(rollbackFor = RuntimeException.class)
public void sendTransactionMessage() {
// 傳送訊息
kafkaTemplate.send("itcast", 0, "order", "事務訊息----> 1") ;
kafkaTemplate.send("itcast", 0, "order", "事務訊息----> 2") ;
// 產生異常程式碼
int a = 1 / 0;
kafkaTemplate.send("itcast", 0, "order", "事務訊息----> 3") ;
}
```
### 消費端訊息重複
1、根本原因
資料消費完沒有及時提交offset到broker。
解決方案
1、取消自動自動提交
每次消費完或者程式退出時手動提交。
2、下游做冪等
一般的解決方案是讓下游做冪等。
## Kafka為什麼快
###分割槽管理
Kafka可以將主題劃分為多個分割槽(Partition),會根據分割槽規則選擇把訊息儲存到哪個分割槽中,只要分割槽
規則設定的合理,那麼所有的訊息將會被均勻的分佈到不同的分割槽中,這樣就實現了負載均衡和水平擴充套件。另外,多個訂閱者可以從一個或者多個分割槽中同時消費資料,以支撐海量資料處理能力。順便說一句,由於訊息是以追加的方法儲存到分割槽中的,多個分割槽順序寫磁碟的總效率要比隨機寫記憶體還要高(引用Apache Kafka – A High Throughput Distributed Messaging System的觀點),是Kafka高吞吐率的重要保證之一。
####分割槽副本機制
由於Producer和Consumer都只會與Leader角色的分割槽副本相連,所以kafka需要以叢集的組織形式提供主題下的訊息高可用。kafka支援主備複製,所以訊息具備高可用和永續性。
一個分割槽可以有多個副本,這些副本儲存在不同的broker上。每個分割槽的副本中都會有一個作為Leader。當
一個broker失敗時,Leader在這臺broker上的分割槽都會變得不可用,kafka會自動移除Leader,再其他副本中選一個作為新的Leader。在通常情況下,增加分割槽可以提供kafka叢集的吞吐量。然而,也應該意識到叢集的總分割槽數或是單臺伺服器上的分割槽數過多,會增加不可用及延遲的風險。
####分割槽leader選舉
可以預見的是,如果某個分割槽的Leader掛了,那麼其它跟隨者將會進行選舉產生一個新的leader,之後所有的讀寫就會轉移到這個新的Leader上,在kafka中,其不是採用常見的多數選舉的方式進行副本的Leader選舉,而是會在Zookeeper上針對每個T opic維護一個稱為ISR(in-sync replica,已同步的副本)的集合,顯然還有一些副本沒有來得及同步。只有這個ISR列表裡面的才有資格成為leader(先使用ISR裡面的第一個,如果不行依次類推,因為ISR裡面的是同步副本,訊息是最完整且各個節點都是一樣的)。通過ISR,kafka可以容忍的失敗數比較高。
假設某個topic有f+1個副本,kafka可以容忍f個不可用,當然如果全部ISR裡面的副本都不可用,也可以選擇其他可用的副本,只是存在資料的不一致。
####分割槽重新分配
我們往已經部署好的Kafka叢集裡面新增機器是最正常不過的需求,而且新增起來非常地方便,我們需要做
的事是從已經部署好的Kafka節點中複製相應的配置檔案,然後把裡面的
broker id修改成全域性唯一的,最後啟動這個節點即可將它加入到現有Kafka叢集中。但是問題來了,新新增
的Kafka節點並不會自動地分配資料,所以無法分擔叢集的負載,除非我
們新建一個topic。但是現在我們想手動將部分分割槽移到新新增的Kafka節點上,Kafka內部提供了相關的工具
來重新分佈某個topic的分割槽。
具體的實現步驟如下所示:
1、比如某一個主題的分割槽資訊如下所示:
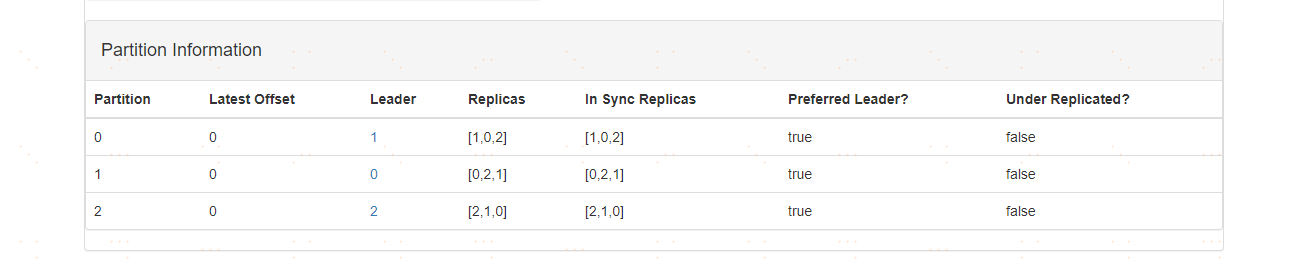
2、給某一個分割槽在新增一個新的分割槽
```shell
bin/kafka-topics.sh --alter --zookeeper 172.19.0.61:2181 --topic demo
--partitions 4
```
新增完畢以後,分割槽的資訊如下所示:
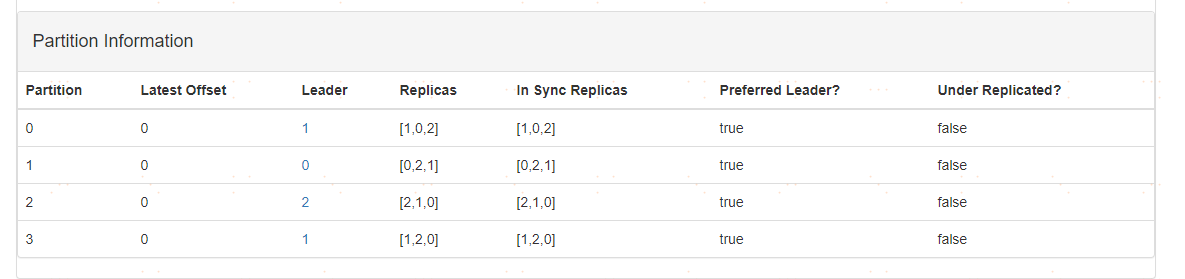
這樣會導致3個Broker上有重新維護了更多的分割槽節點。
3、再次建立一個kafka的容器
```shell
docker run -di --network=host --name=kafka_04 -v
/etc/localtime:/etc/localtime --privileged=true
wurstmeister/kafka:latest /bin/bash
```
檢視itheima主題的分割槽情況,如下所示
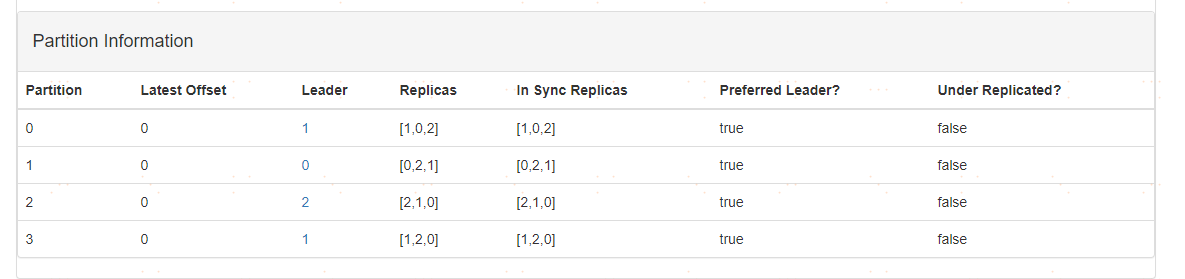
和之前沒有任何的變化。
3、修改叢集配置檔案
```xml
broker.id=3 # 表示broker的編號,如
果叢集中有多個broker,則每個broker的編號需要設定的不同
port=9095 # 埠號
listeners=PLAINTEXT://192.168.23.131:9095 # brokder對外提供的服
務入口地址
log.dirs=/tmp/kafka-logs # 設定存放訊息日誌檔案
的地址
zookeeper.connect=172.19.0.61:2181,172.19.0.62:2181,172.19.0.63:2181
# Kafka所需Zookeeper叢集地址,Zookeeper和Kafka都安裝本機
```
4、重新分配
現在我們需要將原先分佈在broker 1-3節點上的分割槽重新分佈到broker 1-4節點上,藉助kafkareassignpartitions.sh工具生成reassign plan,不過我們先得按照要求定義一個檔案,裡面說明哪些topic需要重新分割槽,檔案內容如下:
```json
demo@Server-node:/mnt/d/kafka-cluster/kafka-1$ cat reassign.json
{"topics":[{"topic":"demo"}],
"version":1
}
```
然後使用 kafka-reassign-partitions.sh 工具生成reassign plan
```shell
bin/kafka-reassign-partitions.sh --zookeeper 172.19.0.61:2181 --topics-to-move-json-file
reassign.json --broker-list "0,1,2,3" --generate
```
命令會輸出兩個字串,如下所示:
```shell
Current partition replica assignment
{"version":1,"partitions":[{"topic":"demo","partition":2,"replicas":
[2,1,0],"log_dirs":["any","any","any"]},
{"topic":"demo","partition":1,"replicas":[0,2,1],"log_dirs":
["any","any","any"]},{"topic":"itheima","partition":0,"replicas":
[1,0,2],"log_dirs":["any","any","any"]},
{"topic":"demo","partition":3,"replicas":[1,2,0],"log_dirs":
["any","any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"demo","partition":2,"replicas":
[3,1,2],"log_dirs":["any","any","any"]},
{"topic":"demo","partition":1,"replicas":[2,0,1],"log_dirs":
["any","any","any"]},{"topic":"demo","partition":3,"replicas":
[0,2,3],"log_dirs":["any","any","any"]},
{"topic":"demo","partition":0,"replicas":[1,3,0],"log_dirs":
["any","any","any"]}]}
```
第一個JSON內容為當前的分割槽副本分配情況,第二個為重新分配的候選方案,注意這裡只是生成一份可行性的方案,並沒有真正執行重分配的動作。
我們將第二個JSON內容儲存到名為result.json檔案裡面(檔名不重要,檔案格式也不一定要以json為結尾,只要保證內容是json即可),然後執行這些reassign plan。如下所示:
執行分配策略
```shell
bin/kafka-reassign-partitions.sh --zookeeper 172.19.0.61:2181 --reassignment-json-file result.json --execute
```
執行完畢以後,看出分割槽資訊:
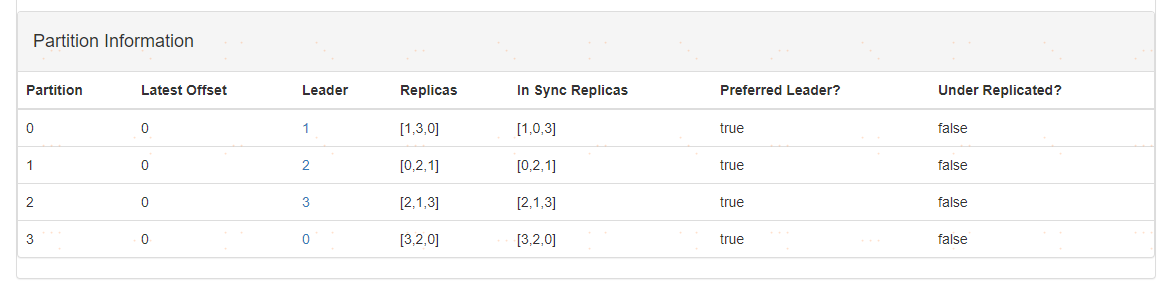
####修改副本因子
**場景**
修改副本因子的使用場景也很多,比如在建立主題時填寫了錯誤的副本因子數而需要修改,再比如執行一段時間之後想要通過增加副本因子數來提高容錯性和可靠性。修改副本因此也是通過kafka-reassign-partitions.sh指令碼實現的。仔細觀察我們剛才對itheima進行分割槽重新分配以後的結果:
```shell
{"version":1,"partitions":[{"topic":"demo","partition":2,"replicas":
[3,1,2],"log_dirs":["any","any","any"]},
{"topic":"demo","partition":1,"replicas":[2,0,1],"log_dirs":
["any","any","any"]},{"topic":"itheima","partition":3,"replicas":
[0,2,3],"log_dirs":["any","any","any"]},
{"topic":"demo","partition":0,"replicas":[1,3,0],"log_dirs":
["any","any","any"]}]}
```
通過觀察JSON內容裡的replicas都是3個副本。我們可以更改指定分割槽數的副本,具體的實現如下所示:
1、建立一個json檔案,定義指定分割槽的副本資料
```json
{
"version":1,
"partitions":[
{"topic":"demo","partition":2,"replicas":[0,1]}
]
}
```
2、然後執行指令碼檔案
```shell
bash-4.4# bin/kafka-reassign-partitions.sh --zookeeper 172.19.0.61:2181
--reassignment-json-file replication-factor.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"demo","partition":2,"replicas":
[3,1,2],"log_dirs":["any","any","any"]},
{"topic":"demo","partition":1,"replicas":[2,0,1],"log_dirs":
["any","any","any"]},{"topic":"itheima","partition":0,"replicas":
[1,3,0],"log_dirs":["any","any","any"]},
{"topic":"demo","partition":3,"replicas":[0,2,3],"log_dirs":
["any","any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
```
執行完畢以後,我們再次看出demo的分割槽副本情況,如下所示:
![](https://img2020.cnblogs.com/blog/874710/202101/874710-20210118101907430-5753011