
訊息中介軟體學習總結(6)——RocketMQ之RocketMQ大資料暢想
剛剛過去的雙十一,阿里自主研發的訊息中介軟體RocketMQ,充分展現了它的低延遲特性,大部分訊息請求落在2ms內,慢請求也都落在20ms內,這無疑給追求快速響應的線上交易系統(OLTP)帶去了福音。 也是在今年11月份,RocketMQ進入Apache孵化。這款最初設計來為淘寶交易系統非同步解耦、削峰填谷的訊息中介軟體,開始走出國門,為世界上的使用者提供服務。自然地,RocketMQ將來不僅僅只服務於線上系統,對於離線或半離線系統,尤其是大資料領域,RocketMQ也將為其綻放自己的光彩。
Kafka大資料的殺手鐗
談到大資料領域內的訊息傳輸,則繞不開Kafka。這款為大資料而生的訊息中介軟體,以其百萬級TPS的吞吐量名聲大噪,迅速成為大資料領域的寵兒,在資料採集、傳輸、儲存的過程中發揮著舉足輕重的作用,被LinkedIn,Uber, Twitter, Netflix等大公司所採納,而storm,spark,flink等大資料流處理或批處理平臺都有Kafka的相關外掛支援。 那麼,Kafka的百萬級TPS是如何做到的呢? 有很多相關的分析,比如非同步IO,PageCache,非同步刷盤,消費過程零拷貝,Batch等,這些都對,但是沒有一個直觀的說明,這眾多因素中,哪一個才是殺手鐗呢? 筆者對這個問題進行了一些探究,在揭曉之前,請看下圖:
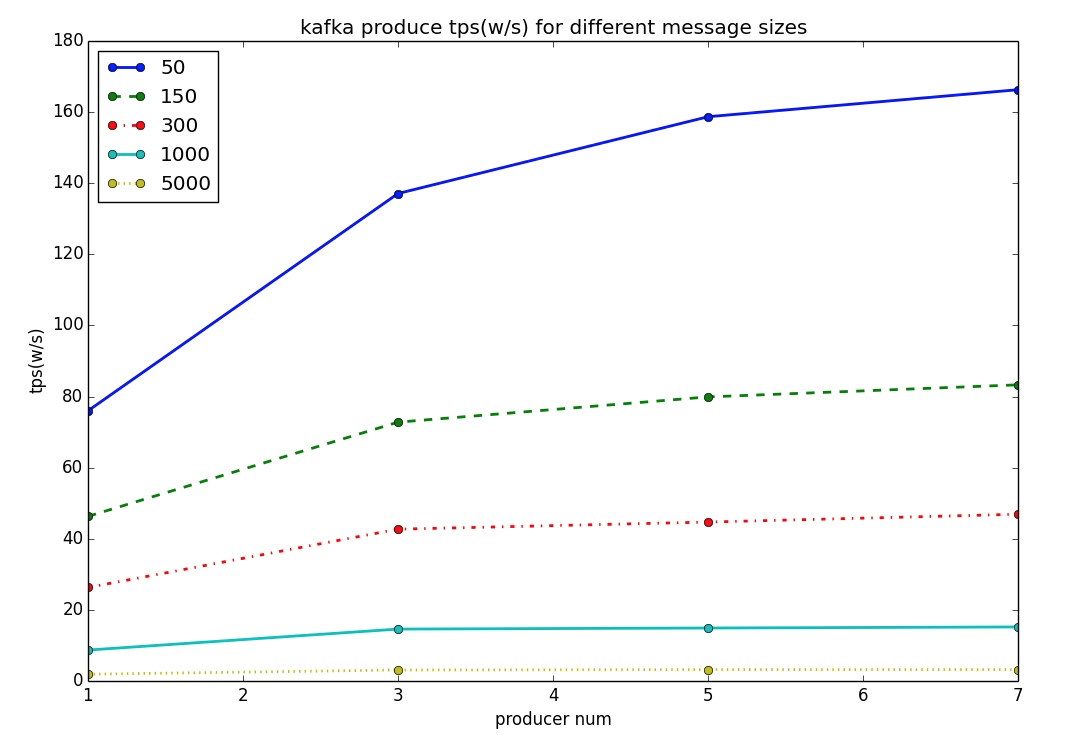
注:一臺物理機部署Kafka,另一臺物理機施加壓力,每個producer非同步傳送,非同步統計結果;本文所涉及的機器配置都是24核48G記憶體SSD盤
從上圖可以看出,當單個訊息體為50位元組時,kafka單機的吞吐量確實表現出色,能達到百萬級。可是當單個訊息體為5k位元組時,TPS極速下降,只有大約3萬多,少了兩個數量級。 對此,可能有人會說那是因為網絡卡打滿了,還有就是因為訊息體變大,每次能batch的數量變少了,導致整體TPS下降。 都有可能,筆者測試時網絡卡雖然沒有打滿,卻確實是負載比較高了。因此,為了排除因素,筆者還做了另外一個測試如下:
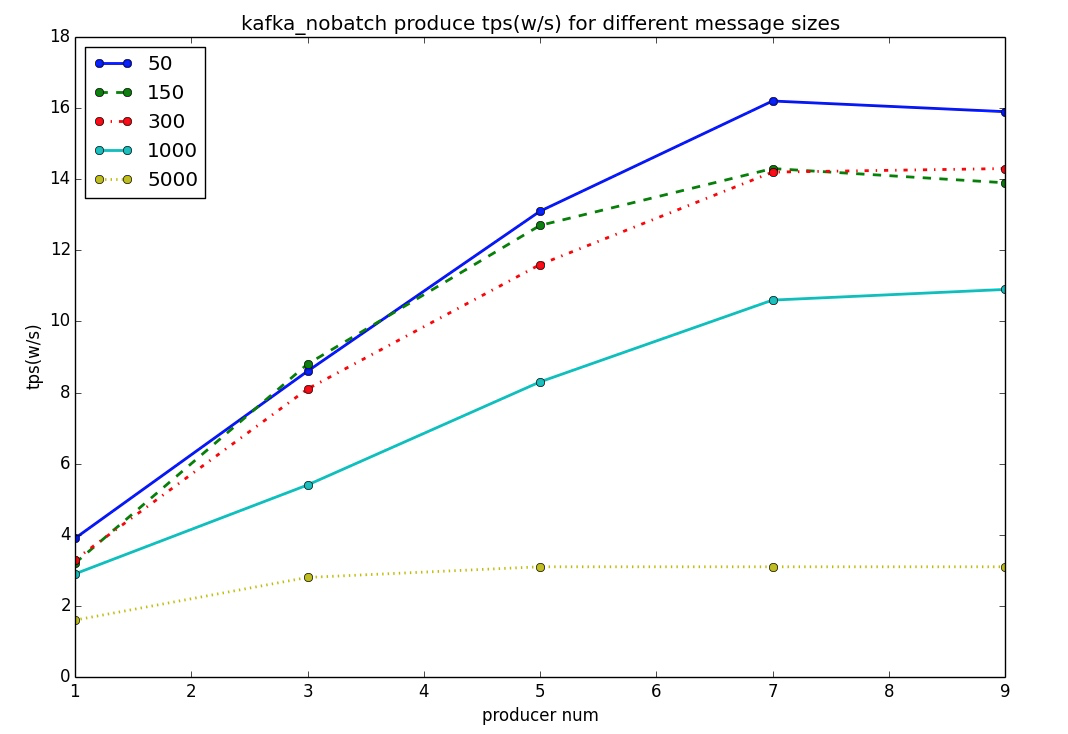
上圖可以清晰地看出,50位元組時,Kafka no batch(batch size設為1)時的吞吐量只有15萬多,只有啟用batch時的十分之一,而RocketMQ也可以很輕鬆地達到這個水平。 至此,可以直觀地充分說明,Kafka達到百萬級TPS的殺手鐗就是batch
RocketMQ大資料的無限潛力
到這裡,自然會有一個疑問,如果把batch特性用到RocketMQ中,效果會如何呢? 按照上面的結論進行推測,batch特性勢必也能大大提高RocketMQ的吞吐量。但如果要實踐證明,需要做一些工作。 為了直觀地證明batch對於RocketMQ的功效,筆者在Kafka Broker做了一層代理,大致結構圖如下:
Kafka Broker收到Kafka Client的Batch Data後,不儲存在本地,而是把訊息轉發到RocketMQ,等待RocketMQ返回結果後,再返回給Kafka Client。 筆者用一臺物理機部署Kafka Broker作為Proxy,同時用另一臺同樣配置的物理機部署RocketMQ作為儲存,然後用另一臺物理機來對Proxy進行施加壓力,結果如下圖:
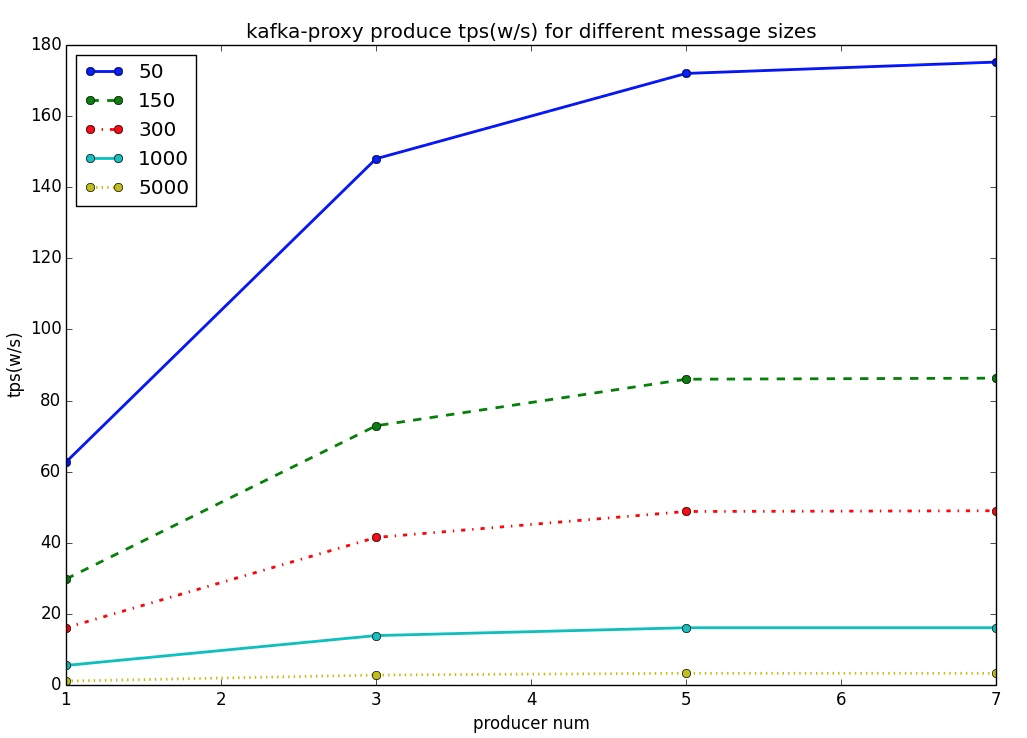
這個結果與上面關於Kafka的結果相互印證,既證明了Kakfa大資料的殺手鐗在於batch,同時也展現了RocketMQ在大資料領域的無限潛力,並不遜色於Kafka。
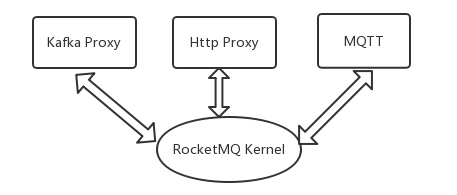
Proxy與RocketMQ Kernel
RocketMQ最初是為交易系統而生,現在也不會忘記這一初心,但其也絕不會固步自封。面對越來越多的來自各個領域的使用者,他們有著各自不一樣的複雜應用場景,這給RocketMQ帶來了挑戰,也帶來了機遇。未來的RocketMQ會繼續保持初心,維護自己Kernel的本色,但也會增加一些外圍功能,以適應各種不同的場景,如面向大資料的Kakfa Proxy,面向物聯網的MQTT,面向REST的Http Proxy。
最後,這一切只是開始,更多的想象空間,需要大家一起來創造。