
大型Java進階專題(十一) 深入理解JVM (下)
阿新 • • 發佈:2020-08-08
##前言
前面我們瞭解了JVM相關的理論知識,這章節主要從實戰方面,去解讀JVM。
## 類載入機制
Java原始碼經過編譯器編譯成位元組碼之後,最終都需要載入到虛擬機器之後才能執行。虛擬機器把描述類的資料從
Class 檔案載入到記憶體,並對資料進行校驗、轉換解析和初始化,最終形成可以被虛擬機器直接使用的Java 型別,這就是虛擬機器的類載入機制。
### 類載入時機
一個型別從被載入到虛擬機器記憶體中開始,到卸載出記憶體為止,它的整個生命週期將會經歷載入(Loading)、驗證(Verification)、準備(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和解除安裝(Unloading)七個階段,其中驗證、準備、解析三個部分統稱為連線(Linking)。這七個階段的發生順序下圖所示。
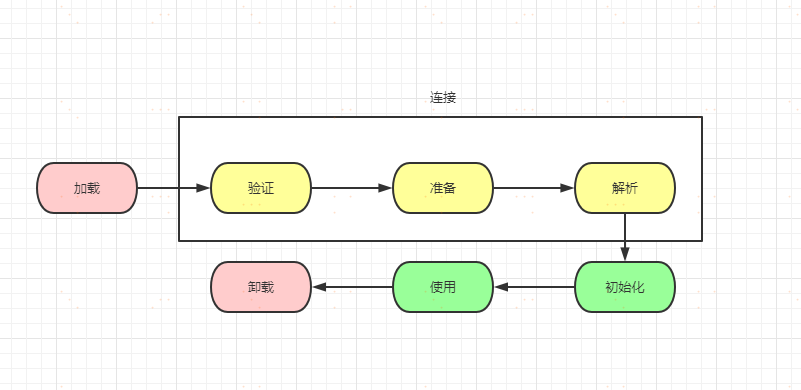
上圖中,載入、驗證、準備、初始化和解除安裝這五個階段的順序是確定的,型別的載入過程必須按照這種順序按部就班地開始,而解析階段則不一定:它在某些情況下可以在初始化階段之後再開始,這是為了支援Java語言的執行時繫結特性(也稱為動態繫結或晚期繫結)。
關於在什麼情況下需要開始類載入過程的第一個階段“載入”,《Java虛擬機器規範》中並沒有進行強制約束,這點可以交給虛擬機器的具體實現來自由把握。
但是對於初始化階段,《Java虛擬機器規範》則是嚴格規定了有且只有六種情況必須立即對類進行“初始化”(而加
載、驗證、準備自然需要在此之前開始):
- 遇到new、getstatic、putstatic 或invokestatic 這4 條位元組碼指令;
- 使用java.lang.reflect 包的方法對類進行反射呼叫的時候;
- 當初始化一個類的時候,發現其父類還沒有進行初始化的時候,需要先觸發其父類的初始化;
- 當虛擬機器啟動時,使用者需要指定一個要執行的主類,虛擬機器會先初始化這個類;
- 當使用JDK 1.7 的動態語言支援時,如果一個java.lang.invoke.MethodHandle 例項最後的解析結果
- REF_getStatic、REF_putStatic、REF_invokeStatic 的方法控制代碼,並且這個方法控制代碼所對應的類沒有初始化。
- 當一個介面中定義了JDK 8新加入的預設方法(被default關鍵字修飾的介面方法)時,如果有這個介面的實現。類發生了初始化,那該介面要在其之前被初始化。
對於這六種會觸發型別進行初始化的場景,《Java虛擬機器規範》中使用了一個非常強烈的限定語——“有且只有”,這六種場景中的行為稱為對一個型別進行主動引用。除此之外,所有引用型別的方式都不會觸發初始化,稱為被動引用。
比如如下幾種場景就是被動引用:
- 通過子類引用父類的靜態欄位,不會導致子類的初始化;
- 通過陣列定義來引用類,不會觸發此類的初始化;
- 常量在編譯階段會存入呼叫類的常量池中,本質上並沒有直接引用到定義常量的類,因此不會觸發定義常量的類的初始化;
### 類載入過程
#### 載入
在載入階段,Java虛擬機器需要完成以下三件事情:
通過一個類的全限定名來獲取定義此類的二進位制位元組流。
將這個位元組流所代表的靜態儲存結構轉化為方法區的執行時資料結構。
在記憶體中生成一個代表這個類的java.lang. Class物件,作為方法區這個類的各種資料的訪問入口。
#### 驗證
驗證是連線階段的第一步,這一階段的目的是確保Class檔案的位元組流中包含的資訊符合《Java虛擬機器規範》的全部約束要求,保證這些資訊被當作程式碼執行後不會危害虛擬機器自身的安全。
驗證階段大致上會完成下面4 個階段的檢驗動作:
- **檔案格式驗證**
第一階段要驗證位元組流是否符合Class 檔案格式的規範,並且能夠被當前版本的虛擬機器處理。驗證點主要包括:
1. 是否以魔數0xCAFEBABE 開頭;
2. 主、次版本號是否在當前虛擬機器處理範圍之內;
3. 常量池的常量中是否有不被支援的常量型別;
4. Class 檔案中各個部分及檔案本身是否有被刪除的或者附加的其它資訊等等。
- **元資料驗證**
第二階段是對位元組碼描述的資訊進行語義分析,以保證其描述的資訊符合Java 語言規範的要求,這個階段的驗證點包括:
1. 這個類是否有父類;
2. 這個類的父類是否繼承了不允許被繼承的類;
3. 如果這個類不是抽象類,是否實現了其父類或者介面之中要求實現的所有方法;
4. 類中的欄位、方法是否與父類產生矛盾等等。
- **位元組碼驗證**
第三階段是整個驗證過程中最複雜的一個階段,主要目的是通過資料流和控制流分析,確定程式語義是合法的、符合邏輯的。
- **符號引用驗證**
1. 最後一個階段的校驗發生在虛擬機器將符號引用轉化為直接引用的時候,這個轉化動作將在連線的第三階段--解析階段中發生。
2. 符號引用驗證可以看做是對類自身以外(常量池中的各種符號引用)的各類資訊進行匹配性校驗,通俗來說就是,該類是否缺少或者被禁止訪問它依賴的某些外部類、方法、欄位等資源。
#### 準備
準備階段是正式為類變數分配記憶體並設定類變數初始值的階段。
#### 解析
解析階段是虛擬機器將常量池內的符號引用替換為直接引用的過程。
#### 初始化
類初始化階段是類載入過程中的最後一步,前面的類載入過程中,除了在載入階段使用者應用程式可以通過自定義類載入器參與之外,其餘動作完全是由虛擬機器主導和控制的。
到了初始化階段,才真正開始執行類中定義的Java 程式程式碼。
### 類載入器
類載入器雖然只用於實現類的載入動作,但它在Java程式中起到的作用卻遠超類載入階段。
對於任意一個類,都必須由載入它的類載入器和這個類本身一起共同確立其在Java虛擬機器中的唯一性,每一個類載入器,都擁有一個獨立的類名稱空間。
這句話可以表達得更通俗一些:比較兩個類是否“相等”,只有在這兩個類是由同一個類載入器載入的前提下才有意義,否則,即使這兩個類來源於同一個Class檔案,被同一個Java虛擬機器載入,只要載入它們的類載入器不同,那這兩個類就必定不相等。
#### 雙親委派模型
從Java 虛擬機器的角度來講,只存在兩種不同的類載入器:一種是啟動類載入器(Bootstrap ClassLoader),這個類載入器使用C++ 來實現,是虛擬機器自身的一部分;另一種就是所有其他的類載入器,這些類載入器都由Java 來實現,獨立於虛擬機器外部,並且全都繼承自抽象類 java.lang.ClassLoader 。
從Java 開發者的角度來看,類載入器可以劃分為:
- **啟動類載入器(Bootstrap ClassLoader)**:這個類載入器負責將存放在\lib 目錄中的類庫載入到虛擬機器記憶體中。啟動類載入器無法被Java 程式直接引用,使用者在編寫自定義類載入器時,如果需要把載入請求委派給啟動類載入器,那直接使用null 代替即可;
- **擴充套件類載入器(Extension ClassLoader)**:這個類載入器由 sun.misc.Launcher$ExtClassLoader 實現,它負責載入\lib\ext 目錄中,或者被java.ext.dirs 系統變數所指定的路徑中的所有類庫,開發者可以直接使用擴充套件類載入器;
- **應用程式類載入器(Application ClassLoader)**:這個類載入器由 sun.misc.Launcher$AppClassLoader 實現。 getSystemClassLoader() 方法返回的就是這個類載入器,因此也被稱為系統類載入器。它負責載入使用者類路徑(ClassPath)上所指定的類庫。開發者可以直接使用這個類載入器,如果應用程式中沒有自定義過自己的類載入器,一般情況下這個就是程式中預設的類載入器。
我們的應用程式都是由這3 種類載入器互相配合進行載入的,在必要時還可以自己定義類載入器。它們的關係如下圖所示:
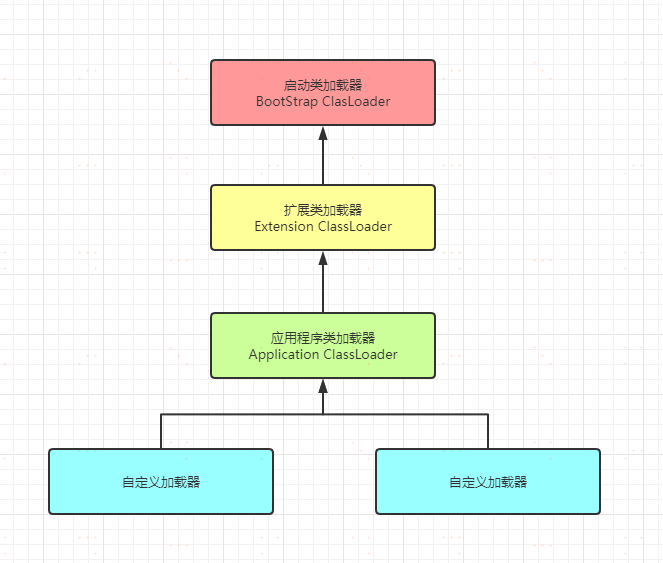
雙親委派模型要求除了頂層的啟動類載入器外,其餘的類載入器都應有自己的父類載入器。
雙親委派模型的工作過程是:
- 如果一個類載入器收到了類載入的請求,它首先不會自己去嘗試載入這個類
- 而是把這個請求委派給父類載入器去完成,每一個層次的類載入器都是如此
- 因此所有的載入請求最終都應該傳送到最頂層的啟動類載入器中
- 只有當父載入器反饋自己無法完成這個載入請求(它的搜尋範圍中沒有找到所需的類)時,子載入器才會嘗試自己去完成載入。
這樣做的好處就是Java 類隨著它的類載入器一起具備了一種帶有優先順序的層次關係。例如java.lang. Object,它放在rt.jar 中,無論哪一個類載入器要載入這個類,最終都是委派給處於模型頂端的啟動類載入器來載入,因此Object 類在程式的各種類載入器環境中都是同一個類。
相反,如果沒有使用雙親委派模型,由各個類載入器自行去載入的話,如果使用者自己編寫了一個稱為java.lang. Object 的類,並放在程式的ClassPath 中,那系統中將會出現多個不同的Object 類,Java 型別體系中最基本的行為也就無法保證了。
雙親委派模型對於保證Java程式的穩定運作極為重要,但它的實現卻異常簡單,用以實現雙親委派的程式碼只有短短十餘行,全部集中在java.lang. ClassLoader的loadClass()方法之中:
```java
protected synchronized Class loadClass(String name, boolean resolve)
throws ClassNotFoundException {
// 首先,檢查請求的類是不是已經被載入過
Class c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// 如果父類丟擲 ClassNotFoundException 說明父類載入器無法完成載入
}
if (c == null) {
// 如果父類載入器無法載入,則呼叫自己的 findClass 方法來進行類載入
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
```
## JVM調優實戰
### JVM執行引數
在jvm中有很多的引數可以進行設定,這樣可以讓jvm在各種環境中都能夠高效的執行。絕大部分的引數保持預設即可。
#### 三種引數型別
- 標準引數
- -help
- -version
- -X引數(非標準引數)
- -Xint
- -Xcomp
- XX引數(使用率較高)
- -XX:newSize
- -XX:+UseSerialGC
#### -X引數
jvm的-X引數是非標準引數,在不同版本的jvm中,引數可能會有所不同,可以通過java -X檢視非標準引數。
#### -XX引數
-XX引數也是非標準引數,主要用於jvm的調優和debug操作。
-XX引數的使用有2種方式,一種是boolean型別,一種是非boolean型別:
- boolean型別
- 格式:-XX:[+-] 表示啟用或禁用屬性
- 如:-XX:+DisableExplicitGC 表示禁用手動呼叫gc操作,也就是說呼叫System.gc()無效
- 非boolean型別
- 格式:-XX:= 表示屬性的值為
- 如:-XX:NewRatio=4 表示新生代和老年代的比值為1:4
#### -Xms和-Xmx引數
-Xms與-Xmx分別是設定jvm的堆記憶體的初始大小和最大大小。
-Xmx2048m:等價於-XX:MaxHeapSize,設定JVM最大堆記憶體為2048M。
-Xms512m:等價於-XX:InitialHeapSize,設定JVM初始堆記憶體為512M。
適當的調整jvm的記憶體大小,可以充分利用伺服器資源,讓程式跑的更快。
示例:
****
```shell
[root@node01 test]# java -Xms512m -Xmx2048m TestJVM
itcast
```
#### jstat
jstat命令可以檢視堆記憶體各部分的使用量,以及載入類的數量。命令的格式如下:
jstat [-命令選項] [vmid] [間隔時間/毫秒] [查詢次數]
**檢視class載入統計**
```shell
F:\t>jstat -class 12076
Loaded Bytes Unloaded Bytes Time
5962 10814.2 0 0.0 3.75
```
說明:
Loaded:載入class的數量
Bytes:所佔用空間大小
Unloaded:未載入數量
Bytes:未載入佔用空間
Time:時間
**檢視編譯統計**
```shell
F:\t>jstat -compiler 12076
Compiled Failed Invalid Time FailedType FailedMethod
3115 0 0 3.43 0
```
說明:
Compiled:編譯數量。
Failed:失敗數量
Invalid:不可用數量
Time:時間
FailedType:失敗型別
FailedMethod:失敗的方法
**垃圾回收統計**
```shell
F:\t>jstat -gc 12076
S0C S1C S0U S1U EC EU OC OU MC MU
CCSC CCSU YGC YGCT FGC FGCT GCT
3584.0 6656.0 3412.1 0.0 180224.0 89915.4 61440.0 5332.1 27904.0 2626
7.3 3840.0 3420.8 6 0.036 1 0.026 0.062
#也可以指定列印的間隔和次數,每1秒中列印一次,共列印5次
F:\t>jstat -gc 12076 1000 5
S0C S1C S0U S1U EC EU OC OU MC MU
CCSC CCSU YGC YGCT FGC FGCT GCT
3584.0 6656.0 3412.1 0.0 180224.0 89915.4 61440.0 5332.1 27904.0 2626
7.3 3840.0 3420.8 6 0.036 1 0.026 0.062
3584.0 6656.0 3412.1 0.0 180224.0 89915.4 61440.0 5332.1 27904.0 2626
7.3 3840.0 3420.8 6 0.036 1 0.026 0.062
3584.0 6656.0 3412.1 0.0 180224.0 89915.4 61440.0 5332.1 27904.0 2626
7.3 3840.0 3420.8 6 0.036 1 0.026 0.062
3584.0 6656.0 3412.1 0.0 180224.0 89915.4 61440.0 5332.1 27904.0 2626
7.3 3840.0 3420.8 6 0.036 1 0.026 0.062
3584.0 6656.0 3412.1 0.0 180224.0 89915.4 61440.0 5332.1 27904.0 2626
7.3 3840.0 3420.8 6 0.036 1 0.026 0.062
```
說明:
S0C:第一個Survivor區的大小(KB)
S1C:第二個Survivor區的大小(KB)
S0U:第一個Survivor區的使用大小(KB)
S1U:第二個Survivor區的使用大小(KB)
EC:Eden區的大小(KB)
EU:Eden區的使用大小(KB)
OC:Old區大小(KB)
OU:Old使用大小(KB)
MC:方法區大小(KB)
MU:方法區使用大小(KB)
CCSC:壓縮類空間大小(KB)
CCSU:壓縮類空間使用大小(KB)
YGC:年輕代垃圾回收次數
YGCT:年輕代垃圾回收消耗時間
FGC:老年代垃圾回收次數
FGCT:老年代垃圾回收消耗時間
GCT:垃圾回收消耗總時間
###Jmap的使用以及記憶體溢位分析
前面通過jstat可以對jvm堆的記憶體進行統計分析,而jmap可以獲取到更加詳細的內容,如:記憶體使用情況的彙總、對記憶體溢位的定位與分析。
#### 檢視記憶體使用情況
```shell
[root@node01 ~]# jmap -heap 6219
Attaching to process ID 6219, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.141-b15
using thread-local object allocation.
Parallel GC with 2 thread(s)
Heap Configuration: #堆記憶體配置資訊
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 488636416 (466.0MB)
NewSize = 10485760 (10.0MB)
MaxNewSize = 162529280 (155.0MB)
OldSize = 20971520 (20.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage: # 堆記憶體的使用情況
PS Young Generation #年輕代
Eden Space:
capacity = 123731968 (118.0MB)
used = 1384736 (1.320587158203125MB)
free = 122347232 (116.67941284179688MB)
1.1191416594941737% used
From Space:
capacity = 9437184 (9.0MB)
used = 0 (0.0MB)
free = 9437184 (9.0MB)
0.0% used
To Space:
capacity = 9437184 (9.0MB)
used = 0 (0.0MB)
free = 9437184 (9.0MB)
0.0% used
PS Old Generation #年老代
capacity = 28311552 (27.0MB)
used = 13698672 (13.064071655273438MB)
free = 14612880 (13.935928344726562MB)
48.38545057508681% used
13648 interned Strings occupying 1866368 bytes.
```
#### 檢視記憶體中物件數量及大小
```shell
#檢視所有物件,包括活躍以及非活躍的
jmap -histo | more
#檢視活躍物件
jmap -histo:live | more
[root@node01 ~]# jmap -histo:live 6219 | more
num #instances #bytes class name
----------------------------------------------1: 37437 7914608 [C
2: 34916 837984 java.lang.String
3: 884 654848 [B
4: 17188 550016 java.util.HashMap$Node
5: 3674 424968 java.lang.Class
6: 6322 395512 [Ljava.lang.Object;
7: 3738 328944 java.lang.reflect.Method
8: 1028 208048 [Ljava.util.HashMap$Node;
9: 2247 144264 [I
10: 4305 137760 java.util.concurrent.ConcurrentHashMap$Node
11: 1270 109080 [Ljava.lang.String;
12: 64 84128 [Ljava.util.concurrent.ConcurrentHashMap$Node;
13: 1714 82272 java.util.HashMap
14: 3285 70072 [Ljava.lang.Class;
15: 2888 69312 java.util.ArrayList
16: 3983 63728 java.lang.Object
17: 1271 61008 org.apache.tomcat.util.digester.CallMethodRule
18: 1518 60720 java.util.LinkedHashMap$Entry
19: 1671 53472 com.sun.org.apache.xerces.internal.xni.QName
20: 88 50880 [Ljava.util.WeakHashMap$Entry;
21: 618 49440 java.lang.reflect.Constructor
22: 1545 49440 java.util.Hashtable$Entry
23: 1027 41080 java.util.TreeMap$Entry
24: 846 40608 org.apache.tomcat.util.modeler.AttributeInfo
25: 142 38032 [S
26: 946 37840 java.lang.ref.SoftReference
27: 226 36816 [[C
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
#物件說明
B byte
C char
D double
F float
I int
J long
Z boolean
[ 陣列,如[I表示int[]
[L+類名 其他物件
```
#### 將記憶體使用情況dump到檔案中
```shell
#用法:
jmap -dump:format=b,file=dumpFileName
#示例
jmap -dump:format=b,file=/tmp/dump.dat 6219
```

可以看到已經在/tmp下生成了dump.dat的檔案。
#### 通過jhat對dump檔案進行分析
在上一小節中,我們將jvm的記憶體dump到檔案中,這個檔案是一個二進位制的檔案,不方便檢視,這時我們可以藉助於jhat工具進行檢視。
```shell
#用法:
jhat -port
#示例:
[root@node01 tmp]# jhat -port 9999 /tmp/dump.dat
Reading from /tmp/dump.dat...
Dump file created Mon Sep 10 01:04:21 CST 2018
Snapshot read, resolving...
Resolving 204094 objects...
Chasing references, expect 40 dots........................................
Eliminating duplicate references........................................
Snapshot resolved.
Started HTTP server on port 9999
Server is ready.
```
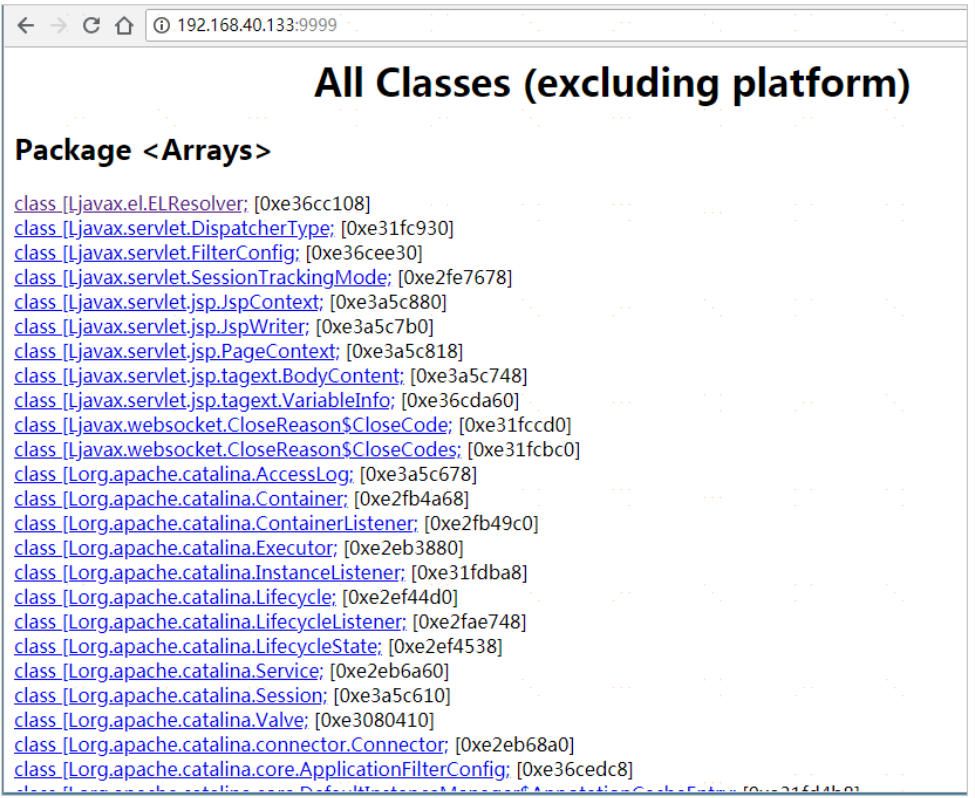
開啟瀏覽器進行訪問:http://192.168.40.133:9999/
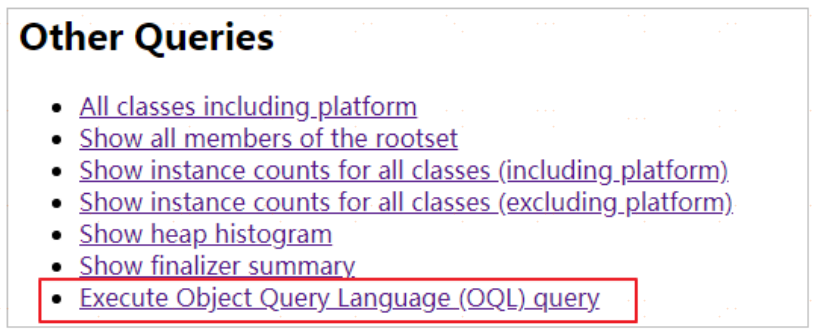
在最後由OQL查詢功能
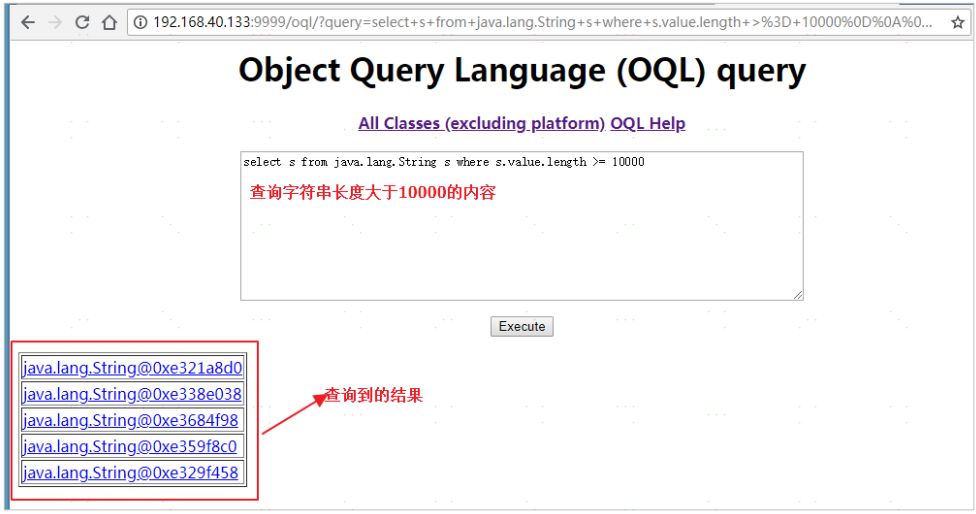
### Jmp使用以及記憶體溢位分析
#### 使用MAT對記憶體溢位的定位與分析
記憶體溢位在實際的生產環境中經常會遇到,比如,不斷的將資料寫入到一個集合中,出現了死迴圈,讀取超大的檔案等等,都可能會造成記憶體溢位。
如果出現了記憶體溢位,首先我們需要定位到發生記憶體溢位的環節,並且進行分析,是正常還是非正常情況,如果是正常的需求,就應該考慮加大記憶體的設定,如果是非正常需求,那麼就要對程式碼進行修改,修復這個bug。首先,我們得先學會如何定位問題,然後再進行分析。如何定位問題呢,我們需要藉助於jmap與MAT工具進行定位分析。
接下來,我們模擬記憶體溢位的場景。
#### 模擬記憶體溢位
編寫程式碼,向List集合中新增100萬個字串,每個字串由1000個UUID組成。如果程式能夠正常執行,最後列印ok。
```java
public class TestJvmOutOfMemory {
public static void main(String[] args) {
List