
Java進階專題(十七) 系統快取架構設計 (上)
阿新 • • 發佈:2020-11-26
# 前言
我們將先從Redis、Nginx+Lua等技術點出發,瞭解快取應用的場景。通過使用快取相關技術,解決高併發的業務場景案例,來深入理解一套成熟的企業級快取架構如何設計的。本文Redis部分總結於蔣德鈞老師的《Redis核心技術與實戰》。
# Redis基礎
##簡介
Redis是一個開源的使用ANSI C語言編寫、遵守BSD協議、支援網路、可基於記憶體亦可持久化的日誌型、Key-Value資料庫,並提供多種語言的API。
它通常被稱為資料結構伺服器,因為值(value)可以是 字串(String), 雜湊(Hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)等型別。
Redis 與其他 key - value 快取產品有以下三個特點:
- Redis支援資料的持久化,可以將記憶體中的資料儲存在磁碟中,重啟的時候可以再次載入進行使用。
- Redis不僅僅支援簡單的key-value型別的資料,同時還提供list,set,zset,hash等資料結構的儲存。
- Redis支援資料的備份,即master-slave模式的資料備份。
**優勢**
- 效能極高 – Redis能讀的速度是110000次/s,寫的速度是81000次/s 。
- 豐富的資料型別 – Redis支援二進位制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 資料型別操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要麼成功執行要麼失敗完全不執行。單個操作是原子性的。多個操作也支援事務,即原子性,通過MULTI和EXEC指令包起來。
- 豐富的特性 – Redis還支援 publish/subscribe, 通知, key 過期等等特性。
##資料型別
###String(字串)
string 是 redis 最基本的型別,你可以理解成與 Memcached 一模一樣的型別,一個 key 對應一個 value。
string 型別是二進位制安全的。意思是 redis 的 string 可以包含任何資料。比如jpg圖片或者序列化的物件。
string 型別是 Redis 最基本的資料型別,string 型別的值最大能儲存 512MB。
```shell
redis 127.0.0.1:6379> SET runoob "laowang"
OK
redis 127.0.0.1:6379> GET runoob
"laowang"
```
###Hash(雜湊)
Redis hash 是一個鍵值(key=>value)對集合。
Redis hash 是一個 string 型別的 field 和 value 的對映表,hash 特別適合用於儲存物件。
每個 hash 可以儲存 2^32 -1 鍵值對(40多億)。
```shell
redis 127.0.0.1:6379> HMSET runoob field1 "Hello" field2 "World"
"OK"
redis 127.0.0.1:6379> HGET runoob field1
"Hello"
redis 127.0.0.1:6379> HGET runoob field2
"World"
```
###List(列表)
Redis 列表是簡單的字串列表,按照插入順序排序。你可以新增一個元素到列表的頭部(左邊)或者尾部(右邊)。
列表最多可儲存 2^32 - 1 元素 (4294967295, 每個列表可儲存40多億)。
```shell
redis 127.0.0.1:6379> lpush runoob redis
(integer) 1
redis 127.0.0.1:6379> lpush runoob mongodb
(integer) 2
redis 127.0.0.1:6379> lpush runoob rabitmq
(integer) 3
redis 127.0.0.1:6379> lrange runoob 0 10
1) "rabitmq"
2) "mongodb"
3) "redis"
```
###Set(集合)
Redis 的 Set 是 string 型別的無序集合。
集合是通過**雜湊表**實現的,所以新增,刪除,查詢的複雜度都是 O(1)。
**sadd 命令** :新增一個 string 元素到 key 對應的 set 集合中,成功返回 1,如果元素已經在集合中返回 0。
集合中最大的成員數為 2^32 - 1(4294967295, 每個集合可儲存40多億個成員)。
```shell
redis 127.0.0.1:6379> DEL runoob
redis 127.0.0.1:6379> sadd runoob redis
(integer) 1
redis 127.0.0.1:6379> sadd runoob mongodb
(integer) 1
redis 127.0.0.1:6379> sadd runoob rabitmq
(integer) 1
redis 127.0.0.1:6379> sadd runoob rabitmq
(integer) 0
redis 127.0.0.1:6379> smembers runoob
1) "redis"
2) "rabitmq"
3) "mongodb"
```
###zset(sorted set:有序集合)
Redis zset 和 set 一樣也是string型別元素的集合,且不允許重複的成員。
不同的是每個元素都會關聯一個double型別的分數。redis正是通過分數來為集合中的成員進行從小到大的排序。
zset的成員是唯一的,但分數(score)卻可以重複。
**zadd 命令** :新增元素到集合,元素在集合中存在則更新對應score
```shell
redis 127.0.0.1:6379> zadd runoob 0 redis
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 mongodb
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 rabitmq
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 rabitmq
(integer) 0
redis 127.0.0.1:6379> > ZRANGEBYSCORE runoob 0 1000
1) "mongodb"
2) "rabitmq"
3) "redis"
```
# Redis深入:帶著問題出發?
## 如果讓你設計一個KV資料庫,該如何設計
對這個問題的思考,將有助於我們從整體架構上去學習Redis。
假設現在我們已經設計好了一個KV資料庫,首先如果我們要使用,是不是得有入口,我們是通過動態連結庫還是通過網路socket對外提供訪問入口,這就涉及到了**訪問模組**。Redis就是通過
通過訪問模組訪問KV資料庫之後,我們的資料儲存在哪裡?為了保證訪問的高效能,我們選在儲存在記憶體中,這又需要有**儲存模組**。存在記憶體中的資料,雖然訪問速度快,但存在的的問題就是斷電後,無法恢復資料,所以我們還需要支援**持久化操作**。
有了儲存模組,我們還需要考慮,資料是以什麼樣的形式儲存?怎樣設計才能讓資料操作更優,這就設計到了,資料型別的支援,**索引模組**。 索引的作用是讓鍵值資料庫根據 key 找到相應 value 的儲存位置,進而執行操作。
有了以上模組的只是,我們是不是要對資料進行操作了?比如往KV資料庫中插入或更新一條資料,刪除和查詢,這就是需要有**操作模組**了。
至此我們已經構造除了一個KV資料庫的基本框架了,帶著這些架構,我們再深入到每個點中去探究,這樣就會輕鬆很多,不會迷失在末枝細節中了。
## Redis為什麼那麼快
我們都知道Redis訪問快,這是因為redis的操作都是在記憶體上的,記憶體的訪問本身就很快,另外Redis底層的資料結構也對“快”起到了至關重要的作用。
我們平常所以所說Redis的5種資料結構:String、Hash、Set、ZSet和List指的只是鍵值對中值的資料結構,而我這裡所說的資料結構,指的是它們底層實現。
Redis的底層資料結構有:簡單動態字串、整數陣列、壓縮列表、跳錶、hash表、雙向列表6種。
簡單動態陣列:就是String的底層實現
其中整數陣列、hash表、雙向列表都是我們常見的資料結構
壓縮列表和跳錶屬於特殊的資料結構
壓縮列表是Redis實現的特殊的陣列:它本質就是一個數組,只不過,我們常見的陣列的每個元素分配的空間大小是一致的,這樣就會導致有多餘的記憶體空間被浪費了。壓縮列表就是為了解決這樣的問題,他的每個元素大小是按實際大小分配的,避免了記憶體的浪費,同時在壓縮列表的表頭還存了關於改列表的相關屬性:用於記錄列表個數zllen,表尾偏移量zltail和列表長度zlbytes。表尾還有一個zlend標記列表的結束。
跳錶:有序連結串列查詢元素只能逐一查詢,跳錶本質上就是連結串列的基礎上加了多級索引,通過多級索引的幾個跳轉,快遞定位到元素所在位置。

不同資料結構的查詢時間複雜度

上面從儲存方面解釋了,redis為什麼快.
###為什麼用單執行緒
逆向思維可以說為什麼不用多執行緒,這個我們得先看下多執行緒存在哪些問題?在正常應用操作中,使用多執行緒可以大大提高處理的時間。那是不是可以無限的加大執行緒數量,以獲取更快的處理速度?實際試驗後,發現在機器資源有限的情況下,不斷增加執行緒處理時間,並沒有像我們想象的那樣成線性增長,而是到達一定階段就趨於平衡,甚至有下降的趨勢,這是為什麼呢?
其實主要有兩個方面,我們知道執行緒是CPU排程的最小單元,當執行緒多的時候,CPU需要不停的切換執行緒,執行緒切換是需要消耗時間的,當大量執行緒需要來回切換,那麼CPU在這切換的損耗了很多時間。
另外當多個執行緒,需要對共享資源進行操作的時候,為了保證併發安全性,需要有額外的機制保證,比如加鎖。這樣就使得當多個執行緒再操作共享資料時,變成了序列。
所以為了避免這些問題,Redis採用了單執行緒操作資料。
### 單執行緒為什麼還真這麼快
我們知道Redis單執行緒操作的,但是隻是指的Redis對外提供鍵值對儲存服務是單執行緒的。Redis的其他功能並不是,比如持久化,非同步刪除,叢集同步等,都是由額外的執行緒去執行的。
除了上面說的,Redis的大部分操作都是在記憶體上完成的,加上高效的資料結構,是他實現高效能的一方面。另外一方面Redis採用的多路複用機制,使其在網路IO操作中能併發處理大量的客戶端請求。
在網路 IO 操作中,有潛在的阻塞點,分別是 accept() 和 recv()。當 Redis 監聽到一個客戶端有連線請求,但一直未能成功建立起連線時,會阻塞在 accept() 函式這裡,導致其他客戶端無法和 Redis 建立連線。類似的,當 Redis 通過 recv() 從一個客戶端讀取資料時,如果資料一直沒有到達,Redis 也會一直阻塞在 recv()。 這就導致 Redis 整個執行緒阻塞,無法處理其他客戶端請求,效率很低。不過,幸運的是,socket 網路模型本身支援非阻塞模式。
Socket 網路模型的非阻塞模式設定,主要體現在三個關鍵的函式呼叫上,如果想要使用 socket 非阻塞模式,就必須要了解這三個函式的呼叫返回型別和設定模式。接下來,我們就重點學習下它們。在 socket 模型中,不同操作呼叫後會返回不同的套接字型別。socket() 方法會返回主動套接字,然後呼叫 listen() 方法,將主動套接字轉化為監聽套接字,此時,可以監聽來自客戶端的連線請求。最後,呼叫 accept() 方法接收到達的客戶端連線,並返回已連線套接字。

針對監聽套接字,我們可以設定非阻塞模式:當 Redis 呼叫 accept() 但一直未有連線請求到達時,Redis 執行緒可以返回處理其他操作,而不用一直等待。但是,你要注意的是,呼叫 accept() 時,已經存在監聽套接字了。
類似的,我們也可以針對已連線套接字設定非阻塞模式:Redis 呼叫 recv() 後,如果已連線套接字上一直沒有資料到達,Redis 執行緒同樣可以返回處理其他操作。我們也需要有機制繼續監聽該已連線套接字,並在有資料達到時通知 Redis。這樣才能保證 Redis 執行緒,既不會像基本 IO 模型中一直在阻塞點等待,也不會導致 Redis 無法處理實際到達的連線請求或資料。
Linux 中的 IO 多路複用機制是指一個執行緒處理多個 IO 流,就是我們經常聽到的 select/epoll 機制。簡單來說,在 Redis 只執行單執行緒的情況下,該機制允許核心中,同時存在多個監聽套接字和已連線套接字。核心會一直監聽這些套接字上的連線請求或資料請求。一旦有請求到達,就會交給 Redis 執行緒處理,這就實現了一個 Redis 執行緒處理多個 IO 流的效果。為了在請求到達時能通知到 Redis 執行緒,select/epoll 提供了基於事件的回撥機制,即針對不同事件的發生,呼叫相應的處理函式。
## Redis是如何保證資料不丟失的
因為Redis是操作是基於記憶體的,所有一點系統宕機存在記憶體中的資料就會丟失,為了實現資料的持久化,Redis中存在兩個持久化機制AOF和RBD。
### AOF(Append Only File)介紹
AOF的原理就是,通過記錄下Redis的所有命令操作,在需要資料恢復的時候,再按照順序把所有命令執行一次,從而恢復資料。
但跟資料庫的寫前日誌不同的,AOF採用的寫後日志,也就是在Redis執行過操作之後,再寫入AOF日誌。之所以為什麼採用寫後日志,可以避免因為寫日誌的佔用redis呼叫的時間,另外為了保證Redis的高效能,在寫aof日誌的時候,不會做校驗,若採用寫前日誌,如果命令是錯誤非法的,在恢復資料的時候就會出現異常。採用寫後日志,只有命令執行成功的才會被儲存。
### AOF策略
AOF的執行策略有三種
all:每次寫入/刪除命令都會被寫入日誌檔案中,保證了資料可靠性,但是寫入日誌,涉及到了磁碟的IO,必然會影響效能
everysec:每秒鐘執行一次日誌寫入,在一秒之內的命令操作會記錄在aof記憶體緩衝區,每一秒會寫回到日誌檔案中,相對於每次寫入效能得以提升,但是在aof緩衝區沒有來得及回寫到日誌檔案中時,系統發生宕機就會丟失這部分資料。
no:記憶體緩衝區的命令記錄不會不主動寫回到日誌檔案中,而交給作業系統決定。這種策略效能最高,但是丟失資料的風險也最大。
### AOF重寫機制
但是AOF檔案過大,會帶來效能問題,所有AOF重寫機制就登場了。
AOF重寫的原理是,將多個命令對同一個key的操作合併成一個,因為資料恢復時,我們只要關心資料最後的狀態就可以了。
需要注意的是,與AOF日誌由主執行緒寫回不同,重寫過程是由後臺子執行緒bgwriteaof來完成的,這個避免阻塞主執行緒,導致資料庫效能下降。
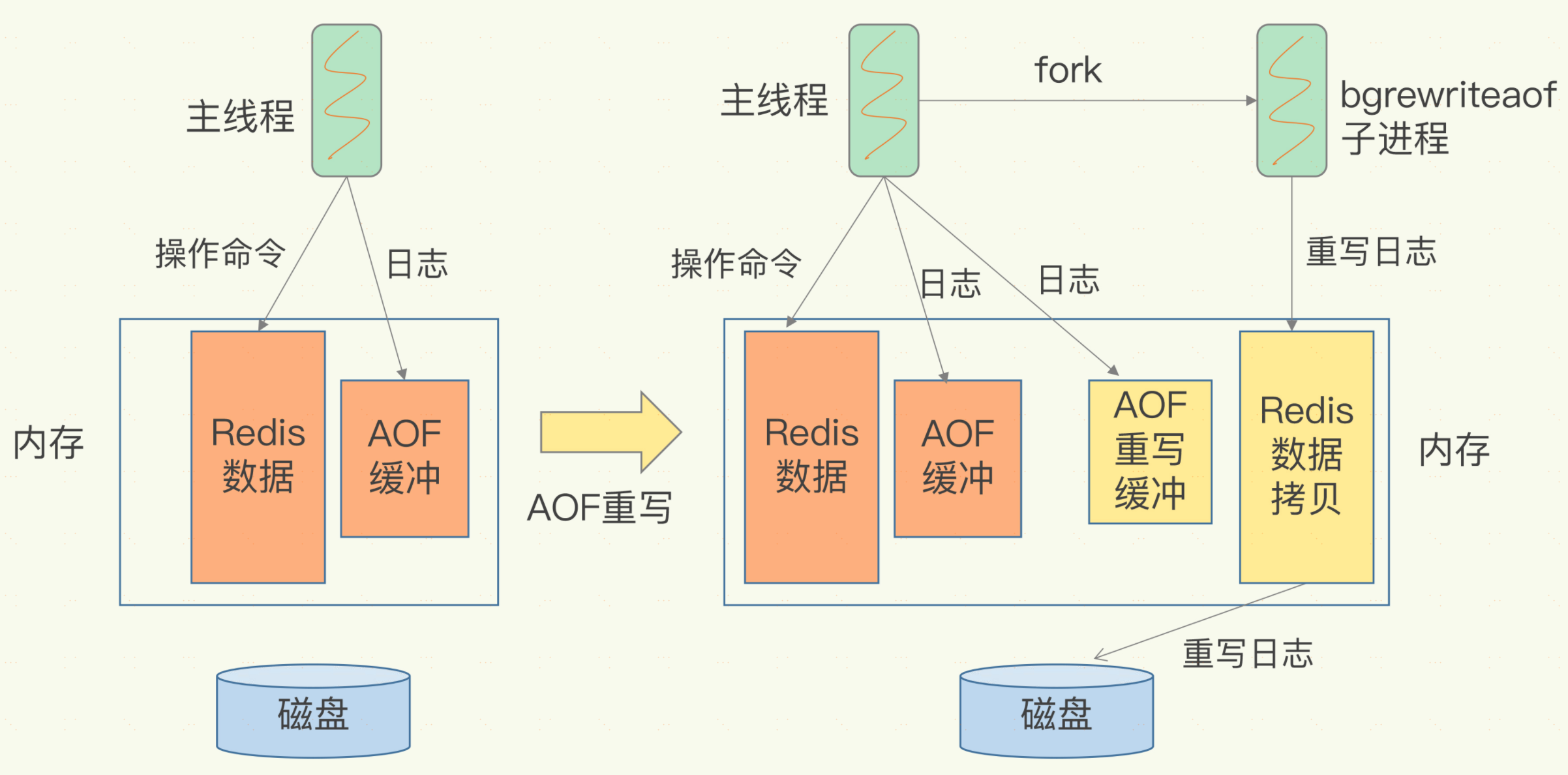
每次 AOF 重寫時,Redis 會先執行一個記憶體拷貝,用於重寫;然後,使用兩個日誌保證在重寫過程中,新寫入的資料不會丟失。而且,因為 Redis 採用額外的執行緒進行資料重寫,所以,這個過程並不會阻塞主執行緒。
## 記憶體快照RDB
### RDB Redis DataBase
所謂記憶體快照,就是指記憶體中的資料在某一個時刻的狀態記錄。對 Redis 來說,就是把某一時刻的狀態以檔案的形式寫到磁碟上。
**Redis執行RDB的策略是什麼?**
Redis進行快照的時候,是進行全量的快照,並且為了不阻塞主執行緒,會預設使用bgsave命令建立一個子執行緒,專門用於寫入RDB檔案。
**快照期間資料還能修改嗎?**
如果不能修改,那麼在快照期間,這塊資料就會只能讀取不能修改,那麼必然影響使用。如果可以修改,那麼Redis是如何實現的?其實Redis是藉助作業系統的寫時複製,在執行快照期間,讓修改的資料,會在記憶體中拷貝出一份副本,副本的資料可以被寫入rdb檔案中,而主執行緒仍然可以修改原資料。
**多久執行一次呢?**
跟aof同樣的問題,如果快照頻率低,那麼在兩次快照期間出現宕機,就會出現資料不完整的情況,如果快照頻率過快,那麼又會出現兩個問題,一個是不停的對磁碟寫出,增大磁碟壓力,可能上一次寫入還沒完成,新的快照又來了,造成惡性迴圈.另外雖然執行快照是主執行緒fork出來的,但是不停的fork的過程是阻塞主執行緒的。
**那麼如何配置才合適呢?**
其實我們只需要第一次全量快照,後續只快照有資料變動的地方就可以大大降低快照的資源損耗了,那麼如何記錄這變動的資料呢,這裡我們可以想到aof具有這樣的功能。Redis4.0就提使用RDB+AOF混合模式來完成Redis的持久化。簡單來說,記憶體快照以一定的頻率執行,在兩次快照之間,使用 AOF 日誌記錄這期間的所有命令操作。
## 主從庫是如何實現資料一致的?
前面我們通過Redis的持久化機制,來保證伺服器宕機之後,通過回放日誌和重新讀取RDB檔案恢復資料,減少資料丟失的風險。
但是在單臺及其的情況下,機器發生宕機,就無法對外提供服務了。我們所說的Redis具有高可靠性,指的一是,資料儘量少丟失,之前持久化機制就解決了這一問題,另一個是服務儘量少中斷,Redis的做法是增加**副本冗餘量**。Redis提供的主從模式,主從庫之間採用了讀寫分離的方式。

從庫只讀取,主庫執行讀與寫,寫的資料主庫會同步給從庫。之所以只讓主庫寫,是因為,如果從庫也寫,那麼當客戶端對一個數據修改了3次,為了保證資料的正確性,就要設法讓主從庫對於寫操作協同,這會帶來鉅額的開銷。
**主從庫間如何進行第一次同步的?**
當我們啟動多個 Redis 例項的時候,它們相互之間就可以通過 replicaof(Redis 5.0 之前使用 slaveof)命令形成主庫和從庫的關係,之後會按照三個階段完成資料的第一次同步。

主庫收到 psync 命令後,會用 FULLRESYNC 響應命令帶上兩個引數:主庫 runID 和主庫目前的複製進度 offset,返回給從庫。從庫收到響應後,會記錄下這兩個引數。
這裡有個地方需要注意,FULLRESYNC 響應表示第一次複製採用的全量複製,也就是說,主庫會把當前所有的資料都複製給從庫。
在第二階段,主庫將所有資料同步給從庫。從庫收到資料後,在本地完成資料載入。這個過程依賴於記憶體快照生成的 RDB 檔案。
具體來說,主庫執行 bgsave 命令,生成 RDB 檔案,接著將檔案發給從庫。從庫接收到 RDB 檔案後,會先清空當前資料庫,然後載入 RDB 檔案。這是因為從庫在通過 replicaof 命令開始和主庫同步前,可能儲存了其他資料。為了避免之前資料的影響,從庫需要先把當前資料庫清空。
在主庫將資料同步給從庫的過程中,主庫不會被阻塞,仍然可以正常接收請求。否則,Redis 的服務就被中斷了。但是,這些請求中的寫操作並沒有記錄到剛剛生成的 RDB 檔案中。為了保證主從庫的資料一致性,主庫會在記憶體中用專門的 replication buffer,記錄 RDB 檔案生成後收到的所有寫操作。
最後,也就是第三個階段,主庫會把第二階段執行過程中新收到的寫命令,再發送給從庫。具體的操作是,當主庫完成 RDB 檔案傳送後,就會把此時 replication buffer 中的修改操作發給從庫,從庫再重新執行這些操作。這樣一來,主從庫就實現同步了。
## Redis如何保證高可用的
### 主庫掛了之後,還能接收寫操作嗎?
Redis在有了主從集群后,如果從庫掛了,Redis對外提供服務不受影響,主庫和其他從庫,依然可以提供讀寫服務,但是當主庫掛了之後,因為是讀寫分離的,如果此時有寫的請求,那麼就無法處理了。Redis是如果解決這樣的問題的呢,這就要引入**哨兵機制**了。
當主庫掛了,我們需要從從庫中選出一個當做主庫,這樣就可以正常對外提供服務了。哨兵的本質就是一個Redis示例,只不過它是執行在特殊模式下的Redis程序。它主要有三個作用:**監控、選舉、通知**。
哨兵在監控到主庫下線的時候,會從從庫中通過一定的規則,選舉出適合的從庫當主庫,並通知其他從庫變更主庫的資訊,讓他們執行replicaof命令,和新主庫建立連線,並進行資料複製。那麼具體每一步都是怎麼做的呢?
**監控**:哨兵會週期性向主從庫傳送PING命令,檢測主庫是否正常執行,如果主從庫沒有在規定的時間內迴應哨兵的PING命令,則會被判定為“下線狀態”,如果是主庫下線,則開始自動切換主庫的流程。但是一般如果只有一個哨兵,那麼它的判斷可能不具有可靠性,所以一般哨兵都是採用叢集模式部署,稱為**哨兵叢集**。單多個哨兵均判斷該主庫下線了,那麼可能他就真的下線了,這是一個少數服從多數的規則。
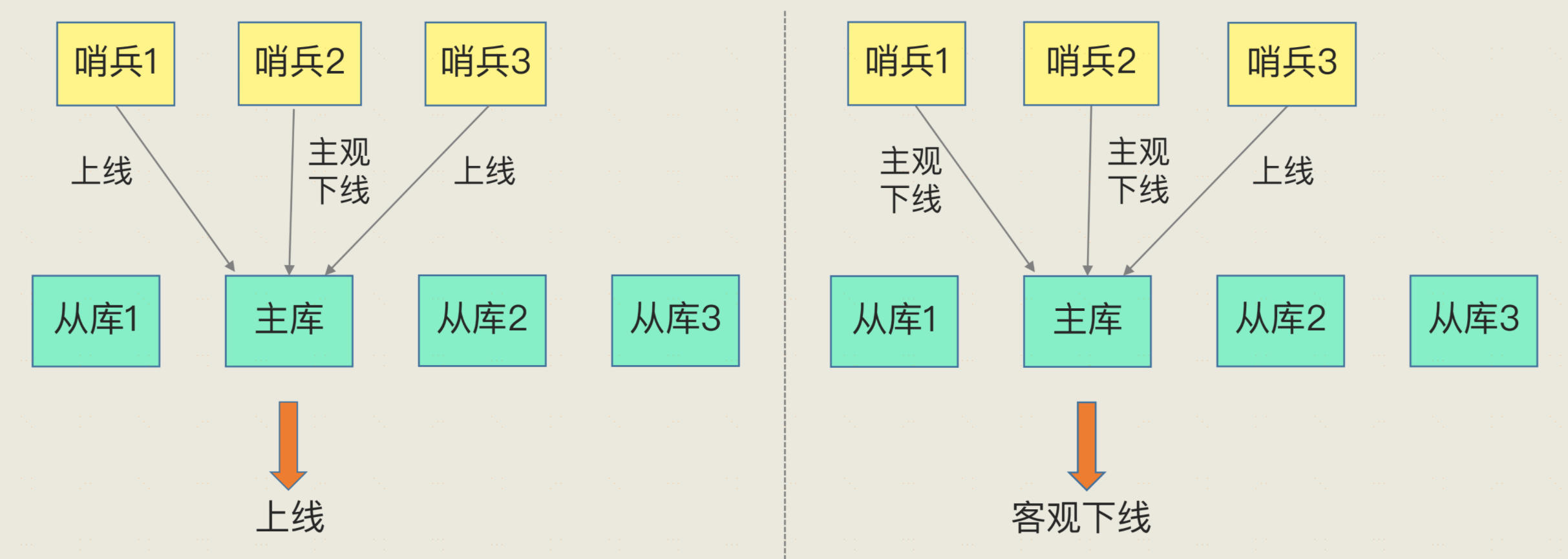
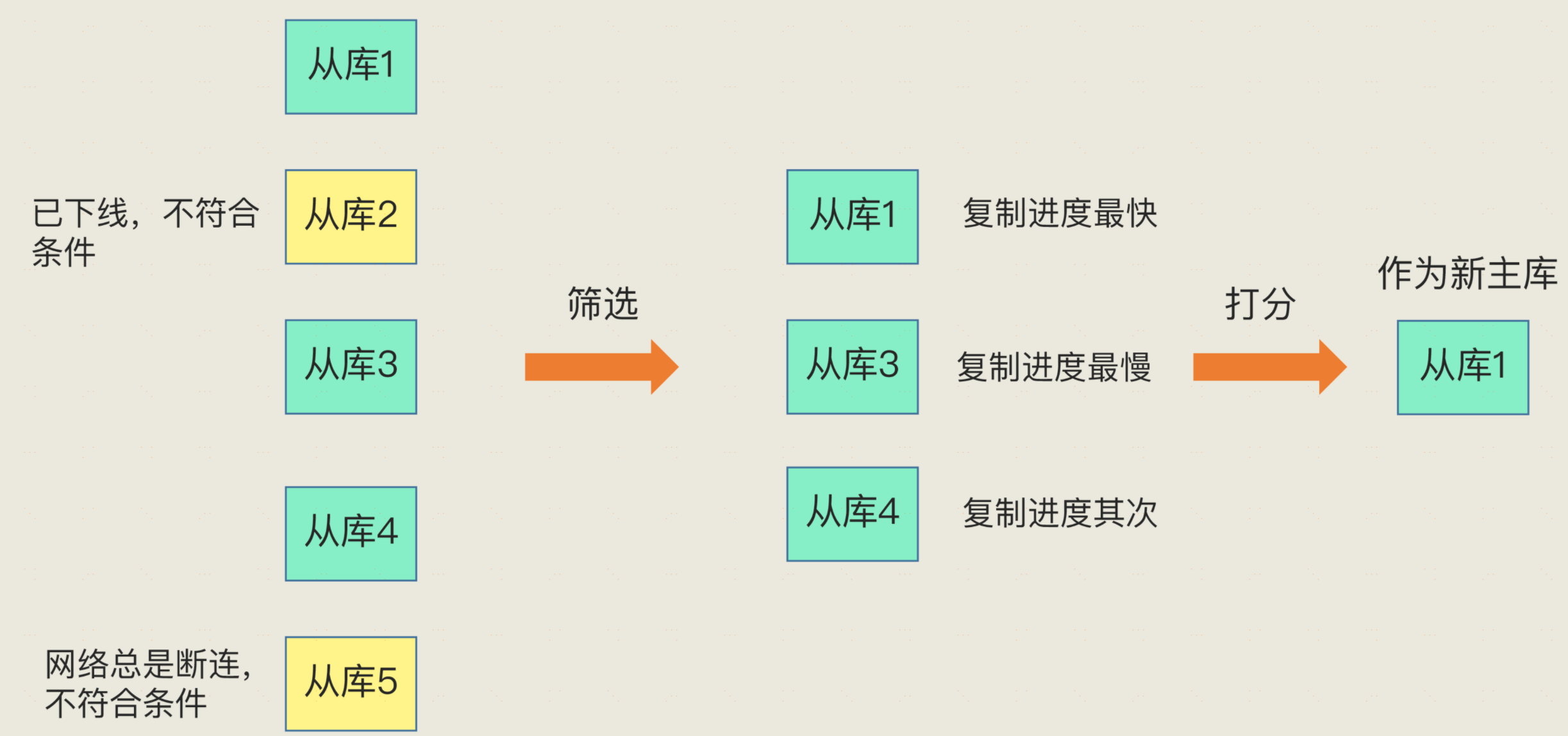
**選舉:** 哨兵選擇新主庫的過程稱為“篩選 + 打分”。簡單來說,我們在多個從庫中,先按照一定的篩選條件,把不符合條件的從庫去掉。然後,我們再按照一定的規則,給剩下的從庫逐個打分,將得分最高的從庫選為新主庫,如下圖所示:

1、排除那些已經下線的從庫,以及連線不穩定的從庫。連線不穩定是通過配置項down-after-milliseconds,當主從連線超時達到一定閾值,就會被記錄下來,比如設定的10次,那麼就會標記該從庫網路不好,不適合做為主庫。
2、篩選出從庫後,第二部就要開始打分了,主要從三方面打分,
1.從庫優先順序,這是可以通過slave-property設定的,設定的高,打分的就高,就會被選為主庫,比如你可以給從庫中記憶體頻寬資源充足設定高優先順序,當主庫掛了之後被優先選舉為主庫。
2.從庫與舊主庫之間的複製進度,之前我們知道主從之間增量複製,有個引數slave-repl-offset記錄當前的複製進度。這個數值越大,說明與主庫複製進度約靠近,打分也會越高。
3.每個從庫建立例項的時候,會隨機生成一個id,id越小的得分越高。
**通知:**哨兵提升一個從庫為新主庫後,哨兵會把新主庫的地址寫入自己例項的pubsub(switch-master)中。客戶端需要訂閱這個pubsub,當這個pubsub有資料時,客戶端就能感知到主庫發生變更,同時可以拿到最新的主庫地址,然後把寫請求寫到這個新主庫即可,這種機制屬於哨兵主動通知客戶端。
如果客戶端因為某些原因錯過了哨兵的通知,或者哨兵通知後客戶端處理失敗了,安全起見,客戶端也需要支援主動去獲取最新主從的地址進行訪問。
所以,客戶端需要訪問主從庫時,不能直接寫死主從庫的地址了,而是需要從哨兵叢集中獲取最新的地址(sentinel get-master-addr-by-name命令),這樣當例項異常時,哨兵切換後或者客戶端斷開重連,都可以從哨兵叢集中拿到最新的例項地址。
### 哨兵叢集
部署哨兵叢集的時候,我們知道只需要配置:sentinel monitor 跟主庫通訊就可以了,並不知道其他哨兵的資訊,那麼是如何知道的呢?
Redis有提供了pub/sub機制,哨兵跟主庫建立了連線之後,將自己的資訊釋出到 “__sentinel__:hello”頻道上,其他哨兵釋出並訂閱了該頻道,就可以獲取其他哨兵的資訊,那麼哨兵之間就可以相互通訊了。
那麼哨兵如何知道從庫的連線資訊呢,那是因為INFO命令,哨兵向主庫傳送該命令後,獲得了所有從庫的連線資訊,就能分從庫建立連線,並進行監控了。
從本質上說,哨兵就是一個執行在特定模式下的 Redis 例項,只不過它並不服務請求操作,只是完成監控、選主和通知的任務。所以,每個哨兵例項也提供 pub/sub 機制,客戶端可以從哨兵訂閱訊息。哨兵提供的訊息訂閱頻道有很多,不同頻道包含了主從庫切換過程中的不同關鍵事件。
### 切片叢集
與mysql一樣,當一張表的資料很大時,查詢耗時可能就會越來越大,我們採取的措施是分表分庫。同樣的Redis也樣,當資料量很大時,比如高達25G,在單分片下,我們需要機器有32G的記憶體。但是我們會發現,有時候redis響應會變的很慢,通過INFO查詢Redis的latest_fork_usec指標,最近fork耗時,發現耗時很大,快到秒級別了,fork這個動作會阻塞主執行緒,於是就導致了Redis變慢了。
於是就有redis分片叢集, 啟動多個 Redis 例項組成一個叢集,然後按照一定的規則,把收到的資料劃分成多份,每一份用一個例項來儲存。回到我們剛剛的場景中,如果把 25GB 的資料平均分成 5 份(當然,也可以不做均分),使用 5 個例項來儲存,每個例項只需要儲存 5GB 資料。
那麼,在切片叢集中,例項在為 5GB 資料生成 RDB 時,資料量就小了很多,fork 子程序一般不會給主執行緒帶來較長時間的阻塞。採用多個例項儲存資料切片後,我們既能儲存 25GB 資料,又避免了 fork 子程序阻塞主執行緒而導致的響應突然變慢。
**那麼資料是如何決定存在在哪個分片上的呢?**
Redis Cluster 方案採用雜湊槽(Hash Slot,接下來我會直接稱之為 Slot),來處理資料和例項之間的對映關係。在 Redis Cluster 方案中,一個切片叢集共有 16384 個雜湊槽,這些雜湊槽類似於資料分割槽,每個鍵值對都會根據它的 key,被對映到一個雜湊槽中。具體的對映過程分為兩大步:首先根據鍵值對的 key,按照CRC16 演算法計算一個 16 bit 的值;然後,再用這個 16bit 值對 16384 取模,得到 0~16383 範圍內的模數,每個模數代表一個相應編號的雜湊槽。
我們在部署 Redis Cluster 方案時,可以使用 cluster create 命令建立叢集,此時,Redis 會自動把這些槽平均分佈在叢集例項上。例如,如果叢集中有 N 個例項,那麼,每個例項上的槽個數為 16384/N 個。 也可以使用 cluster meet 命令手動建立例項間的連線,形成叢集,再使用 cluster addslots 命令,指定每個例項上的雜湊槽個