
[論文理解] Good Semi-supervised Learning That Requires a Bad GAN
阿新 • • 發佈:2020-10-06
# Good Semi-supervised Learning That Requires a Bad GAN
恢復部落格更新,最近沒那麼忙了,記錄一下學習。
## Intro
本文是一篇稍微偏理論的半監督學習的文章,通過證明一個能夠生成非目標分佈的、低樣本密度的樣本的生成器,對半監督學習的效果有很大的提升,這樣的生成器作者稱之為Complement Generator,而提升的原因是生成的bad樣本填充了特徵空間的低密度區域,從而使得分類的分類面在低密度區域,從而避免了分類面穿過流形的情況,因而能夠提升分類的精度。為了得到這樣的生成器,首先利用最大熵使得生成器的熵最大,一方面最大熵可以防止mode collapse,第二方面可以增加生成樣本的豐富度,從而保證生成器能夠生成低密度區域的樣本;然後,利用pixel cnn來估計生成樣本的概率密度,懲罰過於接近流形的生成器生成的樣本。
參考了官方的程式碼,復現了一下本文的演算法。
## Theoretical Analysis
### GAN-Based Semi-Supervised Learning
GAN-Based半監督學習一般採用K+1分類的方式來訓練,與傳統的兩分類的GAN不同的是,用於半監督學習的GAN前K個類別負責預測具體類別,最後一個(K+1)負責預測true or fake。
因此,對於有標籤的樣本,我們大可將其分為前K類中的一類,對於無標籤的樣本,我們認為它們是真實樣本,因此可以將前K個類別的和和第K+1類看成是二分類問題,對於生成的fake樣本同理。
因此,GAN-Based半監督學習的Loss一般為:
$$
\max_D \mathbb{E}_{x,y \backsim \ell} \log P_D(y|x,y\le K) + \mathbb{E}_{x \backsim p} \log P_D(y\leq K|x) + \mathbb{E}_{x \backsim p_G} \log P_D(K+1|x)
$$
其中$\ell$ 代表有標籤的資料,$p$代表無標籤的資料,$p_G$代表生成器生成的資料。
而“Improved techniques for training gans”中則提到,可以將第K+1類的權重設為0,這樣可以減少全連線的引數,事實上,這樣會讓第K+1類的概率的分子項變為常值1,仍然滿足K+1個類別的和為1.所以與原來K+1分類是等價的。
這裡我記得程式碼裡還有個trick是,計算log softmax可以減去一個值防止上溢,即:
$$
Softmax(x_i) = \frac{exp(x_i)}{\sum exp(x_j)} \\
LogSoftmax(x_i) = Log \frac{exp(x_i - c + c)}{\sum exp(x_j - c + c)} \\
= Log \frac{exp(x_i - c)}{\sum exp(x_j - c)} \cdot \frac{exp(c)}{exp(c)} \\
= Log \frac{exp(x_i - c)}{\sum exp(x_j - c)} \\
= (x_i - c) - Log \sum exp(x_j - c)
$$
### Perfect Generator
一個完美的生成器,當然是生成影象的概率分佈$p_G$和真實影象的概率分佈$p$完全一致,即$p_G = p$,此時作者給出了命題1:
#### Proposition 1
如果一個生成器是Perfect Generator,並且D有infinite capacity,那麼對其實下式Loss的任意一個最優解D,都可以找到上面的Loss的最優解$D^*$,使得$P_D(y|x,y \le K) = P_{D^*}(y|x,y \leq K)$。而下式的Loss則完全只包含分類的Loss,因此當生成器很完美的時候,很容易退化為下面的Loss,則相當於只做了有監督部分,而無標籤的資料並沒有得到充分利用。
$$
\max_D \mathbb{E}_{x,y \backsim \ell} \log P_D(y|x, y \le K)
$$
命題1的證明也很簡單:

可以看出來,我們要讓$J_D$取得最大值,所以要同時使得$L_D$和後面那一項最大,而後面那一項取得最大值的結果就是$P_D(K+1|x) = \frac{1}{2}$,然後根據(6),是可以找到這樣一組解的。因此證明了可以得到一組解,可以使得只用有監督部分的Loss和兩者都用的Loss一樣,從而證明了其實存在區域性解可以使半監督部分失去意義。
### Complement Generator
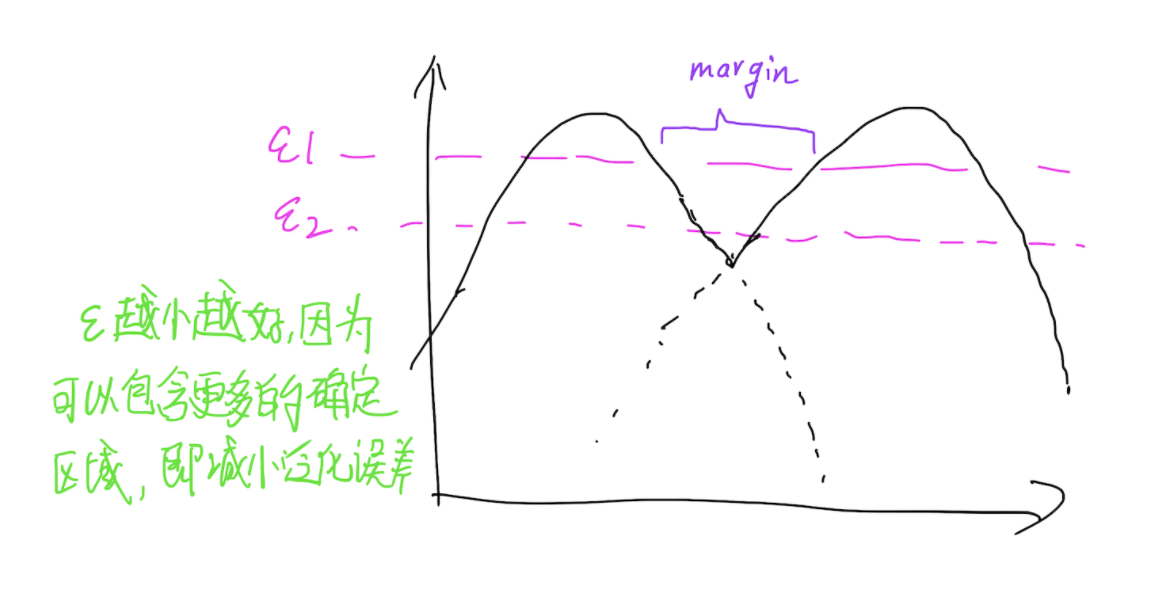
假定對映$f$可以將輸入空間對映到特徵空間,令$p_k(f)$表示第k類樣本在特徵空間的概率密度,給定一個閾值$\epsilon_k$,令$F_k = {f:p_k(f) > \epsilon_k}$,並且假定給定$\{\epsilon_k\}_{k=1}^{K}$,$F_k$之間都有一個margin,這就可以理解為,可以找到一組$\epsilon$使得任意兩個分類面的流形完全分開,分開的距離是一個margin,當然,最好的情況就是$\epsilon$足夠小,這樣才能保證泛化效能。那麼Complement Generator做的就是生成這些流形之外的樣本,也就是流形與流形之間的樣本。
以一維為例,則就是下圖所示的樣子了:
#### Assumption 1. *Convergence conditions.*
當$D$收斂之後,認為$D$能夠學習到一個很好的分類面使得所有的訓練的不同類別樣本都可以分開,也就是說,必須滿足以下三個條件:
1. 對於任意的$(x,y) \in \ell$均有$w^T_yf(x) > w_k^Tf(x)$成立,k表示其他類別($k \neq y$)
2. 對於任意的$x \in \mathcal{G}$,均有$\max_{k=1}^Kw_k^Tf(x)<0$成立
3. 對於任意的$x\in \mathcal{U}$,均有$\max_{k=1}^Kw_k^Tf(x) > 0$成立
由此,提出引理1
#### Lemma 1
假設對於所有的k,都有$||w_k||_2 \leq C$,假設存在一$\epsilon >0$,使得對於任意的$f_G \in F_G$,存在一$f'_G \in \mathcal{G}$使得$||f_G - f_G'||_2 \leq \epsilon$, 根據假設1,則有對任意$k \leq K$,都有$w_k^T < C\epsilon$。
證明比較簡單:
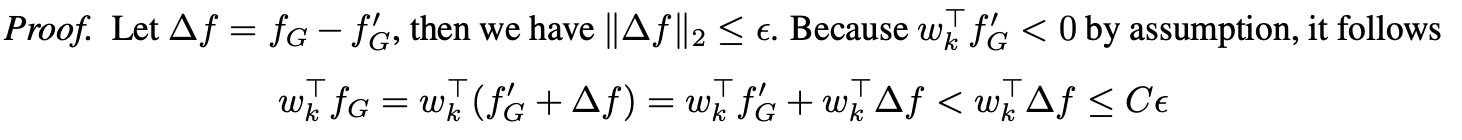
因此可以得到下面的推論
#### Corollary 1
如果能夠生成無窮的樣本,則有$\lim_{|\mathcal{G}| \to \infty}w_k^Tf_G <0$
#### Proposition 2
在引理1的條件下,對於任意類別$k \leq K$,對於任意特徵空間中的點$f_k \in F_k$,都有$w_k^T f_k > w_j^Tf_k$成立,其中$j \neq k$
可以用反證法來證明,如果假設$w_k^T f_k \leq w_j^Tf_j$,那麼一定存在一個$\alpha$,得到一個特徵空間中的點$f_G = \alpha w^T_kf_k + (1 - \alpha)w^T_j f_j$在流形之外,則有$w_j^Tf_G \leq 0$,而$w_k^Tf_k >0$並且$w_j^Tf_j>0$矛盾了。
事實上,如果生成的樣本把流形之外的空間填充的足夠好,這樣相當於強行讓分類面落在流形的邊界處,從而避免了分類面穿過流形的情況。
## Case Study on Synthetic Data
上面都是偏理論的分析,然後作者以簡單的demo來淺顯的說明上述觀點的可行性。
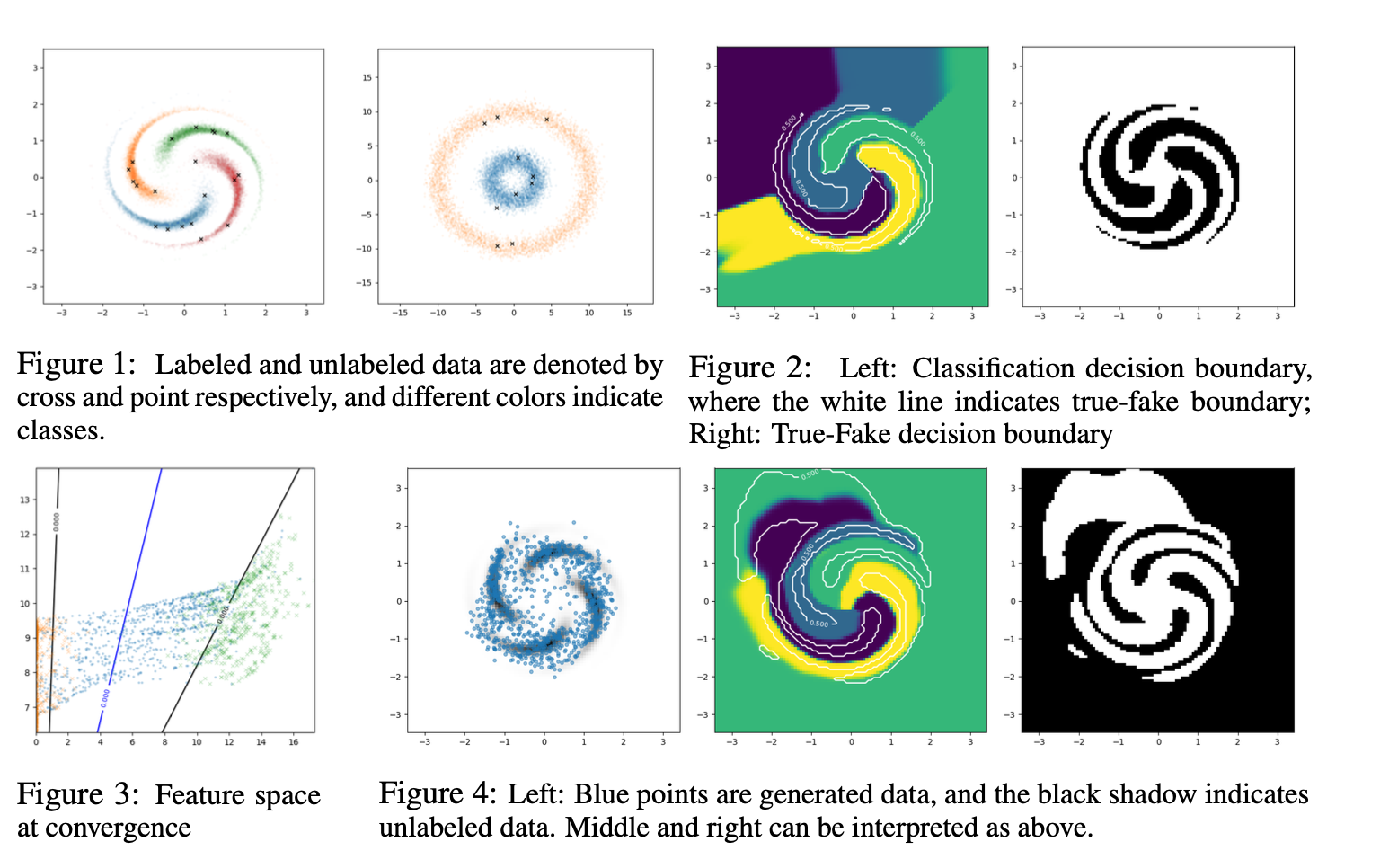
以如圖所示的2D demo為例,fig 1中每種顏色代表一種流形,點代表有標籤的資料。
fig 2 是 Complement Generator生成的樣本點去分類之後的分類面,可以看出無論是真假樣本分類還是具體類別的分類,分類面都比較完美。
fig 3是特徵空間的demo 視覺化,是以fig 1中第二個圖為例展示的,可以看出生成的樣本基本都在流形之間,並且可以找到最佳的分類面,也就是藍色的線,將流形分開。
fig 4 是直接使用feature matching方式生成樣本的結果,可以看到大多數樣本其實都生成在來流形內部,右邊的分類面也不完美,因此傳統的feature matching方法是存在很大的問題的。
## Approach
為了得到這樣的生成器,本文依據feature matching GAN的不足,提出以下幾點改進:
1. 使用最大熵防止collapse,並且生成流形之外的樣本
2. 估計生成樣本的概率並將生成的太接近流形的樣本去掉
對於最大熵,本文提出兩種方式實現,
第一種是通過變分的方式,將輸入空間編碼到高斯分佈,由於生成器的熵的負值具有變分上界,即$-\mathcal{H}(p_G(x)) \leq - \mathbb{E}_{x,z \backsim p_G}log q(z|x)$,通過限定高斯分佈的方差範圍從而避免任意分佈,這樣就可以利用高斯分佈的熵來達到最大化生成器熵的目的。
第二種是通過使用pull-away term的輔助loss來實現,儘量讓生成的樣本之間的距離增大,從而增大生成器的熵。
為了保證生成樣本都在低密度區域,必須把生成樣本接近流形的點去掉。而去掉不會幫助生成器來優化生成的樣本,因此可以加懲罰項懲罰接近流形的樣本,繼而優化生成器。
$$
\mathbb{E}_{x\backsim p_G logp(x)\mathbb{I}[p(x) > \epsilon]}
$$
此外,文章對無標籤的資料加了個條件熵最小化的Loss,因為這類樣本沒有標籤,可能學習到一個對所有標籤均勻分佈的結果,因此最小化標籤的熵,可以讓網路D儘量將概率分佈變為一個確定的分佈,最確定的情況也就是熵最小的情況,就是某一類的概率為1,其他皆為0.
## 復現和實驗
參考官方的程式碼,復現了一下MNIST上的結果,沒有加PT和PixelCNN,但是結果已經相當不錯了,僅僅幾個epoch,在每類只給5個樣本下的MNIST上就能達到95%的TOP1 ACC。
![](https://img2020.cnblogs.com/blog/1492605/202010/1492605-20201006204925182-15028928