
機器學習與深度學習系列連載: 第一部分 機器學習(十三)半監督學習(semi-supervised learning)
阿新 • • 發佈:2018-12-13
在實際資料收集的過程中,帶標籤的資料遠遠少於未帶標籤的資料。 我們據需要用帶label 和不帶label的資料一起進行學習,我們稱作半監督學習。
- Transductive learning:沒有標籤的資料是測試資料
- Inductive learning:沒有標籤的資料不是測試資料
為什麼沒有標籤的資料會幫助我們學習呢? 是因為沒有標籤資料的分佈可能會告訴我們一些潛在的規律。
1.半監督生成模型 Semi-supervised Learning for Generative Model
我們回憶一下監督學習的生成模型,計算先驗概率,然後通過概率模型估計,計算分類概率。
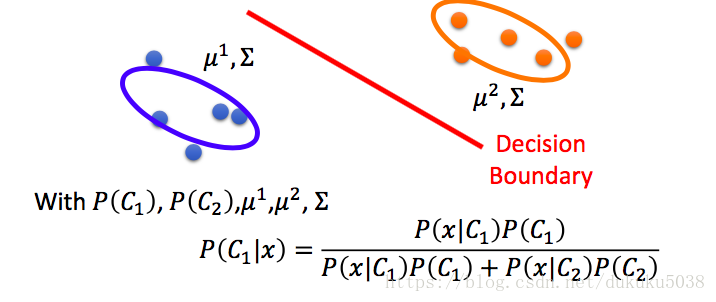
- 尋找概率最大的 和
- 符合高斯分佈
演算法流程如下,但是最後的結果影響與初始值的初始化,結構和EM演算法類似


2. 低密度分割 Low-density Separation
大原則:非黑即白
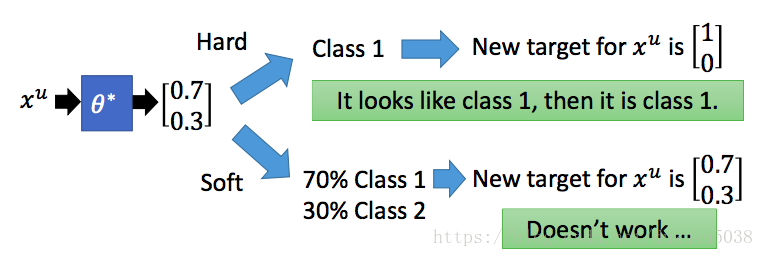
(1)Self-training

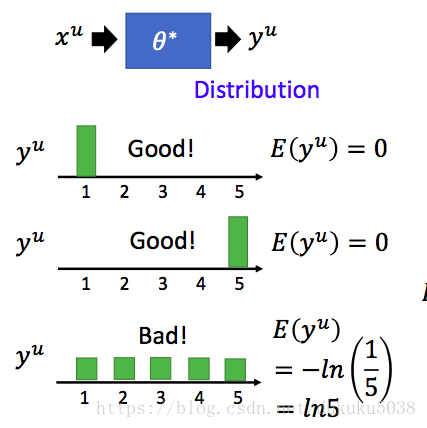


(3)Semi-supervised SVM
 我們取margin 最大的和error最小的
我們取margin 最大的和error最小的
3. 平滑性假設 Smoothness Assumption
近朱者赤,近墨者黑
假設:相似的x 有著相同的分類
- x 並不是uniform 統一的
- 如果和在高密度區域中相似,那麼他們的結果也就y_{1}y_{2}$一致
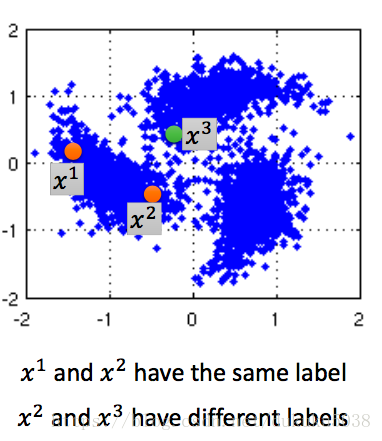
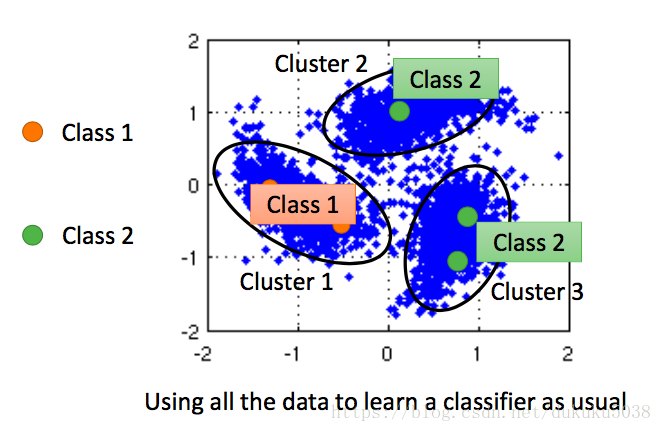
- 定義和的相似度s(,)
- 加入邊edge
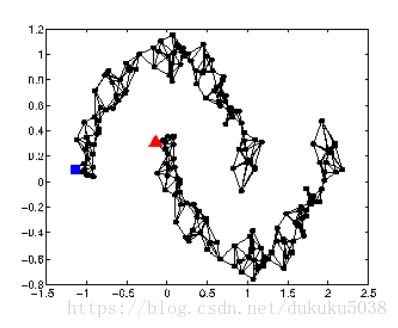
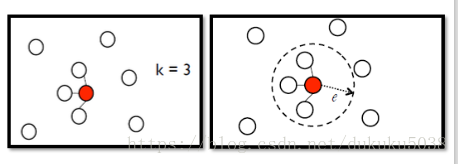
K Nearest Neighbor
e-Neighborhood
- edge 的權重 與s(,)稱比例
s(,)一般表示為Gaussian Radial Basis Function::
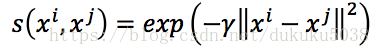
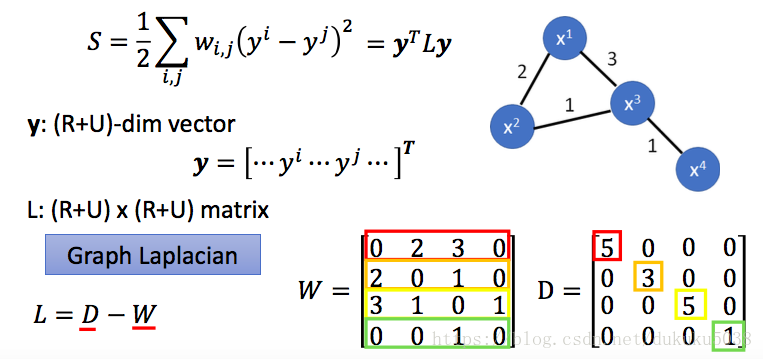
- 定義圖的平滑程度 Define the smoothness of the labels
s 越小越平滑:
如果我們定義s為:

4. Better Representation
去蕪存菁,化繁為簡 具體內容我們再降維的章節介紹。(下一節)