
迴圈神經網路教程 第四部分 用Python 和 Theano實現GRU/LSTM RNN
在本文中,我們將瞭解LSTM(長期短期記憶體)網路和GRU(門控迴圈單元)。 LSTM是1997年由Sepp Hochreiter和JürgenSchmidhuber首次提出的,是當下最廣泛使用的NLP深度學習模型之一。 GRU,首次在2014年使用,是一個更簡單的LSTM變體,它們有許多相同的屬性。我們先從LSTM開始,後面看到GRU的不同的之處。
LSTM 網路
在第3部分,我們瞭解了梯度消失問題是如何阻止標準RNN學習長期依賴的。 LSTM通過門控機制來抵消梯度消失。要理解這是什麼意思,讓我們看看LSTM如何計算隱藏狀態
這些方程看起來相當複雜,但實際上並不那麼難。首先,注意LSTM層只是另一種計算隱藏狀態的方法。以前,我們計算隱藏狀態為
讓我們試著對一個LSTM單元如何計算隱藏狀態有一個直覺。Chris Olah拉有一個很好部落格詳細介紹了這一點,並避免重複他的工作,我只在這裡簡單的解釋。我非常希望你閱讀他的文章,以便有更深的見解和更好的視覺效果。但是,總結一下:
i,f,o 分別稱為輸入門,遺忘門和輸出門。注意,它們具有完全相同的方程,只是引數矩陣不同。被稱作門是因為Sigmoid函式將這些向量的值壓縮在0和1之間,通過elementwise方式乘以一個向量,這樣可以限定你想讓其“通過”多少(結果為0就是全部不通過,為1就是全部通過)。輸入門定義了你想要為當前輸入通過的新計算狀態的多少。忘記門定義了你希望以前的狀態通過的多少。最後,輸出門定義了要暴露給外部網路(更深的層和下一個時刻)的內部狀態的多少。所有的門的維度都是ds ,即隱藏層的大小。g是基於當前輸入和先前隱藏狀態計算的“候選”隱藏狀態。它在vanilla RNN中有完全相同的方程,我們只是將引數
U和W重命名為Ug和Wg 。然而,我們不像在RNN中那樣用g作為新的隱藏狀態,而是使用上面的輸入門來選擇一些。ct 是神經單元的內部記憶。它由前一個記憶ct−1 乘以遺忘門再加上新的隱藏狀態g乘以輸入門組合而成。因此,直觀來講,它是這樣一個組合,即我們想要怎樣結合先前的記憶和新的輸入。我們可以選擇完全忽略舊的記憶(遺忘門全為0)或者完全忽略新計算的狀態(輸入門全為0),但很可能我們想要在這兩種極端之間的某種狀態。給定記憶
ct ,我們最後通過將其與輸出門相乘來計算輸出的隱藏狀態st 。不是所有的內部記憶都與網路中的其他單元使用的隱藏狀態相關。
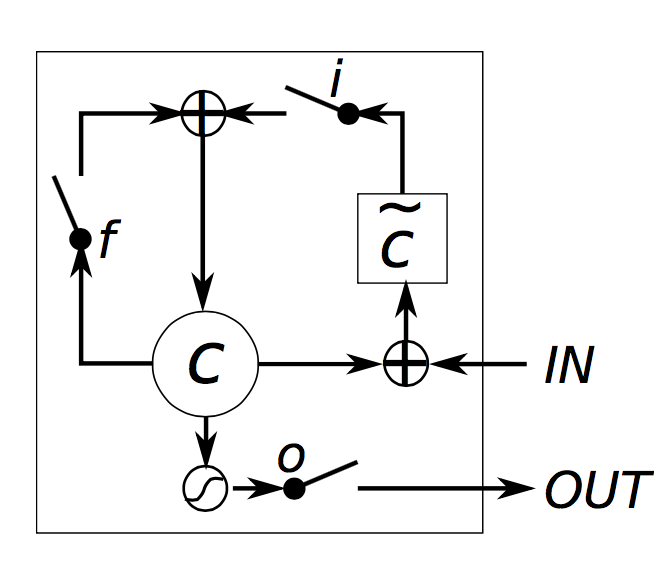
直觀地,簡單RNN可以被認為是LSTM的特殊情況。如果你固定輸入門全為1,忘記門全為0(總是忘記前一個記憶),輸出門全為1(暴露整個記憶),那麼你幾乎可以得到標準RNN。只有一個額外的
值得注意的是,在基本LSTM架構上存在幾種變化。一個常見的問題是建立窺視孔連線,其可以讓門不僅取決於先前的隱藏狀態
GRUS
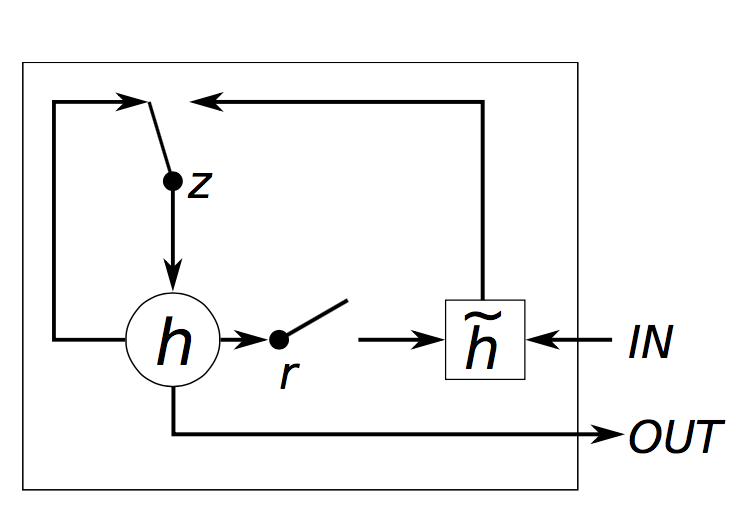
GRU層背後的想法與LSTM層的思想非常相似,方程式也是如此。
GRU具有兩個門,復位門
- GRU具有兩個門,LSTM具有三個門。
- GRU不具有與內部記憶
(ct) 。它們沒有LSTM中的輸出門。 - 輸入門和遺忘門通過更新門z耦合,復位門r被直接應用於先前的隱藏狀態。因此,LSTM中的復位門的責任實際上分為r和z兩者。
- 在計算輸出時,我們不再用非線性函式。
GRU VS LSTM
現在你已經知道了用來對抗梯度消失問題的兩個模型,你可能想知道:使用哪一個? GRU是相當新的(2014年),他們之間的權衡尚未完全探索。根據序列建模的門控迴圈神經網路的經驗評價和迴圈網路架構的實驗探索的評價,沒有一個明確的勝者。在許多工中,兩種架構的效能都不相