
迴圈神經網路教程第四部分-用Python和Theano實現GRU/LSTM迴圈神經網路
連結:https://zhuanlan.zhihu.com/p/22371429
來源:知乎
著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。
本篇教程的程式碼在Github上。這裡是迴圈神經網路教程的最後一部分,前幾部分別是:
本篇中我們將學習LSTM(長短項記憶)網路和GRU(門限遞迴單元)。LSTM由Sepp Hochreiter and Jürgen Schmidhuber在1997年第一次提出,現在是深度學習在NLP上應用的最廣泛的模型。GRU,在2014年第一次提出,是LSTM的簡單變種,和LSTM有很多相似特性。我們首先看一下LSTM,然後會看一下GRU和它有什麼不同。
LSTM網路
在第三部分中,我們看到了消失梯度問題是如何阻止標準的RNN學習到長距離依賴的。LSTM通過使用一個門限機制來克服消失梯度問題。為了理解其中的意思,先看一下LSTM如何計算隱狀態(我使用
表示逐元素相乘):
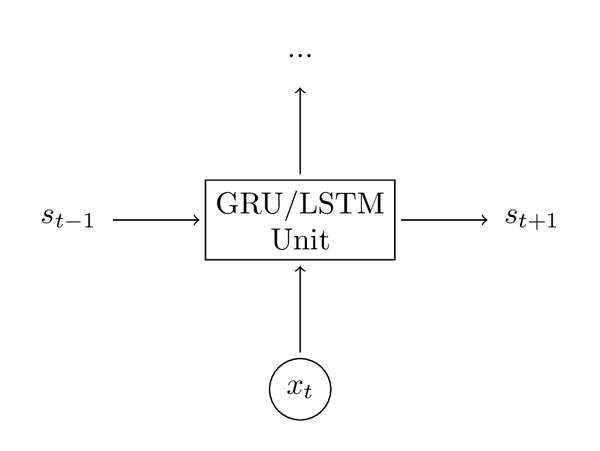
這些公式初看上去很複雜,但實際上沒有那麼難。首先,注意到LSTM層只是計算隱狀態的另一種方法。之前,我們計算隱狀態,這裡的輸入是當前時刻
的輸入和之前的隱狀態
,輸出是一個新的隱狀態
。LSTM單元做的也是同樣的事,只是用了不同的方式,這是理解整個全域性的關鍵。你本質上可以把LSTM(GRU)視作一個黑盒,在給定當前輸入和之前隱狀態後,以某種方式計算下一個隱狀態。
 現在讓我們來理解一下LSTM單元是如何隱狀態的。Chris Olah寫了一篇關於這個問題的很優秀的
現在讓我們來理解一下LSTM單元是如何隱狀態的。Chris Olah寫了一篇關於這個問題的很優秀的
被稱作輸入、遺忘和輸出門。注意到它們的計算公式是一致的,只是用了不同的引數矩陣。它們被稱作門是因為sigmoid函式把這些向量的值擠壓到了0和1之間,把它們和其他的向量逐元素相乘,就定義了你想讓其他向量能“剩下”多少。輸入門定義了針對當前輸入得到的隱狀態能留下多少。遺忘門定義了你想留下多少之前的狀態。最後,輸出門定義了你想暴露多少內部狀態給外部網路(更高層和下一時刻)。所有門都有相同的維度
,即隱狀態的大小。
是根據當前的輸入和之前的隱狀態計算得到的一個“候選”狀態。它和普通的RNN有完全相同的計算公式,只是我們把引數
重新命名為。然而,和在RNN中把
是單元的內部記憶。它是之前的記憶
乘以遺忘門加上新得到的隱狀態
乘以輸入門得到的結果。因此,直觀上可以認為它是我們如何組合之前的記憶和新的輸入而得到的結果。我們可以選擇完全忽略舊的記憶(遺忘門全0)或者完全忽略計算得到的新狀態(輸入門全0),但是大多數時候會選擇這兩個極端之間的結果。
- 給定當前記憶
。在網路中,不是所有的內部記憶都會和其他單元使用的隱狀態相關。
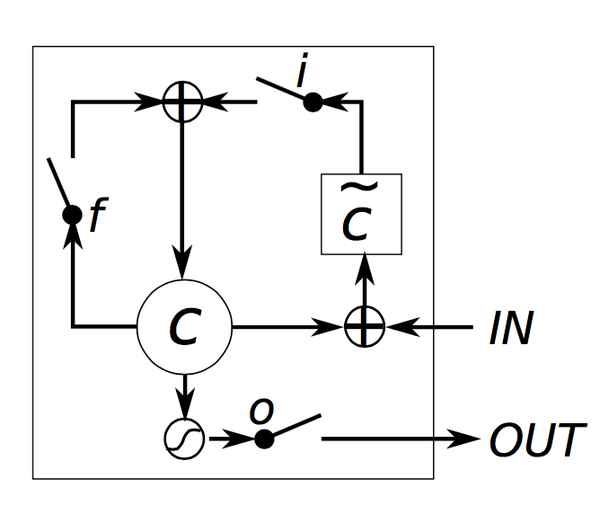 直觀上,普通RNN可以認為是LSTM的一個特例。如果你把輸入門全部固定為1,遺忘門全部固定為0(你通常會忘記之前的記憶),輸出門全都固定為1(你暴露出全部記憶),你得到的幾乎就是標準RNN,只是多了一個額外的tanh把輸出壓縮了一些。門機制讓LSTM能顯式地對長期依賴進行建模。通過學習門的引數,網路能夠學會如何表示它的記憶。
直觀上,普通RNN可以認為是LSTM的一個特例。如果你把輸入門全部固定為1,遺忘門全部固定為0(你通常會忘記之前的記憶),輸出門全都固定為1(你暴露出全部記憶),你得到的幾乎就是標準RNN,只是多了一個額外的tanh把輸出壓縮了一些。門機制讓LSTM能顯式地對長期依賴進行建模。通過學習門的引數,網路能夠學會如何表示它的記憶。
值得注意的是,也存在一些基本LSTM架構的變種。一個常見的變種建立peephole連線,讓門不僅依賴於之前的隱狀態
GRUS
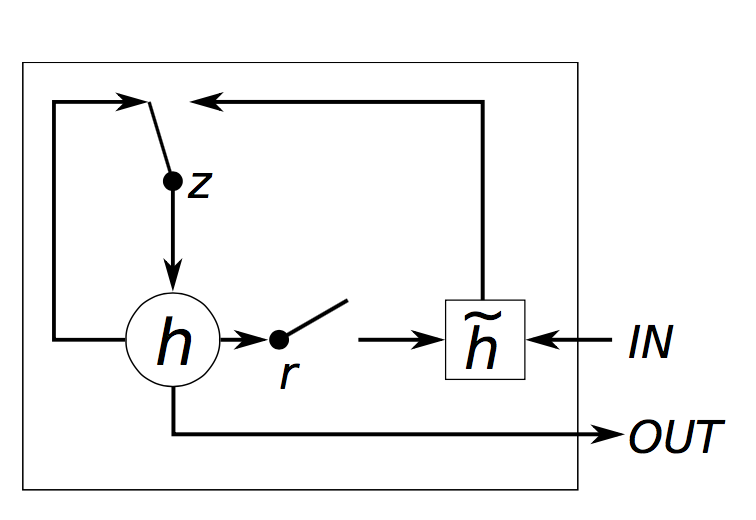
GRU層中的思想和LSTM層十分相似,公式如下:
GRU有兩個門,重置門,更新門
。直觀上,重置門決定了如何組合新輸入和之前的記憶,更新門決定了留下多少之前的記憶。如果我們把重置門都設為1,更新門都設為0,也同樣得到了普通的RNN模型。使用門機制的基本思想和LSTM相同,都是為了學習長期依賴,但是也有一些重要的不同之處:
- GRU有兩個門,LSTM有三個門。
- GRU沒有不同於隱狀態的內部記憶
- 輸入門和遺忘門通過更新門
進行耦合,重置門
被直接應用於之前的隱狀態。因此,LSTM中的重置門的責任實質上被分割到了
- 在計算輸出時,沒有使用第二個非線性單元。
GRU VS LSTM
現在你已經看到了兩個能夠解決消失梯度問題的模型,你可能會疑惑:使用哪一個?GRU非常新,它們之間的權衡沒有得到完全的研究。根據Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling和 An Empirical Exploration of Recurrent Network Architectures的實驗結果,兩者之前沒有很大差別。在許多工中,兩種結構產生了差不多的效能,調整像層大小這樣的引數可能比選擇合適的架構更重要。GRU的引數更少,因而訓練稍快或需要更少的資料來泛化。另一方面,如果你有足夠的資料,LSTM的強大表達能力可能會產生更好的結果。
實現
讓我們回到第二部分中實現的語言模型,現在在RNN中使用GRU單元。這裡沒有什麼重要的原因關於為什麼在這一部分中使用GUR而不是LSTM(除了我想更熟悉一下GRU外)。它們的實現幾乎相同,因此你可以很容易地根據改變後的公式把GRU的程式碼修改成LSTM的。
這裡基於的是之前的Theano實現,注意到GRU只是另一種計算隱狀態的方式,所以這裡我們只需要在前向傳播函式中改變之前的隱狀態計算方式。
def forward_prop_step(x_t, s_t1_prev):
# This is how we calculated the hidden state in a simple RNN. No longer!
# s_t = T.tanh(U[:,x_t] + W.dot(s_t1_prev))
# Get the word vector
x_e = E[:,x_t]
# GRU Layer
z_t1 = T.nnet.hard_sigmoid(U[0].dot(x_e) + W[0].dot(s_t1_prev) + b[0])
r_t1 = T.nnet.hard_sigmoid(U[1].dot(x_e) + W[1].dot(s_t1_prev) + b[1])
c_t1 = T.tanh(U[2].dot(x_e) + W[2].dot(s_t1_prev * r_t1) + b[2])
s_t1 = (T.ones_like(z_t1) - z_t1) * c_t1 + z_t1 * s_t1_prev
# Final output calculation
# Theano's softmax returns a matrix with one row, we only need the row
o_t = T.nnet.softmax(V.dot(s_t1) + c)[0]
return [o_t, s_t1]
在實現中,我們添加了偏置項,可以看出這並沒有展示在公式中。當然,這裡我們需要改變引數
的初始化方式,因為現在它們的大小變化了。這裡並沒有展示出初始化的程式碼,但是在Github上可以找到。這裡我同樣添加了一個嵌入層
,會在下面提到。
現在看起來非常簡單,但是梯度怎麼計算呢?我們可以像之前一樣用鏈式法則手工推匯出的梯度。但在實際中,大多數人使用支援自動微分的庫Theano。如果你不得不自己來計算梯度,你可能想把不同的單元模組化,並用鏈式法則得到你自己的自動微分版本。這裡我們使用Theano來計算梯度:
# Gradients using Theano
dE = T.grad(cost, E)
dU = T.grad(cost, U)
dW = T.grad(cost, W)
db = T.grad(cost, b)
dV = T.grad(cost, V)
dc = T.grad(cost, c)
這基本上就差不多了。為了得到更好的結果,在實現中我們也使用了一些額外的技巧。
使用RMSPROP來更新引數
在第二部分中,我們使用最簡單的隨機梯度下降(SGD)來更新我們的引數,事實證明這並不是一個好主意。如果你把學習率設得很低,SGD保證能找到一個好的解,但在實際中會花費很長的時間。有一些常用的SGD的變種,包括 (Nesterov) Momentum Method,AdaGrad,AdaDelta和RmsProp,這篇文章中對這些方法有一個很好的綜述。我也打算在將來的文章的文章中仔細探索每一個方法的實現。針對教程本部分,我準備選用rmsprop,它的基本思想是根據之前的梯度和逐引數調整學習率。直觀上,這意味著頻繁出現的特徵會獲得較小的學習率,稀有的特徵會獲得較大的學習率。
rmsprop的實現很簡單。針對每個引數,我們儲存一個快取變數,在梯度下降時,我們如下更新引數和快取變數(以為例):
cacheW = decay * cacheW + (1 - decay) * dW ** 2
W = W - learning_rate * dW / np.sqrt(cacheW + 1e-6)
衰減率通常設為0.9或0.95,加上1e-6項是為了防止除0。
新增一個嵌入層
使用word2vec和Glove這樣的詞嵌入模型是提高模型精度的一個常用手段。相對於使用one-hot向量表示詞,使用word2vec和Glove學習到的低維向量中含有一定的語義——相似的詞有著相似的向量。使用這些向量是預訓練的一種形式。直觀上,你告訴神經網路哪些詞是相似的,以便於它可以更少地學習語言知識。使用預訓練的向量在你沒有大量的資料時非常有用,因為它能讓網路可以對未見過的詞進行泛化。我在實驗中沒有使用預訓練的詞向量,但是新增一個嵌入層(程式碼中的矩陣)很容易。嵌入矩陣只是一個查詢表——第i個列向量對應於詞表中的第i個詞。通過更新矩陣
,我們也可以自己學習詞向量,但只能特定於我們的任務,不如可以下載到的在上億個文件訓練的詞向量那麼通用。
新增第二個GRU層
在我們的網路中新增第二個層可以讓模型捕捉到更高層的互動。你也可以再新增額外的層,但我在實驗中沒有嘗試。在新增2到3個層後,你可能會接著觀察到損失值在降低,當然除非你有大量的資料,更多的層不可能會產生很大的影響,甚至可能導致過擬合。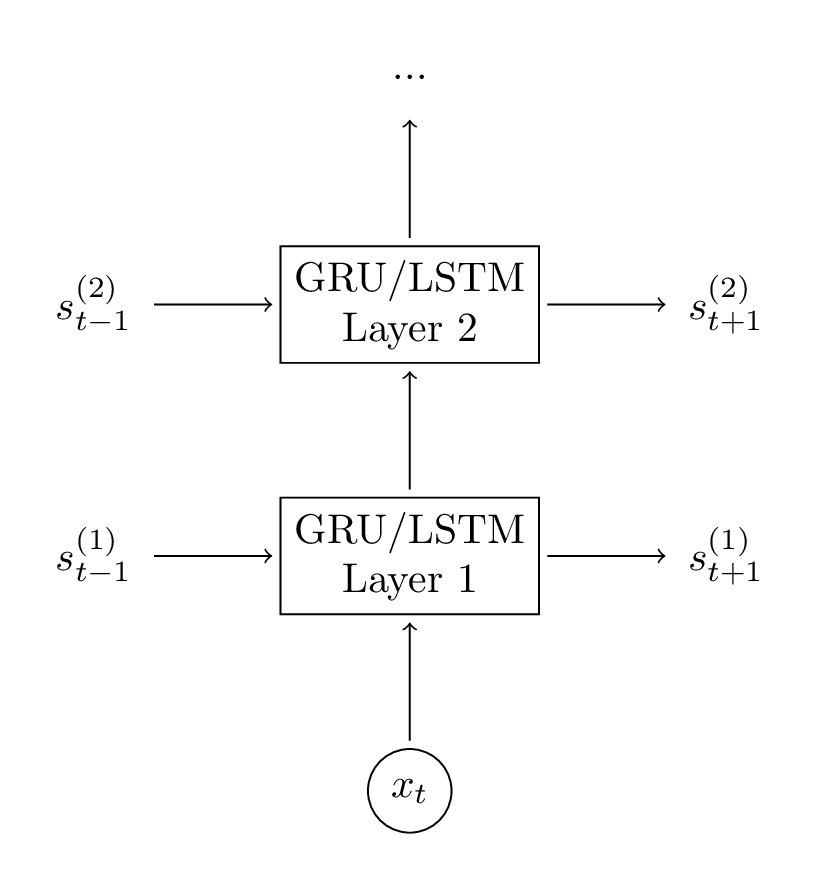 向網路中新增第二個層是很簡單的,我們只需要修改前向傳播中的計算過程和初始化函式。
向網路中新增第二個層是很簡單的,我們只需要修改前向傳播中的計算過程和初始化函式。
# GRU Layer 1
z_t1 = T.nnet.hard_sigmoid(U[0].dot(x_e) + W[0].dot(s_t1_prev) + b[0])
r_t1 = T.nnet.hard_sigmoid(U[1].dot(x_e) + W[1].dot(s_t1_prev) + b[1])
c_t1 = T.tanh(U[2].dot(x_e) + W[2].dot(s_t1_prev * r_t1) + b[2])
s_t1 = (T.ones_like(z_t1) - z_t1) * c_t1 + z_t1 * s_t1_prev
# GRU Layer 2
z_t2 = T.nnet.hard_sigmoid(U[3].dot(s_t1) + W[3].dot(s_t2_prev) + b[3])
r_t2 = T.nnet.hard_sigmoid(U[4].dot(s_t1) + W[4].dot(s_t2_prev) + b[4])
c_t2 = T.tanh(U[5].dot(s_t1) + W[5].dot(s_t2_prev * r_t2) + b[5])
s_t2 = (T.ones_like(z_t2) - z_t2) * c_t2 + z_t2 * s_t2_prev
關於效能的注意點
在前面的文章中提到過效能的問題,現在我想說明的是這裡提供的程式碼並不十分高效,主要是為了簡明性做了優化,並且主要用於教育目的。對於瞭解模型來說可能已經足夠了,但是不要將模型用於生產環境或者用大量的資料來訓練模型。已經有了許多優化RNN效能的技巧,但是其中最重要的一個可能是用批量資料更新模型引數。相較於每次學習一個句子,你應該把相同長度的句子分成組(甚至把所有句子填充到相同長度),然後進行大規模矩陣乘法,並按批將梯度加和。這是因為大規模矩陣乘法可以用GPU高效處理。如果不這麼做,使用GPU帶來的加速是很少的,訓練過程會非常緩慢。
所以,對於訓練大規模的模型,我強烈建議使用一個針對性能優化過的深度學習庫。用上面的程式碼需要訓練幾天或幾周的模型用這些庫只需要訓練幾小時。我個人比較喜歡Keras,它非常易用,並帶有一些關於RNN的非常好的例子。
結果
為了免去你用幾天時間訓練模型的痛苦,我訓練了一個和教程二中的模型很相似的一個模型。我使用的詞表大小是8000,把詞對映到了48維向量,並用了兩個128維的GRU層。這個IPython notebook包含了載入模型的程式碼,你可以直接使用它,修改它,用它來生成文字。
下面是一些網路輸出的非常不錯的例子(我添加了首字母大寫):
I am a bot , and this action was performed automatically .I enforce myself ridiculously well enough to just youtube.I’ve got a good rhythm going !There is no problem here, but at least still wave !It depends on how plausible my judgement is .( with the constitution which makes it impossible )
觀察這些句子在多個時刻的語義依賴是非常有意思的。例如,機器人和自動地是明顯相關的,開關括號也是。我們的網路能學習到這些,看起來非常酷!
PS:RNN系列教程翻譯算是告一段落了,裡面的一些實驗我還沒有做,後續也會去做。RNN對於序列建模來說很強大,在自動問答,機器翻譯,影象描述生成中都有使用,後續會翻譯或自己寫一些這方面的內容,^_^!!!
相關推薦
迴圈神經網路教程第四部分-用Python和Theano實現GRU/LSTM迴圈神經網路
作者:徐志強 連結:https://zhuanlan.zhihu.com/p/22371429 來源:知乎 著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。 本篇教程的程式碼在Github上。這裡是迴圈神經網路教程的最後一部分,前幾部分別是: 本篇中我們將學習LSTM(長短項記憶)網路和G
迴圈神經網路教程 第四部分 用Python 和 Theano實現GRU/LSTM RNN
在本文中,我們將瞭解LSTM(長期短期記憶體)網路和GRU(門控迴圈單元)。 LSTM是1997年由Sepp Hochreiter和JürgenSchmidhuber首次提出的,是當下最廣泛使用的NLP深度學習模型之一。 GRU,首次在2014年使用,是一個
dos/bat批處理教程——第四部分:完整案例
echo 目錄 發布 判斷 案例 不能 goto 信息 iis dos/bat批處理教程——第四部分:完整案例 以上就是批處理的一些用法。現在我們把這些用法結合起來詳細的分析一下目前網上發布的一些批處理,看看他們是怎麽運作的。這裏我將列舉三個例子來詳細分析,為了保持程序
co_routine.cpp/.h/inner.h(第四部分:定時器和事件迴圈)—— libco原始碼分析、學習筆記
由於本原始碼蠻長的,所以按照功能劃分模組來分析,分為若干部分,詳見二級目錄↑ 定時器和事件迴圈 libco管理定時事件便是使用時間輪這種資料結構 定時器前驅知識本篇只稍微提一下,具體知識請參考《Linux高效能伺服器程式設計 遊雙 著》第11章,或其他方式學
計算機網路教程第四章網路層層課後習題答案
第四章網路層1.網路層向上提供的服務有哪兩種?是比較其優缺點。網路層向運輸層提供 “面向連線”虛電路(Virtual Circuit)服務或“無連線”資料報服務前者預約了雙方通訊所需的一切網路資源。優點是能提供服務質量的承諾。即所傳送的分組不出錯、丟失、重複和失序(不按序列到
Webpack 4教程 - 第八部分 使用prefetch和preload進行動態載入
轉載請註明出處:葡萄城官網,葡萄城為開發者提供專業的開發工具、解決方案和服務,賦能開發者。原文出處:https://wanago.io/2018/08/13/webpack-4-course-part-seven-decreasing-the-bundle-size-with-tree-shaking/
用Python和OpenCV實現照片馬賽克拼圖(蒙太奇照片)
馬賽克拼圖介紹: 相片馬賽克(Photomosaic),或稱蒙太奇照片、蒙太奇拼貼,是一種影像處理的藝術技巧,利用這個方式做出來的圖片,近看時是由許多張小照片合在一起的,但遠看時,每張照片透過光影和色彩的微調,組成了一張大圖的基本畫素,就叫做相片馬賽克技巧。最先是由一個
【JavaFx教程】第四部分:CSS 樣式
第4部分主題 CSS樣式表 新增應用程式圖示 CSS樣式表 在JavaFX中,你能使用層疊樣式表修飾你的使用者介面。這非常好!自定義Java應用介面從來不是件簡單的事情。 在本教程中,我們將建立一個*DarkTheme*主題,靈感來自於Windows 8 Metr
RabbitMQ官方中文入門教程(PHP版) 第四部分:路由(Routing)
路由(Routing) 在前面的教程中,我們實現了一個簡單的日誌系統。可以把日誌訊息廣播給多個接收者。 本篇教程中我們打算新增一個功能——使得它能夠只訂閱訊息的一個字集。例如,我們只需要把嚴重的錯誤日誌資訊寫入日誌檔案(儲存到磁碟),但同時仍然把所有的日誌資訊輸出到控制檯中
deeplearning.ai 第四課第一週,step by step 卷積神經網路的python實現
1、填充零的padding函式實現 # GRADED FUNCTION: zero_pad def zero_pad(X, pad): """ Pad with zeros all images of the dataset X. The
深度學習網路__tensorflow__第四講__神經網路優化
√神經網路待優化的引數:神經網路中所有引數w 的個數 + 所有引數 b 的個數 例如: 輸入層 隱藏層 輸出層 在該神經網路中,包含 1 個輸入層、1個隱藏層和 1 個輸出層,該神經網路的層數為 2 層。 在該神經網路中,引數的個數是所有引數 w 的個數加上所有引數 b 的總數,第一層引數用三行四列的二階張量
Linux Unix shell 編程指南學習筆記(第四部分)
fcm 驗證 () only arguments line div 反饋 sed 第十六章 shell腳本介紹 此章節內容較為簡單,跳過。 第十七章 條件測試 test命令 expr命令 test 格式 test condition 或者 [
【Linux探索之旅】第四部分第三課:文件傳輸,瀟灑同步
命令行 上傳文件 文件夾 images lsh wget命令 ace 目標 wechat 內容簡單介紹 1、第四部分第三課:文件傳輸。瀟灑同步 2、第四部分第四課:分析網絡。隔離防火 文件傳輸。瀟灑同步 這一課的內容相
第四天 用戶 群組 權限
賬戶管理 登錄 apache 賬戶 分頁顯示 信息 例如 etc span 第四天 快速查看文本的命令操作: ps:esc+. 可以復制上一條命令 more命令 分頁顯示 單向顯示不能返回
StanFord ML 筆記 第四部分
gauss 筆記 貝葉斯 sta bayes algo generate 部分 span 第四部分: 1.生成學習法 generate learning algorithm 2.高斯判別分析 Gaussian Discriminan
Python培訓知識總結系列- 第二章Python數據結構第四部分-字典操作
... 哈希 int lis san 變量 ems python python字典 python字典鍵值對的添加和遍歷 添加鍵值對 首先定義一個空字典 dic={}1直接對字典中不存在的key進行賦值來添加 dic[‘name‘]=‘zhangsan‘dic{‘name‘:
jQuery基礎教程(第四版)第3章練習:
top ads afa reg 1.2 weight don ems doctype 關於答案: // // (1) 在Charles Dickens被單擊時,給它應用 selected 樣式。$(document).ready(function() { $(‘#he
Ajax本地跨域問題 Cross origin requests are only supported for HTTP(針對jQuery基礎教程第四版第六章)
成功 origin port com img 步驟 -s 出現 req 出現的問題: 解決的步驟: 谷歌瀏覽器出現的效果: 針對jQuery基礎教程(第四版),第六章 成功: Ajax本地跨域問題 Cross origin re
【zabbix系列教程】四、用戶自定義監控
系統用戶 新建 mct 運用 systemctl 一個 start shell 教程 本篇介紹運用zabbix進行自定義監控,以系統用戶登錄數量為例。 一、zabbix自定義語法 UserParameter=<key>,<shell command
Apache Hadoop 入門教程第四章
大數據 hadoop 運行在單節點的 YARN 您可以通過設置幾個參數,另外運行 ResourceManager 的守護進程和 NodeManager 守護進程以偽分布式模式在 YARN 上運行 MapReduce job。 以下是運行步驟。 (1)配置 etc/hadoop/mapred-site.