深度學習花書學習筆記 第十章 序列建模:迴圈神經網路
展開計算圖
就是將迴圈圖展開成展開圖而已。
迴圈神經網路

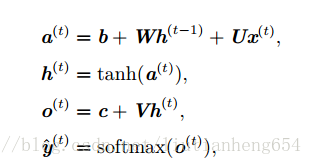
就是如上網路,將某一層不斷重複,輸出重新作為輸入的一部分。
雙向RNN
應用於上下文環境都影響結果的場景,如語音識別,文章翻譯等
基於編碼-解碼的序列到序列架構
可以將可變長度的輸入轉變為可變長度的輸出。這裡也提到了注意力模型。後面瞭解下自編碼網路有沒有用到迴圈神經網路的技術。自編碼網路是將一個東西編碼後解碼再還原成原有事務。這裡的編碼解碼不一樣,是一個序列到另一個序列。
深度迴圈網路
將迴圈網路應用於深度學習中的部分層。
遞迴神經網路
主要用於推斷學習,處理同樣大小的序列,深度降低。主要問題是如何構建樹。一種方式構建平衡二叉樹,一種以先驗知識為基礎構建。
長期依賴挑戰
迴圈網路涉及相同函式的多次組合,當次數過多時,導致極端非線性。比如梯度消失和梯度爆炸。
後面幾節介紹採取的一些措施減少長期依賴。
回聲狀態網路
譜半徑:特徵值得最大絕對值。
添加了儲層計算。用來儲存之前學到的知識,用於後續處理。
ESN:回聲狀態網路
貌似很少遇到回聲狀態網路這個概念。
滲漏單元和其他多時間尺度的策略
時間維度的跳躍連線:構造t到t+n時刻的連線,減輕梯度消失和梯度爆炸。
滲漏單元和一系列不同時間尺度:,當
接近1時,能記住之前很長一段時間資訊。
可手動設定或者通過學習。
刪除連線:主動刪除長度為1的連線並用更長的連線替換。
長短期記憶和其他門控RNN
這裡主要介紹兩種最常用的LSTM和GRU,可以有效克服長期依賴。
LSTM:長短期記憶
主要包括三個模組:
忘記們:
輸出門:
輸入門:
GRU:門控迴圈單元
優化長期依賴
主要針對梯度爆炸和梯度消失。
當梯度爆炸時,可以使用梯度截斷,有兩個思路,一個是當梯度大於一定閾值時,設定當前梯度為閾值;另一個是大於閾值時,隨機往一個方向走一小步,看能否跳出這段不穩定區域。
梯度消失時使用資訊流正則化,加入以下正則:
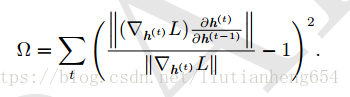
這段沒理解。如何引導資訊流。
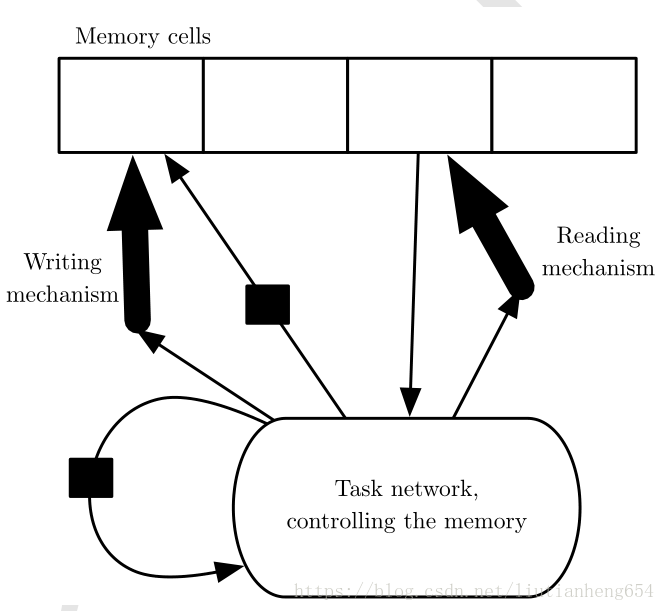
外顯記憶
就是通過使用專門的儲存單元儲存得到的記憶,可以儲存較多的內容,而後通過定址的方式查詢記憶來進行學習。
可以基於內容定址。定址方式可以類似注意力機制。示意圖如下: