
機器學習——非監督學習——層次聚類(Hierarchical clustering)
1、層次聚類(Hierarchical clustering)的步驟
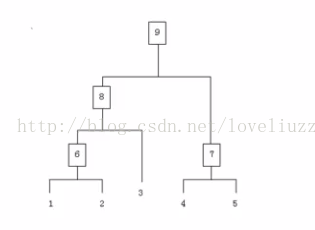
假設有N個待聚類的樣本,對於層次聚類來說,其步驟為:
(1)初始化:把每個樣本各自歸為一類(每個樣本自成一類),計算每兩個類之間的距離,在這裡也就是樣本與樣本之間的相似度(本質還是計算類與類之間的距離)。
(2)尋找各個類之間最近的兩個類,把它們歸為一類(這樣,類的總數就減少了一個)
(3)重新計算新生成的這個類與各個舊類之間的距離(相似度)
(4)重複(2)(3)步,直到所有的樣本都歸為一類,結束。
2、詳細描述:
整個聚類過程其實是建立了一棵樹,在建立過程中,可以通過第二步上設定一個閾值,當最近的兩個類的距離大於這個閾值,則認為迭代終止
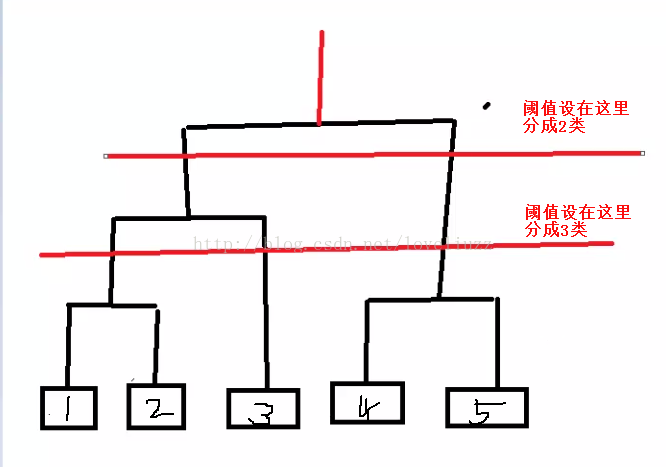
另外,關鍵的一步是第三步,如何判斷兩個類之間的相似度有不少種方法,下面介紹三種:
(1)SingleLinkage:又叫做nearest-neighbor,就是取兩個類中最近的兩個樣本之間的距離作為兩個集合的距離,即:最近的兩個樣本之間的距離越小,
這兩個類之間相似度越大,容易造成一種叫做Chaining的效果,兩個類明明從“大局”上離的比較遠,但由於其中個別點距離比較近就被合併了。
這種合併之後Chaining效應會進一步擴大,最後得到比較鬆散的聚類cluster。
(2)Complete Linkage:完全是SingleLinkage的反面極端,取兩個集合距離最遠的兩個點的距離作為兩個集合的距離
兩個聚類cluster即使已經很接近了,但是隻要有不配合的帶你存在,就頑固到底,老死不相合並,也是不太好的辦法,這兩種相似度定義方法共同問題就是:
只考慮了某個特有的資料,而沒有考慮類資料整體的特點。
(3)Average Linkage:這種方法就是把兩個集合中的點兩兩距離全部放在一起求平均值,相應的能得到一點合適的結果。
Average Linkage的一個變種就是取兩兩距離的中值,與取平均值相比更加能夠解除個別偏離樣本對結果的干擾。