
層次聚類(Hierarchical Clustering)
阿新 • • 發佈:2018-12-08
1、 層次聚類演算法概述
層次聚類演算法通過將資料組織成若干組並形成一個相應的樹狀圖來進行聚類, 它又可以分為兩類, 即自底向上的聚合層次聚類和自頂向下的分解層次聚類。聚合聚類的策略是先將每個物件各自作為一個原子聚類, 然後對這些原子聚類逐層進行聚合, 直至滿足一定的終止條件;後者則與前者相反, 它先將所有的物件都看成一個聚類, 然後將其不斷分解直至滿足終止條件。
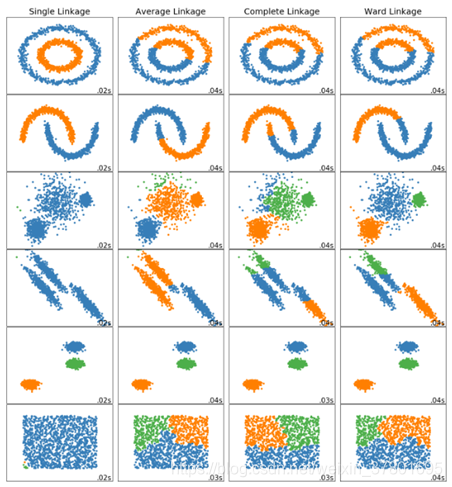
對於聚合聚類演算法來講, 根據度量兩個子類的相似度時所依據的距離不同, 又可將其分為基於Single-Link, Complete-Link, Average-Link,Ward的聚合聚類。
Single Linkage
Complete Linkage:將兩個點集中距離最遠的兩個資料點間的距離作為這兩個點集的距離。
上述兩種方法容易受到極端值的影響,計算大樣本集效率較高。
Average Linkage:計算兩個點集中的每個資料點與其他所有資料點的距離。將所有距離的均值作為兩個點集間的距離。這種方法計算量比較大,不過這種度量方法更合理。
Ward:最小化簇內方差。
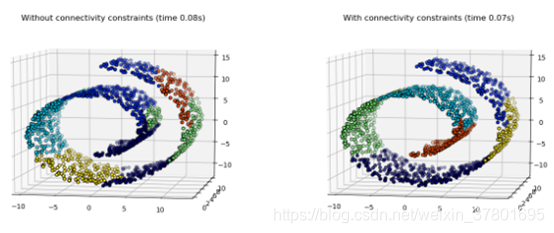
2、 連線線約束(connectivity constraints )
連線性約束是對區域性結構進行約束,可以加速演算法的執行速度,改善rich get richer現象
3、 Birch(Balanced Iterative Reducing and Clustering Using Hierarchies)
BIRCH演算法全稱利用層次方法的平衡迭代規約和聚類,比較適合於資料量大,類別數K也比較多的情況,它執行速度很快,只需要單遍掃描資料集就能進行聚類
參考連結
https://scikit-learn.org/stable/modules/clustering.html#clustering
https://en.wikipedia.org/wiki/Ward's_method
https://blog.csdn.net/felaim/article/details/76668060
https://blog.csdn.net/qq_39388410/article/details/78240037