
機器學習——K-均值聚類(K-means)演算法
一 K-均值聚類(K-means)概述
-
聚類
“類”指的是具有相似性的集合。聚類是指將資料集劃分為若干類,使得類內之間的資料最為相似,各類之間的資料相似度差別儘可能大。聚類分析就是以相似性為基礎,對資料集進行聚類劃分,屬於無監督學習。
-
無監督學習和監督學習
上一篇對KNN進行了驗證,和KNN所不同,K-均值聚類屬於無監督學習。那麼監督學習和無監督學習的區別在哪兒呢?監督學習知道從物件(資料)中學習什麼,而無監督學習無需知道所要搜尋的目標,它是根據演算法得到資料的共同特徵。比如用分類和聚類來說,分類事先就知道所要得到的類別,而聚類則不一樣,只是以相似度為基礎,將物件分得不同的簇。
-
K-means
k-means演算法是一種簡單的迭代型聚類演算法,採用距離作為相似性指標,從而發現給定資料集中的K個類,且每個類的中心是根據類中所有值的均值得到,每個類用聚類中心來描述。對於給定的一個包含n個d維資料點的資料集X以及要分得的類別K,選取歐式距離作為相似度指標,聚類目標是使得各類的聚類平方和最小,即最小化:
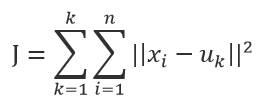
結合最小二乘法和拉格朗日原理,聚類中心為對應類別中各資料點的平均值,同時為了使得演算法收斂,在迭代過程中,應使最終的聚類中心儘可能的不變。
- 演算法流程
K-means是一個反覆迭代的過程,演算法分為四個步驟:
1) 選取資料空間中的K個物件作為初始中心,每個物件代表一個聚類中心;
2) 對於樣本中的資料物件,根據它們與這些聚類中心的歐氏距離,按距離最近的準則將它們分到距離它們最近的聚類中心(最相似)所對應的類;
3) 更新聚類中心:將每個類別中所有物件所對應的均值作為該類別的聚類中心,計算目標函式的值;
4) 判斷聚類中心和目標函式的值是否發生改變,若不變,則輸出結果,若改變,則返回2)。
用以下例子加以說明:

圖1:給定一個數據集;
圖2:根據K = 5初始化聚類中心,保證 聚類中心處於資料空間內;
圖3:根據計算類內物件和聚類中心之間的相似度指標,將資料進行劃分;
圖4:將類內之間資料的均值作為聚類中心,更新聚類中心。
最後判斷演算法結束與否即可,目的是為了保證演算法的收斂。
二 python實現
首先,需要說明的是,我採用的是python2.7,直接上程式碼:
#k-means演算法的實現
#-*-coding:utf-8 -*-
from numpy import *
from math import sqrt
import sys
sys.path.append("C:/Users/Administrator/Desktop/k-means的python實現")
def loadData(fileName):
data = []
fr = open(fileName)
for line in fr.readlines():
curline = line.strip().split('\t')
frline = map(float,curline)
data.append(frline)
return data
'''
#test
a = mat(loadData("C:/Users/Administrator/Desktop/k-means/testSet.txt"))
print a
'''
#計算歐氏距離
def distElud(vecA,vecB):
return sqrt(sum(power((vecA - vecB),2)))
#初始化聚類中心
def randCent(dataSet,k):
n = shape(dataSet)[1]
center = mat(zeros((k,n)))
for j in range(n):
rangeJ = float(max(dataSet[:,j]) - min(dataSet[:,j]))
center[:,j] = min(dataSet[:,j]) + rangeJ * random.rand(k,1)
return center
'''
#test
a = mat(loadData("C:/Users/Administrator/Desktop/k-means/testSet.txt"))
n = 3
b = randCent(a,3)
print b
'''
def kMeans(dataSet,k,dist = distElud,createCent = randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
center = createCent(dataSet,k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):
minDist = inf
minIndex = -1
for j in range(k):
distJI = dist(dataSet[i,:],center[j,:])
if distJI < minDist:
minDist = distJI
minIndex = j
if clusterAssment[i,0] != minIndex:#判斷是否收斂
clusterChanged = True
clusterAssment[i,:] = minIndex,minDist ** 2
print center
for cent in range(k):#更新聚類中心
dataCent = dataSet[nonzero(clusterAssment[:,0].A == cent)[0]]
center[cent,:] = mean(dataCent,axis = 0)#axis是普通的將每一列相加,而axis=1表示的是將向量的每一行進行相加
return center,clusterAssment
'''
#test
dataSet = mat(loadData("C:/Users/Administrator/Desktop/k-means/testSet.txt"))
k = 4
a = kMeans(dataSet,k)
print a
'''
最終的結果如下圖5和圖6:

