
Python爬蟲(入門+進階)學習筆記 2-1 爬蟲工程化及Scrapy框架初窺
本章節將會系統地介紹如何通過Scrapy框架把爬蟲工程化。本節主要內容是:簡單介紹Python和爬蟲的關係,以及將要使用的Scrapy框架的工作流程。
Python適合做爬蟲的原因
- 語言本身簡單,適合敏捷開發
- 有比較完善的工具鏈
- 足夠靈活,以應對各種突然狀況
爬蟲的知識體系
- 前端相關知識:html,css,js;瀏覽器相關知識;
- 各種資料庫的運用;
- http協議的瞭解;
- 對於前後臺聯動的方案;
爬蟲進階的工作流程
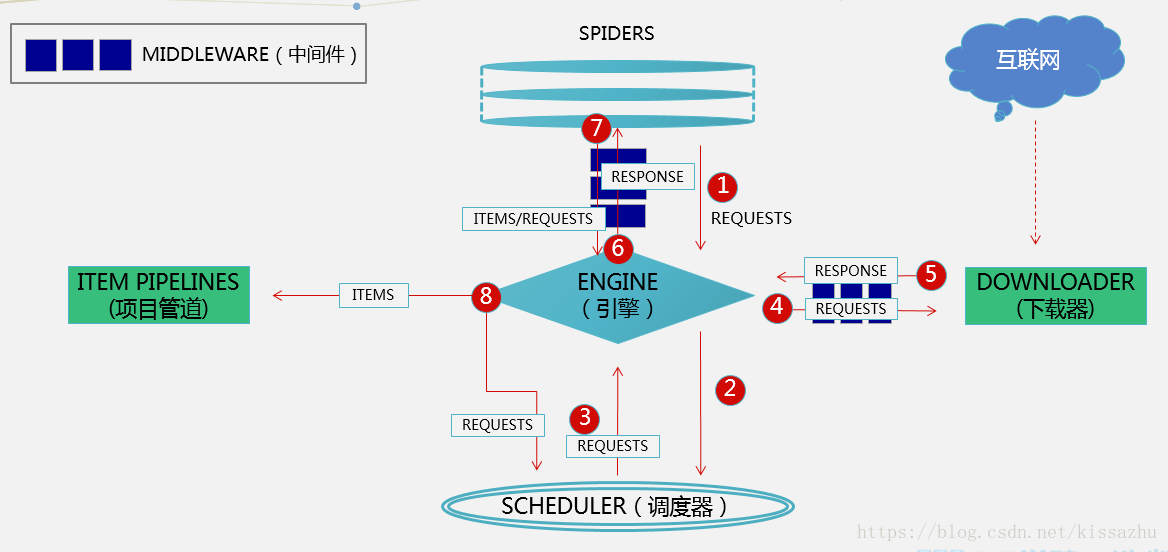
Scrapy執行流程:
- Spiders傳送第一個URL給引擎
- 引擎從Spider中獲取到第一個要爬取的URL後,在排程器(Scheduler)以Request排程
- 排程器把需要爬取的request返回給引擎
- 引擎將request通過下載中介軟體發給下載器(Downloader)去網際網路下載資料
- 一旦資料下載完畢,下載器獲取由網際網路伺服器發回來的Response,並將其通過下載中介軟體傳送給引擎
- 引擎從下載器中接收到Response並通過Spider中介軟體傳送給Spider處理
- Spider處理Response並從中返回匹配到的Item及(跟進的)新的Request給引擎
- 引擎將(Spider返回的)爬取到的Item給Item Pipeline做資料處理或者入庫儲存,將(Spider返回的)Request給排程器入佇列
- (從第三步)重複直到排程器中沒有更多的request
補充資料
什麼是Scrapy框架?
Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的應用框架。可以應用在包括資料探勘,資訊處理或儲存歷史資料等一系列的程式中。
其最初是為了頁面抓取 (更確切來說, 網路抓取 )所設計的, 也可以應用在獲取API所返回的資料(例如 Amazon Associates Web Services ) 或者通用的網路爬蟲。
使用Scrapy框架爬取資料與使用Requests+Xpath爬取資料,區別是什麼?
- 入門requests+Xpath相對來說更加簡單,更能摸清爬蟲每個詳細的步驟。當你只是簡單的爬取小量的網頁(幾千頁),而不喜歡配置Scrapy框架繁重的設定,那requests+Xpath是不可多得的利器
- requests+Xpath能夠實現的功能,scrapy也能便捷地實現。scrapy是一個功能非常強大的爬蟲框架,它不僅能便捷地構建request,還有強大的selector能夠方便地解析response
- 然而最受歡迎的還是Scrapy的效能,即抓取和解析的速度。它的downloader是多執行緒的,request是非同步排程和處理的。這兩點使它的爬取速度非常之快。另外還有內建的logging,exception,shell等模組,為爬取工作帶來了很多便利,使你的爬蟲標準化和工程化。
Scrapy這麼多元件都是幹嘛的呢?
引擎(Engine):用來處理整個系統的資料流,觸發事務(框架核心) 排程器(Scheduler):用來接受引擎發過來的請求,壓入佇列中,並在引擎再次請求的時候返回。可以想像成一個URL(抓取網頁的網址或者說是連結)的優先佇列,由它來決定下一個要抓取的網址是什麼,同時去除重複的網址 下載器(Downloader):用於下載網頁內容,並將網頁內容返回給引擎(Scrapy下載器是建立在twisted這個高效的非同步模型上的) 爬蟲(Spiders):爬蟲是主要幹活的,用於從特定的網頁中提取自己需要的資訊,即所謂的實體(Item)。也可以從中提取出連結,讓Scrapy繼續抓取下一個頁面 專案管道(Item Pipelines):負責處理爬蟲從網頁中抽取的(Item),主要的功能是持久化實體、驗證實體的有效性、清除不需要的資訊。當頁面被爬蟲解析後,將被髮送到專案管道,並經過幾個特定的次序處理資料,並儲存資料 下載器中介軟體(Downloader Middlewares):位於Scrapy引擎和下載器之間的框架,主要是處理Scrapy引擎與下載器之間的請求及響應,是進行反反爬工作的重點 爬蟲中介軟體(Spider Middlewares):介於Scrapy引擎和爬蟲之間的框架,主要工作是處理蜘蛛的響應輸入和請求輸出
開啟下一節課程之前必須掌握的Python基礎知識
1. 迭代器、生成器和yield語句
迭代器
迭代是Python最強大的功能之一,是訪問集合元素的一種方式;
迭代器是一個可以記住遍歷的位置的物件;
迭代器物件從集合的第一個元素開始訪問,直到所有的元素被訪問完結束。迭代器只能往前不會後退;
迭代器有兩個基本的方法:iter() 和 next();
字串,列表或元組物件都可用於建立迭代器;
>>>list=[1,2,3,4]
>>> it = iter(list) # 建立迭代器物件
>>> print(next(it)) # 輸出迭代器的下一個元素
1
>>> print(next(it))
2生成器
Python使用生成器對延遲操作提供了支援。所謂延遲操作,是指在需要的時候才產生結果,而不是立即產生結果。這也是生成器的主要好處。
Python有兩種不同的方式提供生成器:
- 生成器函式:常規函式定義,但是,使用
yield語句而不是return語句返回結果。yield語句一次返回一個結果,在每個結果中間,掛起函式的狀態,以便下次從它離開的地方繼續執行 - 生成器表示式:類似於列表推導,但是,生成器返回按需產生結果的一個物件,而不是一次構建一個結果列表
生成器表示式:
>>> squares = [x**2 for x in range(5)]
>>> squares
[0, 1, 4, 9, 16]
>>> squares = (x**2 for x in range(5))
>>> squares
<generator object at 0x00B2EC88>
>>> next(squares)
0
>>> next(squares)
1
>>> next(squares)
4
>>> list(squares)
[9, 16]在呼叫生成器函式執行的過程中,每次遇到 yield 時函式會暫停並儲存當前所有的執行資訊,返回yield的值。並在下一次執行 next()方法時從當前位置繼續執行
>>> def mygenerator():
... print('start...')
... yield 5
...
>>> mygenerator() //在此處呼叫,並沒有打印出start...說明存在yield的函式沒有被執行,即暫停
<generator object mygenerator at 0xb762502c>
>>> mygenerator().next() //呼叫next()即可讓函式執行.
start...
5 如果一個函式中出現多個yield,則next()會停止在下一個yield前。
>>> def fun2():
... print('first')
... yield 5
... print('second')
... yield 23
... print('end...')
...
>>> g1 = fun2()
>>> g1.next() //第一次執行,暫停在yield 5
first
5
>>> g1.next() //第二次執行,暫停在yield 23
second
23
>>> g1.next() //第三次執行,由於之後沒有yield,再次next()就會丟擲錯誤
end...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration 2. Python3 面向物件程式設計
面向物件程式設計是一種程式設計方式,此程式設計方式的落地需要使用 “類” 和 “物件” 來實現。所以,面向物件程式設計其實就是對 “類” 和 “物件” 的使用
類就是一個模板,模板裡可以包含多個函式,函式裡實現一些功能
物件則是根據模板建立的例項,通過例項物件可以執行類中的函式
面向物件三大特性
面向物件的三大特性是指:封裝、繼承和多型
1. 封裝
封裝,顧名思義就是將內容封裝到某個地方,以後再去呼叫被封裝在某處的內容。
所以,在使用面向物件的封裝特性時,需要:
- 將內容封裝到某處
- 從某處呼叫被封裝的內容
class Foo:
def __init__(self, name, age):
self.name = name
self.age = age
def detail(self):
print(self.name)
print(self.age)
obj1 = Foo('wupeiqi', 18)
obj1.detail() # Python預設會將obj1傳給self引數,即:obj1.detail(obj1),所以,此時方法內部的 self = obj1,即:self.name 是 wupeiqi ;self.age 是 18
obj2 = Foo('alex', 73)
obj2.detail() # Python預設會將obj2傳給self引數,即:obj1.detail(obj2),所以,此時方法內部的 self = obj2,即:self.name 是 alex ; self.age 是 782. 繼承
面向物件中的繼承和現實生活中的繼承相同,即:子可以繼承父的內容。
例如:
貓可以:喵喵叫、吃、喝、拉、撒
狗可以:汪汪叫、吃、喝、拉、撒
如果我們要分別為同為動物的貓和狗各建立一個類,那麼就需要為貓和狗實現它們各自具有的功能,如果使用繼承的思想,如下實現:
#定義一個“Animal”類,具有吃、喝、拉、撒的功能
class Animal:
def eat(self):
print("%s 吃 ") %self.name
def drink(self):
print("%s 喝 ") %self.name
def shit(self):
print("%s 拉 ") %self.name
def pee(self):
print("%s 撒 ") %self.name
#定義一個“Cat”類,繼承“Animal”類所有功能,同時新增屬於貓的“喵喵叫”功能
class Cat(Animal):
def __init__(self, name):
self.name = name
self.breed = '貓'
def cry(self):
print('喵喵叫')
#定義一個“Dog”類,繼承“Animal”類所有功能,同時新增屬於狗的“汪汪叫”功能
class Dog(Animal):
def __init__(self, name):
self.name = name
self.breed = '狗'
def cry(self):
print('汪汪叫')
# ######### 執行 #########
c1 = Cat('小白家的小黑貓')
c1.eat()
c2 = Cat('小黑的小白貓')
c2.drink()
d1 = Dog('胖子家的小瘦狗')
d1.eat()- 多型
Python崇尚“鴨子型別”,也就是:當看到一隻鳥走起來像鴨子、游泳起來像鴨子、叫起來也像鴨子,那麼這隻鳥就可以被稱為鴨子。在程式設計中,鴨子型別(英語:duck typing)是動態型別的一種風格。在這種風格中,一個物件有效的語義,不是由繼承自特定的類或實現特定的介面,而是由當前方法和屬性的集合決定。