Python爬蟲(入門+進階)學習筆記 1-1 什麼是爬蟲?
阿新 • • 發佈:2018-12-24
爬蟲的定義:
網路爬蟲(又被稱為網頁蜘蛛,網路機器人,在FOAF社群中間,更經常的稱為網頁追逐者),是一種按照一定的規則,自動地抓取全球資訊網資訊的程式或者指令碼。
網頁的兩種載入方法
- 同步載入:改變網址上的某些引數會導致網頁發生改變,例如:www.itjuzi.com/company?page=1(改變page=後面的數字,網頁會發生改變)
- 非同步載入:改變網址上的引數不會使網頁發生改變,例如:www.lagou.com/gongsi/(翻頁後網址不會發生變化)
認識網頁原始碼的構成
在網頁中右鍵點選檢視網頁原始碼,可以檢視到網頁的原始碼資訊。
原始碼一般由三個部分組成,分別是:
- html:描述網頁的內容結構
- css:描述網頁的排版佈局
- 描述網頁的事件處理,即滑鼠或鍵盤在網頁元素上的動作後的程式
這裡給出了三者的擴充套件知識的連結,需要大家重點關注html的構成,然後稍微瞭解下css和JavaScript在網頁構成中的作用即可。
檢視網頁請求
以chrome瀏覽器為例,在網頁上點選滑鼠右鍵,檢查(或者直接F12),選擇network,重新整理頁面,選擇ALL下面的第一個連結,這樣就可以看到網頁的各種請求資訊。
請求頭(Request Headers)資訊詳解:
Accept: text/html,image/*(瀏覽器可以接收的型別) Accept-Charset: ISO-8859-1(瀏覽器可以接收的編碼型別) Accept-Encoding: gzip,compress(瀏覽器可以接收壓縮編碼型別) Accept-Language: en-us,zh-cn(瀏覽器可以接收的語言和國家型別) Host: www.it315.org:80(瀏覽器請求的主機和埠) If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT(某個頁面快取時間) Referer: http://www.it315.org/index.jsp(請求來自於哪個頁面) User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0)(瀏覽器相關資訊) Cookie:(瀏覽器暫存伺服器傳送的資訊) Connection: close(1.0)/Keep-Alive(1.1)(HTTP請求的版本的特點) Date: Tue, 11 Jul 2000 18:23:51 GMT(請求網站的時間)
響應頭(Response Headers)資訊詳解:
Location: http://www.it315.org/index.jsp(控制瀏覽器顯示哪個頁面) Server:apache tomcat(伺服器的型別) Content-Encoding: gzip(伺服器傳送的壓縮編碼方式) Content-Length: 80(伺服器傳送顯示的位元組碼長度) Content-Language: zh-cn(伺服器傳送內容的語言和國家名) Content-Type: image/jpeg; charset=UTF-8(伺服器傳送內容的型別和編碼型別) Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT(伺服器最後一次修改的時間) Refresh: 1;url=http://www.it315.org(控制瀏覽器1秒鐘後轉發URL所指向的頁面) Content-Disposition: attachment; filename=aaa.jpg(伺服器控制瀏覽器發下載方式開啟檔案) Transfer-Encoding: chunked(伺服器分塊傳遞資料到客戶端) Set-Cookie:SS=Q0=5Lb_nQ; path=/search(伺服器傳送Cookie相關的資訊) Expires: -1(伺服器控制瀏覽器不要快取網頁,預設是快取) Cache-Control: no-cache(伺服器控制瀏覽器不要快取網頁) Pragma: no-cache(伺服器控制瀏覽器不要快取網頁) Connection: close/Keep-Alive(HTTP請求的版本的特點) Date: Tue, 11 Jul 2000 18:23:51 GMT(響應網站的時間)
理解網頁請求過程
從瀏覽器輸入網址、回車後,到使用者看到網頁內容,經過的步驟如下:
(1)dns解析,獲取ip地址;
(2)建立TCP連線,3次握手;
(3)傳送HTTP請求報文;
(4)伺服器接收請求並作處理;
(5)伺服器傳送HTTP響應報文;
(6)斷開TCP連線,4次握手。
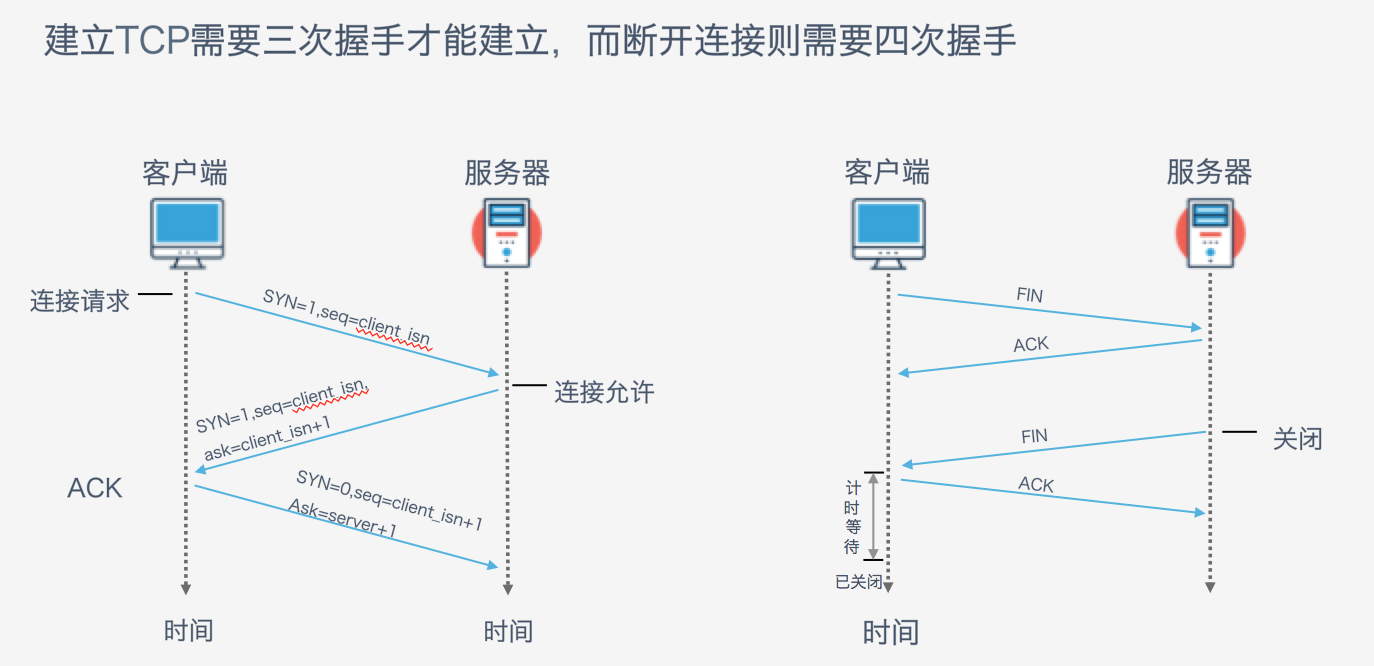
這裡需要大家回憶起計算機網路中學到的相關知識,主要是http請求的相關內容,重點了解下TCP三次握手的一個流程,閱讀 網頁http請求的整個過程,理解下網頁的請求過程。
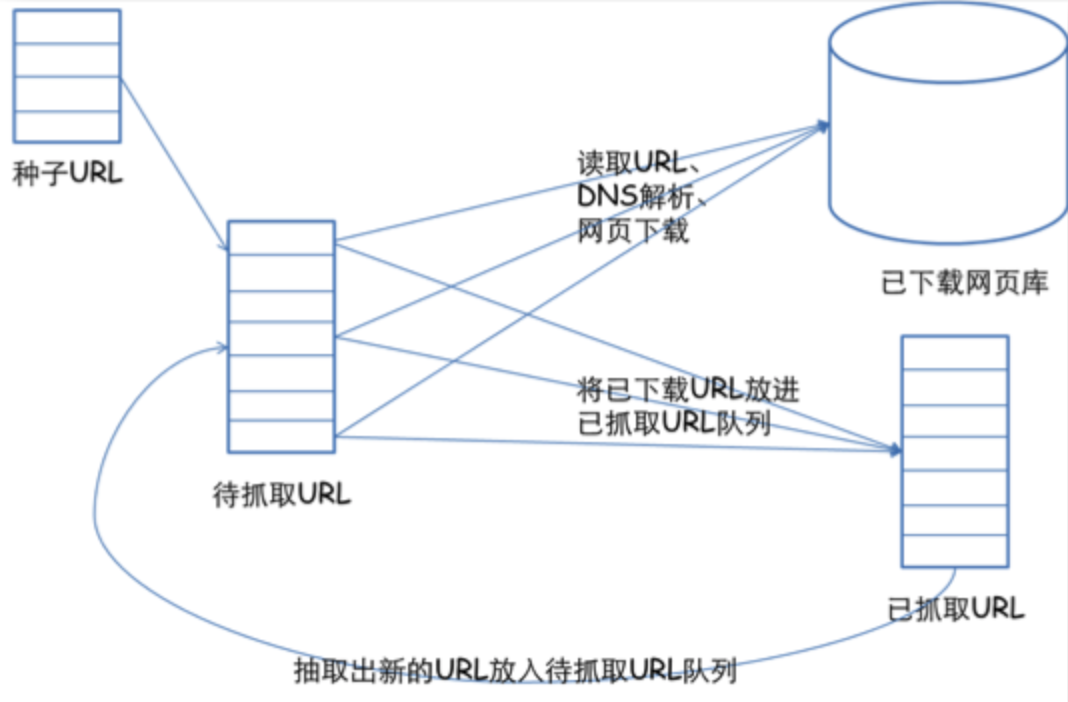
通用的網路爬蟲框架
1.挑選種子URL;
2.將這些URL放入待抓取的URL佇列;
3.取出待抓取的URL,下載並存儲進已下載網頁庫中。此外,將這些URL放入待抓取URL佇列,從而進入下一迴圈;
4.分析已抓取佇列中的URL,並且將URL放入待抓取URL佇列,從而進入下一迴圈。