
8大排序之(五)------簡單理解 基數排序 與時間複雜度
什麼是基數排序?
(一)基數排序的思想:把待排序的整數按位分,分為個位,十位.....從小到大依次將位數進行排序。實際上分為兩個 過程:分配和收集。
分配就是:從個位開始,按位數從小到大把資料排好,分別放進0--9這10個桶中;
收集就是:依次將0-9桶中的資料放進陣列中
重複這兩個過程直到最高位
(二)過程:比如現在要排序 {400,31,53,72,6,29}
首先按個位的大小依次排序,排序結果如下:
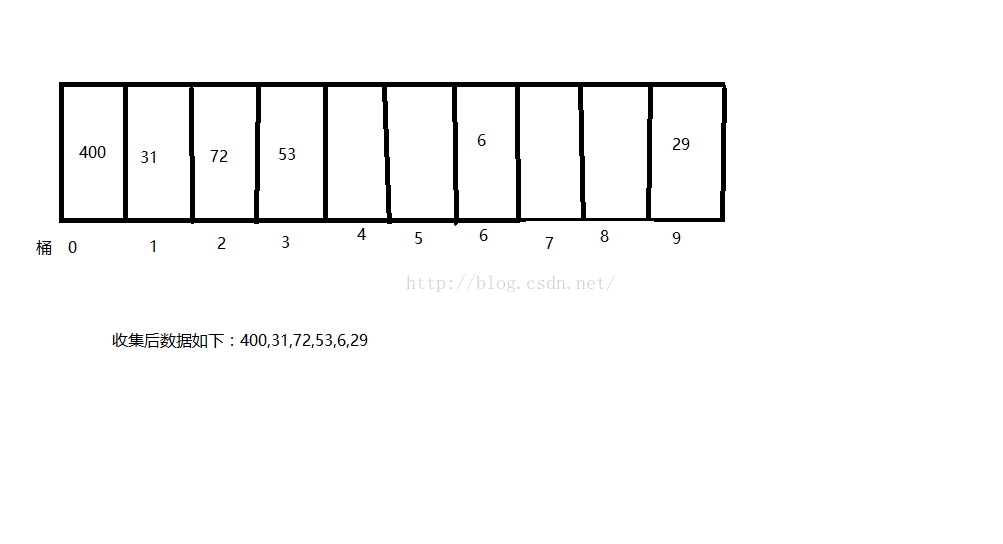
按十位進行排序,結果如下:
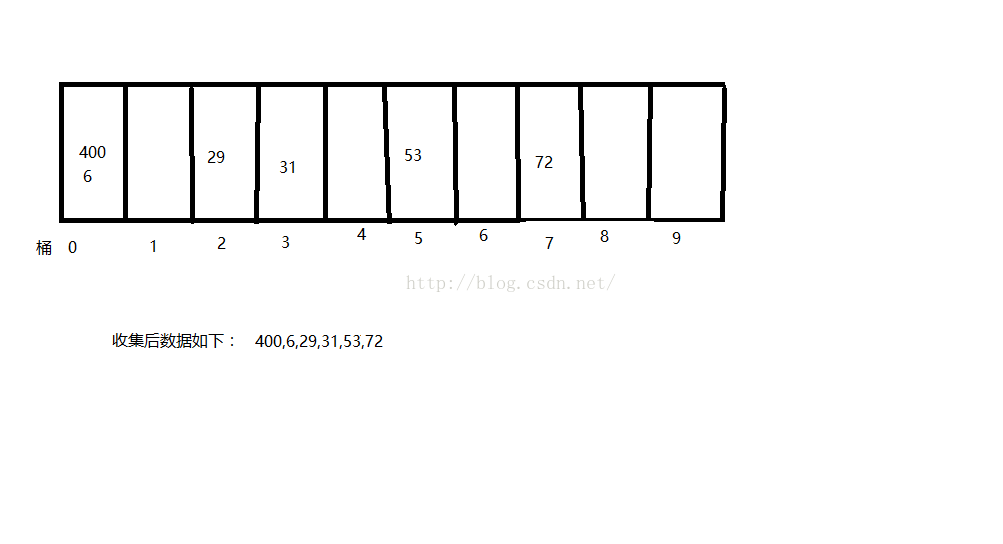
按百位排序後,結果如下:
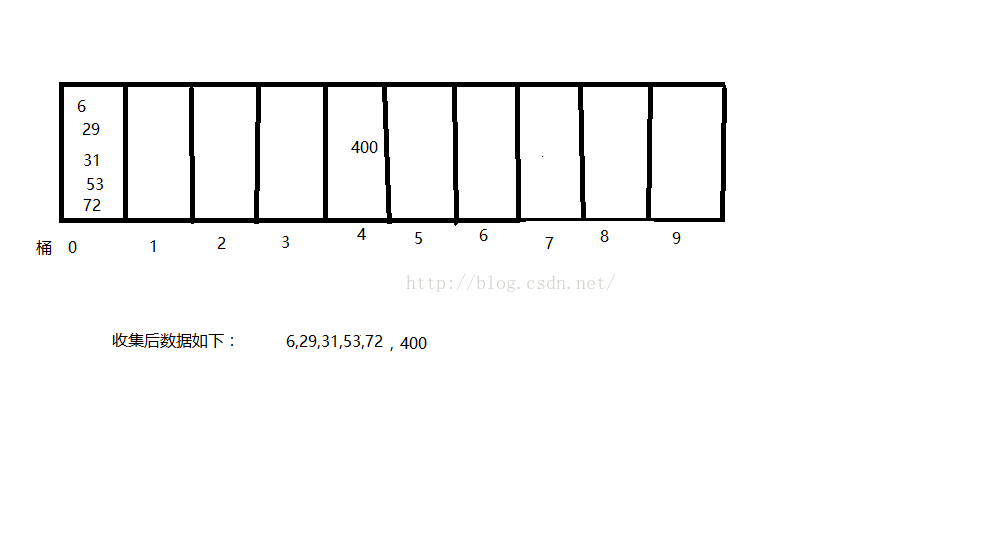
(三)程式碼如下:
(四)時間複雜度public class jishu { public static void main(String args[]) { int a [] = {400,31,53,72,6,29}; radixSort(a,10,3); for(int m = 0;m < a.length;m++){ System.out.print(a[m]+","); } } /** * @param array 待排序陣列 * @param radix 基數(10,盒子個數) * @paramdistanced 待排序中,最大的位數 * */ private static void radixSort(int[] array,int radix, int distance) { int length = array.length; int[] temp = new int[length];//用於暫存元素 int[] count = new int[radix];//用於計數排序 盒子 每一位的個 int divide = 1; for (int i = 0; i < distance; i++) { System.arraycopy(array, 0,temp, 0, length); Arrays.fill(count, 0);//盒子清空 for (int j = 0; j < length; j++) {//這個迴圈用來把每個數的個十百千位分開,並且使相對應號數的桶的個數增加1 //divide : 1 10 100 //radix : 基數 10 int tempKey = (temp[j]/divide) % radix; //temp[j]/divide 每一位的個 count[tempKey]++; //每一位的個 } //radix : 基數 10 for (int j = 1; j < radix; j++) { count [j] = count[j] + count[j-1]; } //個人覺的運用 數排序實現計數排序的重點在下面這個方法 for (int j = length - 1; j >= 0; j--) { int tempKey = (temp[j]/divide)%radix; count[tempKey]--; array[count[tempKey]] = temp[j]; } divide = divide * radix; // 1 10 100 } }
分配的時間複雜度為O(n)
收集的的時間複雜度為O(radix)
分配和收集共需要distance趟,
所以基數排序的時間複雜度為O(d(n+r))
我們可以看出,基數排序的效率和初始序列是否有序沒有關聯。

相關推薦
8大排序之(五)------簡單理解 基數排序 與時間複雜度
什麼是基數排序? (一)基數排序的思想:把待排序的整數按位分,分為個位,十位.....從小到大依次將位數進行排序。實際上分為兩個 過程:分配和收集。
Java 8 辣麼大(lambda)表示式不慌之—–(五)示例-Collectors中的統計、分組、排序等
Java 8 辣麼大(lambda)表示式不慌之—–(五)示例-Collectors中的統計、分組、排序等 summarizingInt 按int型別統計 maxBy取最大/minBy取最小 averagingInt /averagingLong/avera
8大排序之-----(3)選擇排序與時間複雜度
選擇排序與時間複雜度 (一)選擇排序的基本思想:選擇排序就是每一次從待排序的資料中選出最小的元素,放到已經排好序的資料的最後位
資料結構之排序演算法(五)-直接插入排序,希爾排序,直接選擇排序
直接插入排序:時間複雜度:O(n^2) 基本演算法思路是:把後面待排序的記錄按其關鍵字的大小逐個插入到一個已經排好序的有序序列中,直到所有記錄插完為止,得到一個新的有序序列。(無序插入前面有序) 演算
八大排序演算法之(五)氣泡排序
氣泡排序演算法原理:比較相鄰的元素。如果第一個比第二個大,就交換他們兩個。對每一對相鄰元素作同樣的工作,從開始第一對到結尾的最後一對。在這一點,最後的元素應該會是最大的數。針對所有的元素重複以上的步驟,除了最後一個。持續每次對越來越少的元素重複上面的步驟,直到沒有任何一對數
圖解排序演算法(五)之快速排序
選取一個樞紐,使它左邊的值都比它小,右邊的值比它大。(假定選陣列第一個元素值) int Partition(int* array, int low, int high) { int pivotkey; pivotkey = array[low];
Python之numpy教程(五):篩選、排序、集合函式、讀取存入資料
1.用布林型陣列進行篩選 import numpy as npimport numpy.random arr = np.random.randn(100) arr輸出100個隨機數: array([-0.84570456, -2.21743968, 2.489713
Linux kernel中斷子系統之(五):驅動申請中斷API
思路 esc 設計師 數組 還需 申請 進一步 time num 一、前言本文主要的議題是作為一個普通的驅動工程師,在撰寫自己負責的驅動的時候,如何向Linux Kernel中的中斷子系統註冊中斷處理函數?為了理解註冊中斷的接口,必須了解一些中斷線程化(threaded i
CSS+div左中右經典布局之(五)
doc src png .com image border blog ack alt <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <titl
kubernetes 1.8 高可用安裝(五)
k8s 1.8 calico 網絡5安裝網絡組件calico安裝前需要確認kubelet配置是否已經增加--network-plugin=cni如果沒有配置就加到kubelet配置文件裏Environment="KUBELET_NETWORK_ARGS=--network-plugin=cni --cni-
Linux(centos 7)系列之(五)----maven的安裝和配置
最近需要做個Jenkins的自動部署,因此需要在伺服器上配置maven,下面是我的配置過程: 1.切換你要存放壓縮包的資料夾 2.選擇線上安裝 wget http://mirror
大資料之(6)hbase2.1.1版本全分散式安裝及使用
一、Hadoop安裝 具體請參見 https://blog.csdn.net/u011095110/article/details/83791734 二、Zookeeper分散式叢集安裝 1.Zookeeper下載 #進入hadoop主目錄 cd /hadoop #下載z
大資料之(4)Hadoop生態系統體系架構及基本概念
一、基本概念 機架:HDFS叢集,由分佈在多個機架上的大量DataNode組成,不同機架之間節點通過交換機通訊,HDFS通過機架感知策略,使NameNode能夠確定每個DataNode所屬的機架ID,使用副本存放策略,來改進資料的可靠性、可用性和網路頻寬的利用率。 資料塊(blo
大資料之(3)Hadoop環境MapReduce程式驗證及hdfs常用命令
一、MapReduce驗證 本地建立一個test.txt檔案 vim test.txt 輸入一些英文句子如下: Beijing is the capital of China I love Beijing I love China 上傳test.txt
大資料之(2)修改Hadoop叢集日誌目錄,資料存放目錄
Hadoop有時會有unhealthy Node不健康的非Active節點存產生,具體錯誤內容如下。 一、錯誤內容 -== log-dirs usable space is below configured utilization percentage/no more usabl
大資料之(1)Centos7上搭建全分散式Hadoop叢集
本文介紹搭建一個Namenode兩個DataNode的Hadoop全分散式叢集的全部步驟及方法。具體環境如下: 一、環境準備 3個Centos7虛擬機器或者3個在一個區域網內的實際Centos7機器,機器上已安裝JDK1.8,至於不會安裝Centos7或者JDK1.8的同
Python資料處理之(五)numpy基礎運算2
通過上一節的學習,我們可以瞭解到一部分矩陣中元素的計算和查詢操作。然而在日常使用中,對應元素的索引也是非常重要的。依然,讓我們先從一個指令碼開始 : >>> import numpy as np >>> A=np.arange(2,14).resh
八大排序演算法(五)——快速排序
快速排序可能是應用最廣泛的排序演算法。快速排序流行的原因是因為它實現簡單、適用於各種不同的輸入資料且在一般應用中比其他排序演算法都要快的多。快速排序的特點包括它是原地排序(只需要一個很小的輔助棧),且將長度為n的陣列排序所需的時間和nlogn成正比。快速排序的內迴圈比大多數排序演算法都要短小,這
關於SpringCloud微服務雲架構構建B2B2C電子商務平臺之-(五)路由閘道器(zuul)
在微服務架構中,需要幾個基礎的服務治理元件,包括服務註冊與發現、服務消費、負載均衡、斷路器、智慧路由、配置管理等,由這幾個基礎元件相互協作,共同組建了一個簡單的微服務系統。一個簡答的微服務系統如下圖: 注意:A服務和B服務是可以相互呼叫的,作圖的時候忘記了。並且配置服務也是註冊到服
關於SpringCloud微服務雲架構構建B2B2C電子商務平臺之-(五)路由網關(zuul)
href xmlns zoom col 研究 簡單 strip -c ins 在微服務架構中,需要幾個基礎的服務治理組件,包括服務註冊與發現、服務消費、負載均衡、斷路器、智能路由、配置管理等,由這幾個基礎組件相互協作,共同組建了一個簡單的微服務系統。一個簡答的微服務系統如下