
大資料之(4)Hadoop生態系統體系架構及基本概念
一、基本概念
機架:HDFS叢集,由分佈在多個機架上的大量DataNode組成,不同機架之間節點通過交換機通訊,HDFS通過機架感知策略,使NameNode能夠確定每個DataNode所屬的機架ID,使用副本存放策略,來改進資料的可靠性、可用性和網路頻寬的利用率。
資料塊(block):HDFS最基本的儲存單元,預設為64M,使用者可以自行設定大小。
元資料:指HDFS檔案系統中,檔案和目錄的屬性資訊。HDFS實現時,採用了 映象檔案(Fsimage) + 日誌檔案(EditLog)的備份機制。檔案的映象檔案中內容包括:修改時間、訪問時間、資料塊大小、組成檔案的資料塊的儲存位置資訊。目錄的映象檔案內容包括:修改時間、訪問控制權限等資訊。日誌檔案記錄的是:HDFS的更新操作。
NameNode啟動的時候,會將映象檔案和日誌檔案的內容在記憶體中合併。把記憶體中的元資料更新到最新狀態。
使用者資料:HDFS儲存的大部分都是使用者資料,以資料塊的形式存放在DataNode上。
Hadoop是一個能夠對大量資料進行分散式處理的軟體框架,以一種可靠、高效、可伸縮的方式進行資料處理,其有許多元素構成,以下是其組成元素:
-
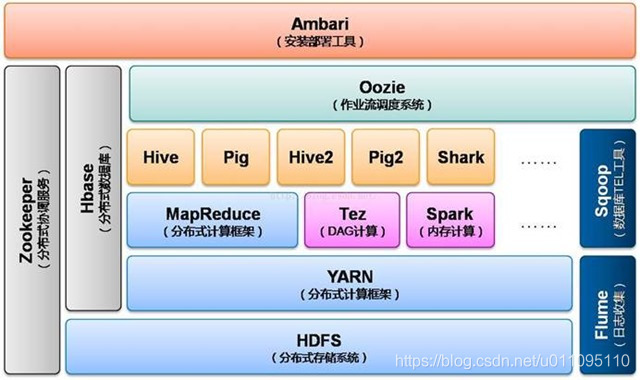
Hadoop Common:Hadoop體系最底層的一個模組,為Hadoop各子專案提供各種工具,如:配置檔案和日誌操作等。
-
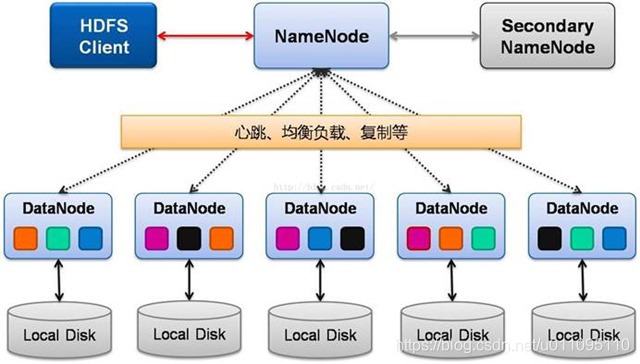
HDFS:分散式檔案系統,提供高吞吐量的應用程式資料訪問,對外部客戶機而言,HDFS 就像一個傳統的分級檔案系統。可以建立、刪除、移動或重新命名檔案,等等。但是 HDFS 的架構是基於一組特定的節點構建的(參見圖 1),這是由它自身的特點決定的。這些節點包括 NameNode(僅一個),它在 HDFS 內部提供元資料服務;DataNode,它為 HDFS 提供儲存塊。由於僅存在一個 NameNode,因此這是 HDFS 的一個缺點(單點失敗)。
儲存在 HDFS 中的檔案被分成塊,然後將這些塊複製到多個計算機中(DataNode)。這與傳統的 RAID 架構大不相同。塊的大小(通常為 64MB)和複製的塊數量在建立檔案時由客戶機決定。NameNode 可以控制所有檔案操作。HDFS 內部的所有通訊都基於標準的 TCP/IP 協議。
-
MapReduce:一個分散式海量資料處理的軟體框架集計算叢集。
-
Avro :doug cutting主持的RPC專案,主要負責資料的序列化。有點類似Google的protobuf和Facebook的thrift。avro用來做以後hadoop的RPC,使hadoop的RPC模組通訊速度更快、資料結構更緊湊。
-
Hive :類似CloudBase,也是基於hadoop分散式計算平臺上的提供data warehouse的sql功能的一套軟體。使得儲存在hadoop裡面的海量資料的彙總,即席查詢簡單化。hive提供了一套QL的查詢語言,以sql為基礎,使用起來很方便。
-
HBase :基於Hadoop Distributed File System,是一個開源的,基於列儲存模型的可擴充套件的分散式資料庫,支援大型表的儲存結構化資料。
-
Pig :是一個平行計算的高階的資料流語言和執行框架 ,SQL-like語言,是在MapReduce上構建的一種高階查詢語言,把一些運算編譯進MapReduce模型的Map和Reduce中,並且使用者可以定義自己的功能。
-
ZooKeeper:Google的Chubby一個開源的實現。它是一個針對大型分散式系統的可靠協調系統,提供的功能包括:配置維護、名字服務、分散式同步、組服務等。ZooKeeper的目標就是封裝好複雜易出錯的關鍵服務,將簡單易用的介面和效能高效、功能穩定的系統提供給使用者。
-
Chukwa :一個管理大型分散式系統的資料採集系統 由yahoo貢獻。
-
Cassandra:無單點故障的可擴充套件的多主資料庫
-
Mahout :一個可擴充套件的機器學習和資料探勘庫
在HDFS中,NameNode 和 DataNode之間使用TCP協議進行通訊。DataNode每3s向NameNode傳送一個心跳。每10次心跳後,向NameNode傳送一個數據塊報告自己的資訊,通過這些資訊,NameNode能夠重建元資料,並確保每個資料塊有足夠的副本。
二、Hadoop2.x體系架構
- 後臺程序:NameNode(名稱節點)
1,他是HDFS的守護程式,是HDFS的核心程式,它起到這個分散式檔案系統的總控的作用。
2,記錄資料是如何分割成資料塊的,以及這些資料塊被儲存在哪些節點上(分散式)。
3,對記憶體和IO進行集中的管理。當用戶跟整個hadoop的叢集打交道的時候,一般首先會訪問NameNode來獲得他要的檔案的分佈狀態的資訊,也就是說先找出需要的檔案是在哪些資料節點裡面,然後使用者再跟資料節點打交道,把資料拿到手。所以NameNode在整個Hadoop中起到一個核心的功能。
4,但是,Hadoop一直以來都是把NameNode作為一個單點,也就是整個hadoop中只有一個 NameNode伺服器,所以一旦NameNode節點發生故障,將使整個叢集崩潰。
- 後臺程序:Secondary NameNode(輔助名稱節點)
主要作為NameNode的後備,它可以將NameNode中的元資料資訊再多儲存一份副本,也就是說NameNode會不斷跟Secondary NameNode通訊,不斷把它裡面的資料往輔助名稱節點這邊放。一旦NameNode崩潰了,我們可以用Secondary NameNode去代替它。保護叢集的執行。但是現在還不能實現二者之間的自動切換,也就是說,現在不能在NameNode倒下以後,自動將Secondary NameNode啟動起來,必須手工做。所以在hadoop中,NameNode還是一個事實上的單點。
1,監控HDFS狀態的輔助後臺程式。
2,每個叢集都有一個。
3,與NameNode進行通訊,定期儲存HDFS元資料快照。
4,當NameNode故障,可以作為備用NameNode使用。
- 後臺程序:DataNode(資料節點)
執行在各個子節點裡面。一般放在從伺服器上,負責檔案系統的具體的資料塊的讀寫。
1,每個伺服器都執行一個。
2,負責把HDFS資料塊讀寫到本地檔案系統。
- 總結
-
【Active Namenode】:主 Master(只有一個),管理 HDFS 的名稱空間,管理資料塊對映資訊;配置副本策略;處理客戶端讀寫請求
-
【Secondary NameNode】:NameNode 的熱備;定期合併 fsimage 和 fsedits,推送給 NameNode;當 Active NameNode 出現故障時,快速切換為新的 Active NameNode。
-
【Datanode】:Slave(有多個);儲存實際的資料塊;執行資料塊讀 / 寫
-
【Client】:與 NameNode 互動,獲取檔案位置資訊;與 DataNode 互動,讀取或者寫入資料;管理 HDFS、訪問 HDFS。
三、HDFS架構
四、MapReduce架構
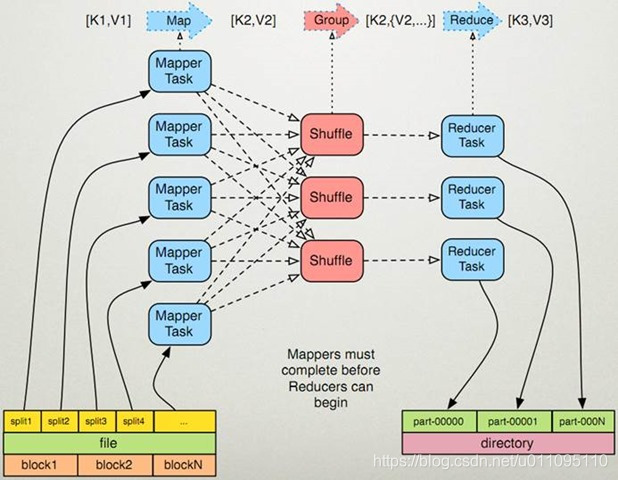
MapReduce是一種程式設計模型,用於大規模資料集的並行運算。Map(對映)和Reduce(化簡),採用分而治之思想,先把任務分發到叢集多個節點上,平行計算,然後再把計算結果合併,從而得到最終計算結果。多節點計算,所涉及的任務排程、負載均衡、容錯處理等,都由MapReduce框架完成,不需要程式設計人員關心這些內容。
使用者提交任務給JobTracer,JobTracer把對應的使用者程式中的Map操作和Reduce操作對映至TaskTracer節點中;輸入模組負責把輸入資料分成小資料塊,然後把它們傳給Map節點;Map節點得到每一個key/value對,處理後產生一個或多個key/value對,然後寫入檔案;Reduce節點獲取臨時檔案中的資料,對帶有相同key的資料進行迭代計算,然後把終結果寫入檔案。
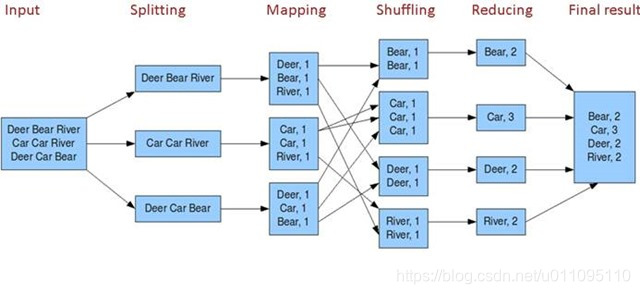
如果這樣解釋還是太抽象,可以通過下面一個具體的處理過程來理解:(WordCount例項)
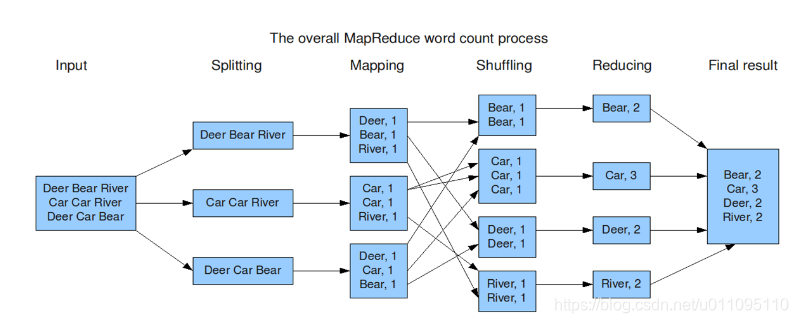
Hadoop的核心是MapReduce,而MapReduce的核心又在於map和reduce函式。它們是交給使用者實現的,這兩個函式定義了任務本身。
map函式:接受一個鍵值對(key-value pair)(例如上圖中的Splitting結果),產生一組中間鍵值對(例如上圖中Mapping後的結果)。Map/Reduce框架會將map函式產生的中間鍵值對裡鍵相同的值傳遞給一個reduce函式。
reduce函式:接受一個鍵,以及相關的一組值(例如上圖中Shuffling後的結果),將這組值進行合併產生一組規模更小的值(通常只有一個或零個值)(例如上圖中Reduce後的結果)
但是,Map/Reduce並不是萬能的,適用於Map/Reduce計算有先提條件:
(1)待處理的資料集可以分解成許多小的資料集;
(2)而且每一個小資料集都可以完全並行地進行處理;
若不滿足以上兩條中的任意一條,則不適合適用Map/Reduce模式。
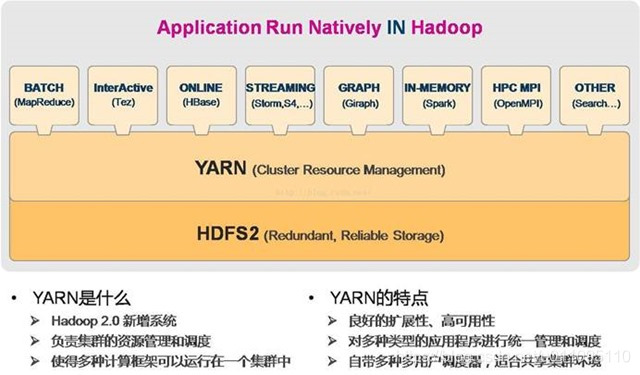
五、Yarn架構
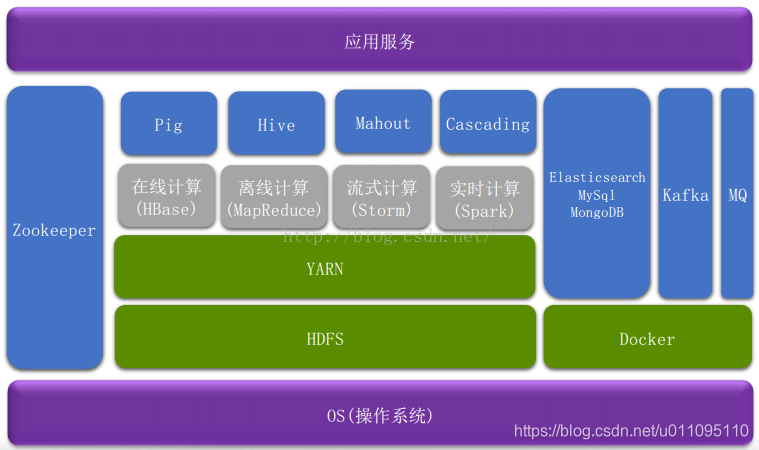
六、大資料平臺架構
七、HDFS讀寫資料流程
寫資料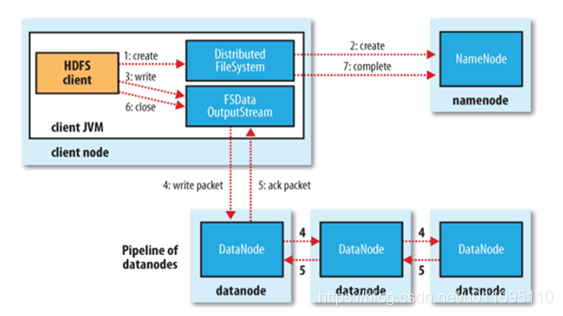
檔案寫入:
- Client向NameNode發起檔案寫入的請求
- NameNode根據檔案大小和檔案塊配置情況,返回給Client它所管理部分DataNode的資訊。
- Client將檔案劃分為多個檔案塊,根據DataNode的地址資訊,按順序寫入到每一個DataNode塊中。
讀資料
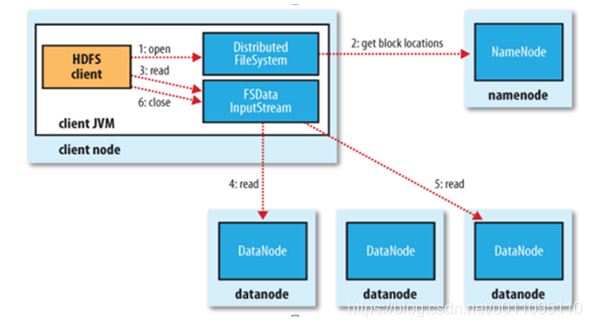
檔案讀取:
- Client向NameNode發起檔案讀取的請求
- NameNode返回檔案儲存的DataNode的資訊。
- Client讀取檔案資訊。
本文參考: