
基於圖的推薦演算法及python實現
概述
基於圖的模型(graph-based model)是推薦系統中的重要內容。
在推薦系統中,使用者行為資料可以表示成圖的形式,具體地,可以用二元組表示,其中每個二元組表示使用者對物品的產生過行為,這種資料很容易用一個二分圖表示
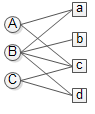
其中users集 , items集。我們用來表示上圖。,圖中的邊則是由資料集中的二元組確定。本文不考慮各邊的權重(對的興趣度),都預設為1。
與pagerank演算法的區別
有了圖之後我們要對u進行推薦物品,就轉化為計算使用者頂點u和與所有物品頂點之間的相關性,按照相關性的高低生成推薦列表。說白了,這是一個圖上的排名問題,我們最容易想到的就是Google的pageRank演算法。這裡只給出迭代公式,Pagerank演算法的具體細節在此不做贅述,具體的可以看http://blog.csdn.net/john_xyz/article/details/78915097。
上式中是網頁i的訪問概率(也就是重要度),是使用者繼續訪問網頁的概率,
與PageRank隨機選擇一個點開始遊走(也就是說從每個點開始的概率都是相同的)不同,如果我們要計算所有節點相對於使用者的相關度,則PersonalRank從使用者對應的節點開始遊走,每到一個節點都以的概率停止遊走並從重新開始,或者以的概率繼續遊走,從當前節點指向的節點中按照均勻分佈隨機選擇一個節點往下游走。這樣經過很多輪遊走之後,每個頂點被訪問到的概率也會收斂趨於穩定,這個時候我們就可以用概率來進行排名了。

在執行演算法之前,我們需要初始化每個節點的初始概率值。如果我們對使用者
Python程式碼實現
分別用兩種方式實現PersonalRank演算法,一種是用純粹的for迴圈去做,另外一種是用矩陣乘法。對於大規模稀疏矩陣,使用稀疏矩陣乘法相比於for迴圈,能提高上百倍的效率。當然,如果對於大規模資料使用稠密矩陣,依然很慢。
# coding:utf-8
import numpy as np
import time
import scipy.sparse as sparse
import pandas as pd
def PersonalRank(G, alpha, root):
"""
Random walk algorithm:calculate importance of all nodes in respect to
the start_node
:param G: graph
:param alpha: probability of random walkRa
:param root: start node of random walk
:param num_iter: nums of iteration
:return: type of dict, ex.
{node1:prob1, node2:prob2,...}
"""
rank = dict()
rank = {x:0 for x in G.keys()}
rank[root] = 1
pre = np.zeros(n)
# iteration
while np.sum(abs(np.array(list(pre)) - np.array(list(rank.values())))) > 0.001:
# initialize
pre = rank.values()
tmp = {x:0 for x in G.keys()}
# 取節點i和它的出邊尾節點集合ri
for i, ri in G.items():
for j in ri:
try:
tmp[j] += alpha * rank[i] / (1.0 * len(ri))
except:
continue
tmp[root] += (1 - alpha)
rank = tmp
result = sorted(rank.items(), key=lambda x:x[1], reverse=True)[:num_candidates]
return result
def PersonalRankInMatrix(M, alpha, root):
"""
Personal Rank in matrix formation
:param M: transfer probability matrix
:param index2node: index2node dictionary
:param node2index: node2index dictionary
:return:type of list of tuple, ex.
[(node1, prob1),(node2, prob2),...]
"""
result = dict()
v = np.zeros(n)
v[node2index[root]] = 1
v0 = v
while np.sum(abs(v - (alpha*M.dot(v) + (1-alpha)*v0))) > 0.001:
v = alpha * M.dot(v) + (1-alpha)*v0
for ind, prob in enumerate(v):
result[index2node[ind]] = prob
result = sorted(result.items(), key=lambda x:x[1], reverse=True)[:num_candidates]
return result
def Generate_Transfer_Matrix(G):
"""generate transfer matrix given graph"""
index2node = dict()
node2index = dict()
for index,node in enumerate(G.keys()):
node2index[node] = index
index2node[index] = node
# num of nodes
n = len(node2index)
# generate Transfer probability matrix, shape of (n,n)
M = np.zeros([n,n])
for node1 in G.keys():
for node2 in G[node1]:
# FIXME: some nodes not in the Graphs.keys, may incur some errors
try:
M[node2index[node2],node2index[node1]] = 1/len(G[node1])
except:
continue
return M, node2index, index2node
def Generate_Transfer_SparseMatrix(G):
"""
generate transfer sparse matrix given graph
:param G: graph, type of dict
:return: transfer matrix, type of 'scipy.sparse.coo.coo_matrix'
"""
index2node = dict()
node2index = dict()
for index,node in enumerate(G.keys()):
node2index[node] = index
index2node[index] = node
# num of nodes
n = len(node2index)
# initialize rows and columns
rows = []
columns = []
data = []
# generate Transfer probability Sparse matrix, shape of (n,n)
for node1 in G.keys():
for node2 in G[node1]:
# FIXME: some nodes not in the Graphs.keys, may incur some errors
try:
rows.append(node2index[node2])
columns.append(node2index[node1])
data.append(1/len(G[node1]))
except:
continue
rows = np.array(rows)
columns = np.array(columns)
data = np.array(data)
M = sparse.coo_matrix((data, (rows,columns)),shape=(n,n))
return M, node2index, index2node
# test algorithm performance
if __name__ == '__main__':
alpha = 0.85
root = 'A'
num_iter = 100
num_candidates = 10
G = {'A' : {'a' : 1, 'c' : 1},
'B' : {'a' : 1, 'b' : 1, 'c':1, 'd':1},
'C' : {'c' : 1, 'd' : 1},
'a' : {'A' : 1, 'B' : 1},
'b' : {'B' : 1},
'c' : {'A' : 1, 'B' : 1, 'C':1},
'd' : {'B' : 1, 'C' : 1}}
M, node2index, index2node = Generate_Transfer_SparseMatrix(G)
n = len(M)
print(pd.DataFrame(M, index=G.keys(), columns=G.keys()))
time1 = time.time()
result1 = PersonalRank(G, alpha, root)
time2 = time.time()
result2 = PersonalRankInMatrix(M, alpha, root)
time3 = time.time()
print(result1)
print(result2)
print(time2 - time1, time3 - time2)
關於稀疏矩陣的思考
在python中,可以藉助官方庫scipy.sparse和numpy中的dot和實現稀疏矩陣和稠密矩陣的相乘,具體如下
import numpy as np
import scipy.sparse as sparse
r=np.array([0,3,1,2,6,3,6,3,4])
c=np.array([0,0,2,2,2,4,5,6,3])
data=np.array([1,1,1,1,1,1,1,1,1])
a = np.ones(7)
sparse_matrix =sparse.coo_matrix((data, (r,c)), shape=(7,7))
print(sparse_matrix)
print(sparse_matrix.todense())
M = sparse_matrix.dot(a)
print(M)reference
相關推薦
基於圖的推薦演算法及Python實現(PersonalRank)
使用隨機遊走演算法PersonalRank實現基於圖的推薦。 二部圖 在推薦系統中,使用者行為資料可以表示成圖的形式,具體來說是二部圖。使用者的行為資料集由一個個(u,i)二元組組成,表示為使用者u對物品i產生過行為。本文中我們認為使用者對他產生過行為的物品的興
基於圖的推薦演算法及python實現
概述 基於圖的模型(graph-based model)是推薦系統中的重要內容。 在推薦系統中,使用者行為資料可以表示成圖的形式,具體地,可以用二元組(u,i)(u,i)表示,其中每個二元組(u,i)(u,i)表示使用者uu對物品ii的產生過行為,這種資料
推薦系統學習--基於item的協同過濾演算法及python實現
轉載地址:http://blog.csdn.net/gamer_gyt/article/details/51346159 1:協同過濾演算法簡介 2:協同過濾演算法的核心 3:協同過濾演算法的應用方式 4:基於使用者的協同過濾演算法實現
KNN演算法及python實現
KNN演算法原理和python實現 K最近鄰(kNN,k-NearestNeighbor)分類演算法是資料探勘分類技術中最簡單的方法之一。 原理是:如果一個樣本在特徵空間中的k個最相鄰的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別,並具有這個類別上樣本的
k-means演算法及python實現
本篇文章主要講解聚類分析中的一種常用的演算法k-means,它的全稱叫作k均值演算法。 k-means原理 k-means演算法是一種基於原型的、劃分的聚類技術。 基於原型可以理解為基於質心,也就是說,每個物件到定義該簇質心的距離比到其他簇質心的距離更近。當質心沒有意義
凸包問題的Graham-Scan演算法及python實現
基於 Graham-Scan 的凸包求解演算法是在列舉三角形時,採用了更精細的方式,將P_0作為極點,通過極角大小定位最右下側的三角形∆P_0 P_1 P_2,然後讓三角形繞P_0點旋轉,掃描所有輸入點,直到到最左下側為止。 首先要對點集S進行預處理,
關聯規則,Apriori演算法及python實現
1 關聯規則 關聯分析一個典型的例子是購物籃分析,廣泛應用於零售業,通過檢視那些商品經常在一起購買,可以幫助商店瞭解使用者的購買行為。一個最有名的例子是“尿布與啤酒”,據報道,美國中西部的一家連鎖店發現,男人們會在週四購買尿布和啤酒,這樣商家實際上就可以將尿布
梯度下降演算法及python實現(學習筆記)
梯度下降(Gradient Descent)演算法是機器學習中使用非常廣泛的優化演算法。當前流行的機器學習庫或者深度學習庫都會包括梯度下降演算法的不同變種實現。 本文主要以線性迴歸演算法損失函式求極小值來說明如何使用梯度下降演算法並給出python實現。若有不正確的地方,希
機器學習-簡單的K最近鄰演算法及python實現
根據前人的成果進行了學習 https://www.cnblogs.com/ahu-lichang/p/7161613.html#commentform 1、演算法介紹 其實k最近鄰演算法算是聚類演算法中最淺顯易懂的一種了,考慮你有一堆二維資料,你想很簡單的把它分開,像下圖這
機器學習——感知器演算法及python實現
說明:本文從自己的理解出發來講解感知器是如何訓練的,如想知道比較學術的概念,請查閱相關論文。 1、什麼是感知器 本文假設資料為:二維二類、線性可分 感知器就是一個分類器,如:給兩類資料做訓練集A,B,訓練完成之後,給定一個測試資料,通過感知器,可以分成A或B。 因為資料是二
最大公約數歐幾里德演算法及Python實現
歐幾里德演算法又稱輾轉相除法,用於計算兩個整數m, n的最大公約數。其計算原理依賴於下面的定理: gcd(m, n) = gcd(n, m mod n)這個定理的意思是:整數m、n的最大公約數等於n和m除以n的餘數的最大公約數。 例如:有兩個整數:120和45,我們按照
凸包問題的分治演算法及python實現
利用分治思想處理凸包問題。 劃分:將點集S中的資料按橫座標排序,選出橫座標最小的點A和縱座標最小的點B,AB的連線將S劃分為兩個子集,位於(AB) 上方的集合S1和位於(BA) 上方的集合S2。 遞迴求解:遞迴呼叫演算法求S1的凸包和S2的凸包,遞迴演算
FFM演算法解析及Python實現
1. 什麼是FFM? 通過引入field的概念,FFM把相同性質的特徵歸於同一個field,相當於把FM中已經細分的feature再次進行拆分從而進行特徵組合的二分類模型。 2. 為什麼需要FFM? 在傳統的線性模型中,每個特徵都是獨立的,如果需要考慮特徵與特徵之間的相互作用,可能需要人工對特徵進行交叉
K近鄰演算法(KNN)原理解析及python實現程式碼
KNN演算法是一個有監督的演算法,也就是樣本是有標籤的。KNN可以用於分類,也可以用於迴歸。這裡主要講knn在分類上的原理。KNN的原理很簡單: 放入一個待分類的樣本,使用者指定k的大小,然後計算所有訓練樣本與該樣
邏輯迴歸演算法推導及Python實現
寫在前面: 1、好多邏輯迴歸的演算法推導要麼直接省略,要麼寫的比較難以看懂,比如寫成矩陣求導,繁難難懂,本文進行推導,會鏈式求導法則應當就能看懂 2、本文參考若干文章,寫在附註處,如果參考未寫引用,還望提出 2、本文後續可能不定時更新,如有錯誤,歡迎提出 一、最大似
DeepFM演算法解析及Python實現 FFM演算法解析及Python實現 FM演算法解析及Python實現 詞嵌入的那些事兒(一)
1. DeepFM演算法的提出 由於DeepFM演算法有效的結合了因子分解機與神經網路在特徵學習中的優點:同時提取到低階組合特徵與高階組合特徵,所以越來越被廣泛使用。 在DeepFM中,FM演算法負責對一階特徵以及由一階特徵兩兩組合而成的二階特徵進行特徵的提取;DNN演算法負責對由輸入的一階特徵進行全連線
SVM演算法原理及Python實現
Svm(support Vector Mac)又稱為支援向量機,是一種二分類的模型。當然如果進行修改之後也是可以用於多類別問題的分類。支援向量機可以分為線性核非線性兩大類。其主要思想為找到空間中的一個更夠將所有資料樣本劃開的超平面,並且使得本本集中所有資料到這個超平面的距離最
GBDT+LR演算法解析及Python實現
1. GBDT + LR 是什麼 2. GBDT + LR 用在哪 GBDT+LR 使用最廣泛的場景是CTR點選率預估,即預測當給使用者推送的廣告會不會被使用者點選。 一個典型的CTR流程如下圖所示: 如上圖,主要包括兩大部分:離線部分、線上部分,其中離線部分目標主要是訓練出可用模型,而線上部分則考慮模型
K-means演算法及python sklearn實現
目錄 前言 例項推演 K值的確定 輪廓係數 K-means演算法 前言 根據訓練樣本是否包含標籤資訊,機器學習可以分為監督學習和無監督學習。聚類演算法是典型的無監督學習,其訓練樣本中只包含樣本特徵,不包含樣本的標
歐幾里得演算法證明及python實現
1.歐幾里得演算法: 歐幾里得演算法又稱輾轉相除法,是求兩個整數的最大公約數非常有效的演算法,具體內容是:兩個整數的最大公約數等於其中較小的那個數和兩數相除餘數的最大公約數。 2.歐幾里得演算法證明 : a可以表示成a