
機器學習——感知器演算法及python實現
阿新 • • 發佈:2019-01-08
說明:本文從自己的理解出發來講解感知器是如何訓練的,如想知道比較學術的概念,請查閱相關論文。
1、什麼是感知器
本文假設資料為:二維二類、線性可分
感知器就是一個分類器,如:給兩類資料做訓練集A,B,訓練完成之後,給定一個測試資料,通過感知器,可以分成A或B。
因為資料是二維線性可分的,我們不妨假設該線性方程為w0*x0+w1*x1+w2 = 0
2、如何訓練
訓練的最終結果是訓練集中A的結果在直線的一側,假設經過過濾器後其值<0; B的結果在直線的另一側經過過濾器後其值>0。
可以先給w=[w0,w1,w2]賦一個初始值如w=[1,1,1]。
如果訓練集中的點x的標籤為A,且帶入線性方程後的值<0,則當前感知器對x點分類正確,不對w 進行調整
如果訓練集中的點x的標籤為A,且帶入線性方程後的值>=0,則當前感知器對x點分類不正確,對w進行調整。
本來應該<0,但結果>=0,所以w調整原則為w =w-x。因為wx>(w-x)*x,能夠使調整後的結果變小
如果訓練集中的點x的標籤為B,且帶入線性方程後的值>0,則當前感知器對x點分類正確,不對w進行調整
如果訓練集中的點x的標籤為B,且帶入線性方程後的值<=0,則當前感知器對x點分類不正確,對w進行調整。
本來應該>0,但結果<=0,所以w調整原則為w =w+x。因為wx<(w+x)*x,能夠使調整後的結果變大
其中應為w比x多了一個維度,對x的處理方式是採用增量模式 ,即每個樣本的第三維度都為1
3、python程式碼實現
%matplotlib inline import numpy as np import matplotlib.pyplot as plt w = [1,1,1] x1 =[[1,0,1],[0,1,1],[2,0,1],[2,2,1]] x2=[[-1,-1,1],[-1,0,1],[-2,-1,1],[0,-2,1]] flag = False while flag != True: for i in range(4): t = 0 for j in range(3): t += w[j]*x1[i][j] if(t <= 0): for j in range(3): w[j] +=x1[i][j] for i in range(4): t = 0 for j in range(3): t += w[j]*x2[i][j] if(t >= 0): for j in range(3): w[j] -=x2[i][j] flag = True for i in range(4): t1 = 0 t2 = 0 for j in range(3): t1 += w[j]*x1[i][j] t2 += w[j]*x2[i][j] if (t1 <=0 ): flag =False break if(t2 >=0): flag = False break plt.figure() for i in range(4): plt.scatter(x1[i][0],x1[i][1],c = 'r',marker='o') plt.scatter(x2[i][0],x2[i][1],c = 'g',marker='*') plt.grid() p1=[-2.0,2.0] p2=[(-w[2]+2*w[0])/w[1],(-w[2]-2*w[0])/w[1]] plt.plot(p1,p2) plt.show()
4、測試結果
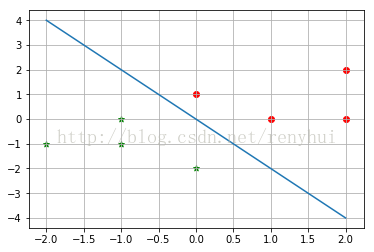
5、結果分析
該演算法對線性可分的資料進行分類,若非線性可分,會導致死迴圈