
數字語音訊號處理學習筆記——語音訊號的短時時域分析(4)
版權宣告:本文為博主原創文章,未經博主允許不得轉載。 https://blog.csdn.net/u013538664/article/details/26141939
3.7 基於能量和過零率的語音端點檢測
在複雜的應用環境下,從訊號流中分辨出語音訊號和非語音訊號,是語音處理的一個基本問題。語音端點檢測就是指從包含語音的一段訊號中確定出語音的起始點和結束點。正確的端點檢測對於語音識別和語音編碼系統都有重要的意義,它可以使採集的資料真正是語音訊號的資料,從而減少資料量和運算量並減少處理時間。
判別語音段的起始點和終止點的問題主要歸結為區別語音和噪聲的問題。如果能夠保證系統的輸入信噪比很高(即使最低電平的語音的能量也比噪聲能量要高),那麼只要計算輸入訊號的短時能量就基本能夠把語音段和噪聲背景區別開來。但是,在實際應用中很難保證這麼高的信噪比,僅僅根據能量來判斷是比較粗糙的。因此,還需進一步利用短時平均過零率進行判斷,因為清音和噪聲的短時平均過零率比背景噪聲的平均過零率要高出好幾倍。這次主要介紹基於能量和過零率的語音端點檢測方法——兩級判別法。
兩級判別法採用雙門限比較法,如圖:
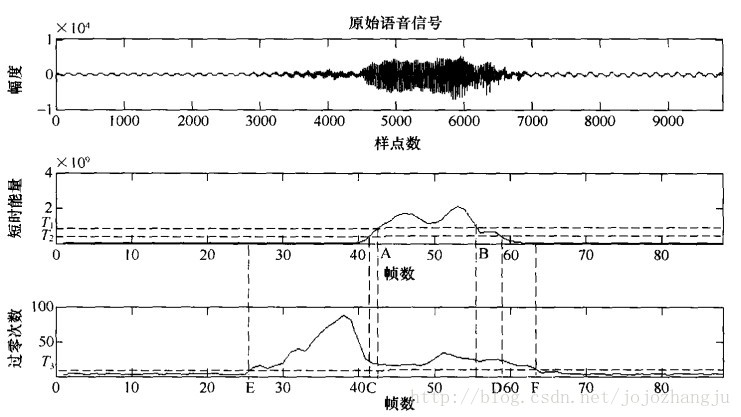
第一級判決:
1.先根據語音短時能量的輪廓選取一個較高的門限T1,進行一次粗判:語音起止點位於該門限與短時能量包絡交點所對應的時間間隔之外(即AB段之外)。
2.根據背景噪聲的平均能量確定一個較低的門限T2,並從A點往左、從B點往右搜尋,分別找到短時能量包絡與門限T2相交的兩個點C和D,於是CD段就是用雙門限方法根據短時能量所判定的語音段。
第二級判決:
以短時平均過零率為標準,從C點往左和從D點往右搜尋,找到短時平均過零率低於某個門限T3的兩個點E和F,這便是語音段的起止點。門限T3是由背景噪聲的平均過零率所確定的。
這裡要注意,門限T2,T3都是由背景噪聲特性確定的,因此,在進行起止點判決前,通常都要採集若干幀背景噪聲並計算其短時能量和平均過零率,作為選擇T2和T3的依據。當然,T1,T2,T3,三個門限值的確定還應當通過多次實驗。
3.8 基音週期估值
基音週期是表徵語音訊號本質特徵的引數,屬於語音分析範疇,只有準確分析並且提取出語音訊號的特徵引數,才能夠利用這些引數進行語音編碼、語音合成和語音識別等處理。語音編碼的壓縮率高低、語音合成的音質好壞及語音識別率的高低,也依賴於語音訊號分析的準確性和精確性。因此基音週期估值在語音訊號處理應用中具有十分重要的作用。語音訊號基音週期估值的方法很多,最基本的方法有:基於短時自相關法的基音週期估值和基於短時平均幅度差函式的基音週期估值。
基於短時自相關法的基音週期估值:
如果x(n)是一個週期為P的訊號,則其自相關函式也是週期為P的訊號,且在訊號週期的整數倍處,自相關函式取最大值。語音的濁音訊號具有準週期性,其自相關函式在基音週期的整數倍處取最大值。計算兩相鄰最大峰間的距離,就可以估計出基音週期。觀察濁音訊號的自相關函式圖,其中真正反映基音週期的只是其中少數幾個峰,而其餘大多數峰都是由於聲道的共振特性引起的。因此,為了突出反映基音週期的資訊,同時壓縮其他無關資訊,減少運算量,有必要對語音訊號進行適當預處理後再進行自相關計算以獲得基音週期。
基於短時平均幅度差函式AMDF法的基音週期估值:
如果訊號x(n)是標準的週期訊號,則相距為週期的整數倍的樣點上的幅度值是相等的,二者差值為零。對於濁音語音,在基音週期的整數倍上,這個差值不是零,但總是很小,因此,我們可以通過計算短時平均幅度差函式中兩相鄰谷值間的距離來進行基音週期估值。
基音週期估值的後處理:
語音訊號中的濁音訊號的週期性從波形上觀察可以看得很明顯,但是其形狀比較複雜,這使得基音檢測演算法很難做到處處準確可靠。在提取基音的過程中,無論採用哪種方法提取的基音訊率軌跡與真實的基音訊率軌跡都不可能完全吻合。實際情況是大部分段落吻合,而在一些區域性段落和區域中有一個或幾個基音訊率估計值偏離,甚至遠離正常軌跡,通常是偏離到正常值的2倍或1/2處,即實際基音訊率的倍頻或分頻處,稱這種偏離點為基音軌跡的“野點”。
為了去除這些“野點”,對求得的基音軌跡進行平滑後處理是非常必要的。語音訊號的基頻通常是連續緩慢變化的,因此,用某種平滑技術來糾正這些“野點”是可以的。常用的平滑技術主要有:中值濾波平滑處理、線性平滑、動態規劃平滑處理。
---------------------
作者:JameJuZhang
來源:CSDN
原文:https://blog.csdn.net/jojozhangju/article/details/26141939
版權宣告:本文為博主原創文章,轉載請附上博文連結!