
基於深度學習的計算機視覺技術在無人駕駛中的應用
基於深度學習的計算機視覺技術在無人駕駛中的應用
背景
當前,人工智慧是下一代資訊科技的核心和焦點,而無人配送則是人工智慧典型的落地場景,因為完成無人配送需要自動駕駛技術、機器人技術、視覺分析、自然語言理解、機器學習、運籌優化等一系列創新技術的高度整合。目前,美團的日訂單數量已經超過 2000 萬單,在人力有限的情況下,對無人配送就有著非常迫切的需求。美團無人配送團隊已經自主研發兩款適應不同業務場景的無人車產品,其中一款適用於室內外道路的小型低速無人車,還有一款長距離室外運輸的中型無人車。
目標檢測和語義分割技術簡介
目標檢測
目標檢測是在一幅圖片中找到目標物體,給出目標的類別和位置,如下圖所示:
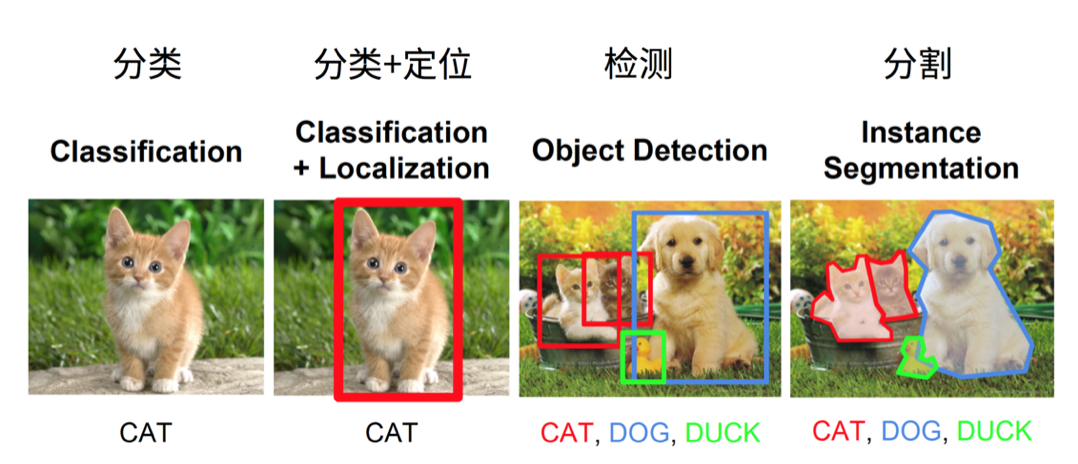
在 2014 年以前,目標檢測通常採用比較傳統的方法,先想辦法生成一些候選框,然後提取出每個框的特徵,例如 HOG,最後通過一個分類器來確認這個框是否是目標物體。而生成候選框的方式也有很多種,比如用不同大小的預選框在圖片中滑動,或者像 Selective Search[1] 演算法一樣,可以根據圖片本身的紋理等特徵生成一些候選框。但是自 2013 年以來,隨著深度學習相關技術的發展,不斷有新的模型出現,可以實現端到端的訓練檢測網路,並且效果比傳統方法有了顯著的提高。目標檢測的發展脈絡如下圖所示:

目標檢測方法分為 One-Stage 和 Two-Stage 兩種。兩步檢測演算法是把整個檢測過程分為兩個步驟,第一步提取一些可能包含目標的候選框,第二步再從這些候選框中找出具體的目標並微調候選框。而一步檢測演算法則是省略了這個過程,直接在原始圖片中預測每個目標的類別和位置。兩步檢測最經典的就是
R-CNN[2] 是比較早期提出用深度學習解決檢測的模型。思路是先用 Selective Search 演算法提取一定數量的候選區域,然後對於每個候選區域使用 CNN 提取特徵,最後在提出的特徵後面接一個迴歸和 SVM 分類,分別預測目標物體的位置和類別。R-CNN 的優點是使用了 CNN 提出的特徵,效果比較好。當然,缺點也很明顯,整個過程分成了好幾步,無法完整的訓練,另外由於每個候選框提特徵是獨立計算的,整個過程包含了大量的冗餘計算。

Fast-RCNN[3] 是在此基礎上的一個改進版本,主要解決了提取特徵時冗餘計算的問題。首先對整張圖片做卷積,提取特徵得到一層

Faster-RCNN[4] 是三部曲的最後一步。Fast-RCNN 存在的問題是:提取候選區域仍然是使用的 Selective Search 演算法,打亂了整個模型的連續性。Faster-RCNN 為了改進這點提出了 RPN 結構,RPN 可以在 Feature Map 的每個位置提取很多不同尺寸、不同形狀的候選框,也叫 Anchor。每個 Anchor 後會跟一個二值分類,來判斷這個 Anchor 是否是背景,並接一個迴歸對位置進行微調。具體的類別和位置在網路尾端還會進一步調整。至此,整個目標檢測過程都可以實現端到端的進行訓練。

在一步檢測中,比較經典的是 YOLO[5] 和 SSD[6] 模型。這裡介紹下 YOLO 演算法。首先將圖片劃分為 NxN 的方格,每個方格預測 C 個類別概率,表示某類目標中心落在這個方格的概率,並且預測 B 組位置資訊,包含 4 個座標和 1 個置信度。整個網路輸出 NxNx(5xB+C) 的 Tensor。YOLO 的優點是:省略兩步檢測中提區域的步驟,所以速度會比較快,但是它對於密集小物體的識別很不好。後續的 YOLOv2[7] 和 YOLOv3[8] 都對此做出了很多的改進。

分割
分割,是一個對圖片中的畫素進行分類的問題。分割最初分為語義分割和例項分割。語義分割是對圖片中每一個畫素都要給出一個類別,例如地面、樹、車、人等。而例項分割則和目標檢測比較像,但是例項分割是要給出每個目標的所有畫素,並且同一種類別不同目標要給出不同的 ID,即可以將每個目標清晰的區分開。
今年,有人研究將語義分割和例項分割統一在一起,稱為全景分割,如下圖所示:

在無人駕駛中應用比較多的是語義分割。例如路面分割、人行橫道分割等等。語義分割比較早期和經典的模型是 FCN[9]。FCN 有幾個比較經典的改進,首先是用全卷積層替換了全連線層,其次是卷積之後的小解析度 Feature Map 經過上層取樣,再得到原解析度大小的結果,最後 FCN 使用了跨層連線的方式。跨層連線可以將高層的語義特徵和底層的位置特徵較好地結合在一起,使得分割的結果更為準確。FCN 結構圖如下所示:

目前很多主流的分割模型準確率都比較高,但是幀率會比較低。而無人駕駛的應用場景中模型必須實時,尤其是高速場景下,對模型的速度要求更高。目前美團使用的是改進版的 ICNet[10],既保證了模型的執行速度,又保證了模型的準確率。下圖是一些經典分割模型的時間和準確率對比圖:

無人駕駛相關介紹
感測器
在無人駕駛中,車輛在行駛時需要實時地去感知周圍的環境,包括行駛在哪裡、周圍有什麼障礙物、當前交通訊號怎樣等等。就像我們人類通過眼睛去觀察世界,無人車也需要這樣一種 “眼睛”,這就是感測器。感測器有很多種,例如鐳射雷達、攝像頭、超聲波等等。每種感測器都有自己的特點:攝像頭可以包含豐富的顏色資訊,可以識別各種精細的類別,但是在黑暗中無法使用;鐳射可以在黑暗或強光中使用,但是雨天無法正常工作。目前不存在一種感測器可以滿足不同的使用場景,所以目前業界通常會通過感測器融合的方式來提高準確率,也能夠彌補缺點。各種感測器的特點可以檢視下圖:

不同的感測器的資料格式有很大差別,所以也會有專門針對某種感測器資料設計的演算法。例如有專門針對鐳射點雲設計的障礙物檢測模型VoxelNet。
目標檢測
由於攝像頭資料(圖片)包含豐富的顏色資訊,所以對於精細的障礙物類別識別、訊號燈檢測、車道線檢測、交通標誌檢測等問題就需要依賴計算機視覺技術。無人駕駛中的目標檢測與學術界中標準的目標檢測問題有一個很大的區別,就是距離。無人車在行駛時只知道前面有一個障礙物是沒有意義的,還需要知道這個障礙物的距離,或者說需要知道這個障礙物的 3D 座標,這樣在做決策規劃時,才可以知道要用怎樣的行駛路線來避開這些障礙物。這個問題對於鐳射的障礙物檢測來說很容易,因為鐳射本身就包含距離資訊,但是想只憑借圖片資訊去計算距離難度比較高。
分割
分割技術在無人駕駛中比較主要的應用就是可行駛區域識別。可行駛區域可以定義成機動車行駛區域,或者當前車道區域等。由於這種區域通常是不規則多邊形,所以分割是一種較好的解決辦法。與檢測相同的是,這裡的分割同樣需要計算這個區域的三維座標。如果我們分割的目標都是地面的話,就可以使用“距離估計”中第5種方式獲得精確的三維空間中的區域座標,這種應用在未來對無人駕駛有著巨大的意義,因為現在的無人駕駛都是基於高精地圖,而這種基於可行駛區域的方案是一種脫離高精地圖的方案。當然這種方案目前也只能在限定場景下應用,還不是很成熟。

距離估計
對於距離資訊的計算有多種計算方式:
鐳射測距,原理是根據鐳射反射回的時間計算距離。這種方式計算出的距離是最準的,但是計算的輸出頻率依賴於鐳射本身的頻率,一般鐳射是10Hz。
單目深度估計,原理是輸入是單目相機的圖片,然後用深度估計的 CNN 模型進行預測,輸出每個畫素點的深度。這種方式優點是頻率可以較高,缺點是估出的深度誤差比較大。
結構光測距,原理是相機發出一種獨特結構的結構光,根據返回的光的偏振等特點,計算每個畫素點的距離。這種方式主要缺點是結構光受自然光影響較大,所以在室外難以使用。
雙目測距,原理是根據兩個鏡頭看到的微小差別,根據兩個鏡頭之間的距離,計算物體的距離。這種方式缺點是計算遠處物體的距離誤差較大。
根據相機內參計算,原理跟小孔成像類似。圖片中的每個點可以根據相機內參轉化為空間中的一條線,所以對於固定高度的一個平面,可以求交點計算距離。通常應用時固定平面使用地面,即我們可以知道圖片中每個地面上的點的精確距離。這種計算方式在相機內參準確的情況下精度極高,但是隻能針對固定高度的平面。
業界相關進展
目前業界開源的解決方案中比較成熟的是百度的 Apollo[11],包含了改進的 ROS 底層系統,以及無人駕駛中各個模組的實現。Apollo 中視覺方案的距離計算非常有意思,這裡簡單介紹一下。Apollo 使用一個模型去預測 2D 圖片中物體的框,以及物體實際的在三維空間中的長寬高和朝向。當我們知道一個物體在三維空間中的位置和姿態(長寬高和朝向)時,我們可以根據相機內參,計算這個物體投影到圖片中的所在區域。那麼如果我們知道物體在影象中的區域和在三維空間中的姿態,我們如何計算三維位置呢?可以根據近大遠小的特點,去二分物體離我們的距離。這就是 Apollo 中視覺方案的距離計算方法。
除了 Apollo 之外,業界開源解決方案還有 Autoware[12]。雖然 Autoware 並沒有 Apollo 火熱,但是也給我們提供了一些解決問題的思路。Autoware 的視覺方案通過鐳射與攝像頭聯合標定的方式將每個鐳射點轉換到影象之中,並進一步根據 2D 檢測結果,知道哪些鐳射點打到了這個物體上,由於鐳射點的三維座標是已知的,就可以計算出這個物體的距離。
美團自研演算法
美團的自研演算法參考了 Autoware 的這種解決思路,並做了很多改進。同樣先將鐳射點轉換到圖片當中,這樣我們就知道每個鐳射點打到了哪裡。在得到每個 2D 框中的鐳射點之後,我們需要做一步聚類操作,這樣可以過濾掉打到背景上的點,於是我們就得到了打到這個物體上的鐳射點(參看下圖紅點)。然後在三維空間中,我們可以擬合這些鐳射點,得到一個三維框,包含了物體準確的位置資訊。這種方法計算出的三維框相對比較準確,但缺點是對於遠處較小的物體,由於打到的鐳射點太少了,難以擬合出合適的結果。具體效果可以參看下圖:

總結
本文從計算機視覺方向的檢測和分割出發,介紹了相關演算法原理,以及其在無人駕駛中的實際應用。之後介紹了距離估計的一些演算法,以及業界的一些視覺解決方案。
目前業界主流的的無人車障礙物感知是依賴於鐳射的,視覺方案相對還不是很成熟。但是我們仍然比較看好視覺方案,因為其成本低,並且可以減輕對高精地圖的依賴。
參考文獻
[1] Uijlings, Jasper RR, et al. "Selective search for object recognition." International journal of computer vision 104.2 (2013): 154-171.
[2] Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
[3] Girshick, Ross. "Fast r-cnn." Proceedings of the IEEE international conference on computer vision. 2015.
[4] Ren, Shaoqing, et al. "Faster r-cnn: Towards real-time object detection with region proposal networks." Advances in neural information processing systems. 2015.
[5] Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[6] Liu, Wei, et al. "Ssd: Single shot multibox detector." European conference on computer vision. Springer, Cham, 2016.
[7] Redmon, Joseph, and Ali Farhadi. "YOLO9000: better, faster, stronger." arXiv preprint (2017).
[8] Redmon, Joseph, and Ali Farhadi. "Yolov3: An incremental improvement." arXiv preprint arXiv:1804.02767 (2018).
[9] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. "Fully convolutional networks for semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[10] Zhao, Hengshuang, et al. "Icnet for real-time semantic segmentation on high-resolution images." arXiv preprint arXiv:1704.08545 (2017).
[11] https://github.com/ApolloAuto/apollo
[12] https://github.com/CPFL/Autoware)
作者簡介
劉宇達,2017 年 6 月加入美團,現負責無人車視覺感知相關工作。
【https://gitbook.cn/books/5bc4633a67b0235655819292/index.html】