
目標檢測之模型篇(1)【CTPN連線文字提議網路】
1. 前言
本週開始看模型篇,本週目標:CTPN,RRPN,DMPNet,EAST,衝鴨!! 第一篇,CTPN(Connectionist Text Proposal Network),其實是基於Faster R-CNN改進的,將RPN的體系結構擴充套件到文字識別上面,達到了state-of-art水平。
2. 實現
2.1 關鍵idea
1.開發了一種錨(anchor)迴歸機制,可以聯合預測每個文字提案的垂直位置和文字/非文字得分,從而獲得極好的定位精度; 2.RNN網路內遞推機制,它優雅地在卷積特徵對映中處理順序文字建議; 3.CNN+RNN無縫整合,以滿足文字序列的本質,形成統一的端到端可培訓模型。能夠在一個程序中處理多尺度和多語言的文字,避免了進一步的後過濾或細化。
2.2 模型結構
 1.用VGG16的前5個Conv stage(到conv5)得到feature map(WxHxC);
2.在Conv5的feature map的每個位置上取3x3xC的視窗的特徵,這些特徵將用於預測該位置k個anchor對應的類別資訊,位置資訊;
3.將每一行的所有視窗對應的3x3xC的特徵(Wx3x3xC)輸入到RNN(BLSTM)中,得到Wx256的輸出;
4.將RNN的Wx256輸入到512維的fc層;
5.fc層特徵輸入到三個分類或者回歸層中。第二個2k scores 表示的是k個anchor的類別資訊(是字元或不是字元)。第一個2k vertical coordinate和第三個k side-refinement是用來回歸k個anchor的位置資訊。2k vertical coordinate表示的是bounding box的高度和中心的y軸座標(可以決定上下邊界),k個side-refinement表示的bounding box的水平平移量。這邊注意,只用了3個引數表示迴歸的bounding box,因為這裡默認了每個anchor的width是16,且不再變化(VGG16的conv5的stride是16)。迴歸出來的box如上圖a中那些紅色的細長矩形,它們的寬度是一定的;
6.用簡單的文字線構造演算法,把分類得到的文字的proposal(圖b中的細長的矩形)合併成文字線。
1.用VGG16的前5個Conv stage(到conv5)得到feature map(WxHxC);
2.在Conv5的feature map的每個位置上取3x3xC的視窗的特徵,這些特徵將用於預測該位置k個anchor對應的類別資訊,位置資訊;
3.將每一行的所有視窗對應的3x3xC的特徵(Wx3x3xC)輸入到RNN(BLSTM)中,得到Wx256的輸出;
4.將RNN的Wx256輸入到512維的fc層;
5.fc層特徵輸入到三個分類或者回歸層中。第二個2k scores 表示的是k個anchor的類別資訊(是字元或不是字元)。第一個2k vertical coordinate和第三個k side-refinement是用來回歸k個anchor的位置資訊。2k vertical coordinate表示的是bounding box的高度和中心的y軸座標(可以決定上下邊界),k個side-refinement表示的bounding box的水平平移量。這邊注意,只用了3個引數表示迴歸的bounding box,因為這裡默認了每個anchor的width是16,且不再變化(VGG16的conv5的stride是16)。迴歸出來的box如上圖a中那些紅色的細長矩形,它們的寬度是一定的;
6.用簡單的文字線構造演算法,把分類得到的文字的proposal(圖b中的細長的矩形)合併成文字線。
2.3 具體細節
1.檢測小尺度文字框(Detecting Text in Fine-scale Proposals)
- k個anchor的設定:寬度固定為16,高度範圍為11~273畫素(每次除以0.7)
- 預測k個垂直座標:
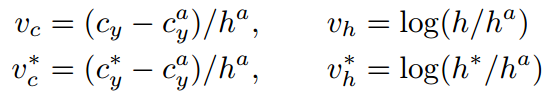 帶*的都是Ground Truth;帶a的都是anchor的;啥也不帶的是預測的。
帶*的都是Ground Truth;帶a的都是anchor的;啥也不帶的是預測的。
 左邊是RPN的檢測框,小尺度檢測提議的檢測框,顯然右邊更加精細,更適合文字檢測。
左邊是RPN的檢測框,小尺度檢測提議的檢測框,顯然右邊更加精細,更適合文字檢測。
2.迴圈連線文字框(Recurrent Connectionist Text Proposals)
- RNN型別:雙向LSTM(可以利用文字序列的上下文資訊,使得檢測的文字行更加精確,儘可能減少誤檢),每個LSTM有128個隱含層
- RNN輸入:每個滑動視窗的3x3xC的特徵(可以拉成一列),同一行的視窗的特徵形成一個序列
- RNN輸出:每個視窗對應256維特徵
 上面的:沒用RNN
下面的:用了RNN
對比可知,用了RNN之後,圖1減少了誤檢率;圖2圖3根據上下文檢測到了沒用RNN沒檢測到的文字。
上面的:沒用RNN
下面的:用了RNN
對比可知,用了RNN之後,圖1減少了誤檢率;圖2圖3根據上下文檢測到了沒用RNN沒檢測到的文字。
3.文字行邊細化(Side-refinement)
- 只接受分數大於0.7的提議。
- 文字線構造演算法:
主要思想:每兩個相近的proposal組成一個pair,合併不同的pair直到無法再合併為止。 判斷兩個proposal,Bi和Bj組成pair的條件:Bj->Bi, 且Bi->Bj。 Bj->Bi條件1:Bj是Bi的鄰居中距離Bi最近的,且該距離小於50個畫素 Bj->Bi條件2:Bj和Bi的vertical overlap大於0.7
- 引入文字行的Side-refinement
由於text proposal的寬度是固定16,這可能造成定位不準,部分text proposal被丟棄等。
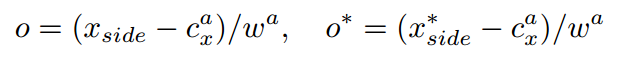 xside是距離當前錨點水平位置最近的x座標,帶*的xside是x軸的Ground Truth,cax是錨點的x軸中心,wa是固定值16。
xside是距離當前錨點水平位置最近的x座標,帶*的xside是x軸的Ground Truth,cax是錨點的x軸中心,wa是固定值16。
 上圖是對比,紅色框是加入了side-refinement後,黃色虛線是沒加。不同顏色代表不同text/non-text分數。
上圖是對比,紅色框是加入了side-refinement後,黃色虛線是沒加。不同顏色代表不同text/non-text分數。
3. 訓練
1.訓練標籤labels
- 正樣本:
與真值IoU大於0.7的anchor作為正樣本 與真值IoU最大的那個anchor也定義為正樣本
- 負樣本:
與真值IoU小於0.5的anchor定義為負樣本
2.訓練成本loss
- 文字/非文字採用softmax
- 垂直座標採用L1迴歸
- side-refinement採用L1迴歸
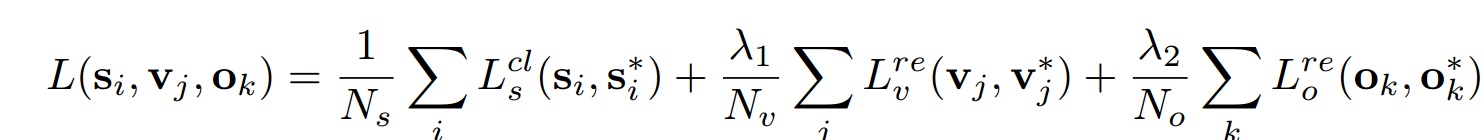 其中。
其中。
3.訓練引數
- 對於每一張訓練圖片,總共抽取128個樣本,64正64負,如果正樣本不夠就用負樣本補齊;
- 訓練圖片都將短邊放縮到600畫素,並且保持原圖的縮放比;
- RNN層和輸出層採用隨機均值為0,方差為1的引數進行初始化;
- 在訓練時CNN的前兩層引數固定。
4. 結果
- 每張圖0.14s
