
目標檢測之模型篇(3)【DMPNet】
文章目錄
- 1. 前言
- 2. 實現
- 2.1 Roughly recall text with quadrilateral sliding window
- 2.2 Finely localize text with quadrangle
- 2.3 Smooth Ln loss
- 3. 結果
- 4. 總結與思考
- 5. 參考資料
1. 前言
本週第三篇模型文章,讀的是我工電信院大佬發的paper,莫名親切感~DMPNet全稱Deep Matching Prior Network(深度匹配先驗網路)。常規的文字檢測一種主流方法是基於成分
總體思路:
1.在幾個特定的中間卷積層中使用四邊形滑動視窗來粗略地回憶重疊區域較高的文字;
2.提出了一種shared Monte-Carlo method來快速準確地計算多邊形區域;
3.在此基礎上,設計了一種用於關聯迴歸的sequential protocol,該協議能夠準確地預測文字內容;
4.為了進一步迴歸文字的位置,還提出了一種輔助的光滑Ln損失
2. 實現
2.1 Roughly recall text with quadrilateral sliding window
由於水平滑動視窗並不能recall多方向的文字,本文基於文字的內在形狀,提出了大量的四邊形滑動視窗來大致recall文字。
- 使用重疊閾值(overlapping threshold)
關於閾值的選擇問題,太大的閾值會使文字很難recall,而太小的閾值又引來大量背景噪聲。使用四邊形滑動視窗,滑動視窗與ground truth的重疊區域可以足夠大,達到更高的閾值,有利於提高召回率和準確率。
(a)圖黑色框代表groud truth,藍色框是水平矩形滑動視窗,紅色是本文提出的四邊形滑動視窗。可見,四邊形滑動視窗的IoU比水平矩形滑動視窗高很多,這有利於recall文字。
(b)圖是水平矩形滑動視窗,正方形有大小兩個尺寸,長方形有橫豎兩個方向。
(c)圖是本文提出的四邊形滑動視窗,保留了水平滑動視窗,同時基於文字內在形狀的先驗知識在其中設計幾種四邊形:
[c-1]在正方形內增加了兩個45度角傾斜的矩形(棕色);
[c-2]在橫矩形內增加了兩個平行四邊形(紅色、綠色);
[c-3]在豎矩形內增加了兩個平行四邊形(紫色、黃色);
有了這些靈活的滑動視窗,粗邊框變得更加精確,因此子序列精細過程可以更容易地定位文字。另外,由於背景噪聲較小,這些四邊形滑動視窗的置信度在實際應用中更可靠,可以用來消除誤報。

- Shared Monte-Carlo方法
該方法在計算多邊形面積的同時具有較高的速度和精度。
step1: 在Ground Truth的外切矩形中均勻取樣10,000個點。Ground Truth面積( )的計算方法是通過計算重疊點在所有點上的比例乘以外切矩形的面積。在這一步中,Ground Truth內部的所有點將被保留以供共享計算。
step2:如果每個滑動視窗的外切矩形和每個Ground Truth的外切矩形沒有交集,重疊區域為零,不需要進一步計算;如果重疊區域不為零,我們使用相同的取樣策略來計算滑動視窗( )的面積,然後計算從第一步到滑動視窗內保留的點的數量。GT內點與外切矩形面積的比值為重疊的區域。特別地,這個步驟適合我們進行GPU並行化,因為我們可以使用每一個執行緒來負責計算每一個給定Ground Truth的滑動視窗,這樣我們就可以在短時間內處理數千個滑動視窗。

上圖是過去的計算方法與文章提出的shared Monte-Carlo方法的對比。以往的方法當角度增加的時候錯誤率極速提高,而本文的方法錯誤率很低(1%)。以往的方法計算的是矩形面積,而本文的方法是取點取樣,然後計算佔比,而且處理的是多邊形。
2.2 Finely localize text with quadrangle
與矩形只需要確定兩條對角線不同,凸四邊形的確定需要四個頂點,而且四個頂點的順序需要已知,否則也許會產生自相矛盾的結果。
- 座標順序協議(Sequential protocol of coordinates)

step1:用x最小值確定第一個點,如果兩個點同時有x最小值,那麼我們選擇y值較小的點作為第一個點。
step2:我們把第一個點和其他三個點連起來,就能從中間的斜線裡找到第三個點。第二點和第四點分居中間線的對側(分別定義為“大”邊和“小”邊)。
step3:處於中間線上面的點是第二點,下面的就是第四點。
step4:比較兩條對角線(線13和線24)之間的斜率。在斜率較大的直線上,我們選擇x較小的點作為新的第一點。(特別地,如果斜率較大為無窮大,則取y較小的點作為第一點。)重複1~3步,求出第三點,然後再求出第二點和第四點。
至此,凸4邊形被唯一確定。
本文的迴歸方法預測了四邊形檢測的兩個座標和八個長度。對於每一個Ground Truth,四個點的座標格式是( ),( )是中央水平最小外接矩形中心點的座標, 是相對於中心點( )的第i個點( ),如下圖所示:

用10個座標而非8個,用來防止8個座標的倒退(regressing)。
2.3 Smooth Ln loss
對於提出的光滑Ln損失,迴歸引數是資料的連續函式,這意味著對於資料點的任何小的調整,迴歸線總是隻會輕微的移動,從而提高了小文字本地化的精度。對於更大的調整,迴歸總是可以在平滑Ln損失的基礎上向一個溫和的步驟移動,這可以加速實際訓練過程的逆向。
- smoorth L1 loss:
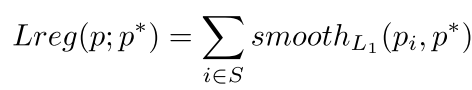
其中
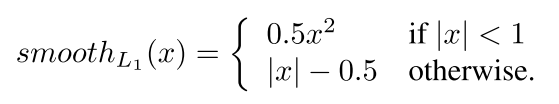
函式中的x代表預測值和Ground Truth之間的誤差(
。
的誤差函式:
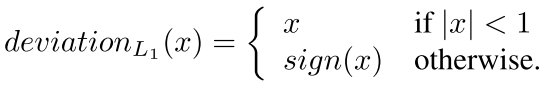
- smooth Ln loss:
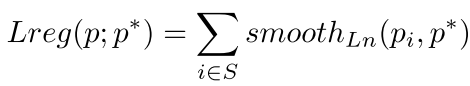
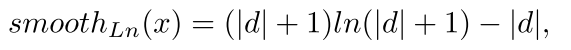
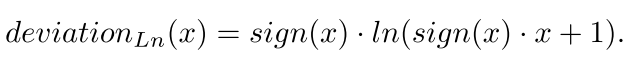
三種Loss的對比:

結果表明,smooth Ln loss保證了更好的文字定位和相對更緊密的文字包圍框。
3. 結果
資料集:ICDAR 2015 Competition Challenge 4: “Incidental Scene Text”
資料集包括1000張訓練影象和500張測試附帶場景影象,其中文字可以以小尺寸或低解析度出現在任何方向和位置,所有邊界框的註釋都標記在單詞級別。
評價指標:Precision, Recall, F-measure
模型:VGG16
圖片大小:800*800
訓練集:1000張


最右邊一列是失敗案例,太過細小的文字沒有被檢測出來。
4. 總結與思考
總結:
1.四邊形滑動視窗
2.shared Monte-Carlo方法有效計算Overlapping
3.smooth ln loss迴歸
思考:
1.ground truth框是不是弄成四邊形的更好?
2.雖然本文多預定義了6個傾斜的四邊形框,還是不夠穩健。考慮開發自適應框。
5. 參考資料
1.《Deep Matching Prior Network: Toward Tighter Multi-oriented Text Detection》