
目標檢測之模型篇(4)【EAST】
文章目錄
1. 前言
這篇文章是我最早讀的模型類文章,但是當時還沒萌生出寫部落格複習總結的想法。還好這個想法出現的不晚,現在是第四篇模型類文章,剛好拿來複習一下。當時讀的時候就覺得作者字裡行間充滿了自信(可能是因為EAST模型的效果真的很好吧),EAST這名字又有種東方的神祕氣息(誤),話不多說,還是開始介紹吧。
EAST全名an Efficient and Accuracy Scene Text detection pipeline,高效、準確的場景文字識別管道(不得不說這縮寫真的好中二啊)。該Pipeline直接預測影象中任意方向和矩形形狀的文字或文字行,通過單個神經網路消除不必要的中間步驟(例如候選聚合和單詞分割)。
三個貢獻:
- 提出了一個由兩階段組成的場景文字檢測方法:FCN階段和NMS階段。FCN直接生成文字區域,不包括冗餘和耗時的中間步驟。
- 該pipeline可靈活生成wordlevel或line level預測,其幾何形狀可為旋轉框或矩形。
- 所提出的演算法在準確性和速度上明顯優於最先進的方法。

常規的文字檢測Pipeline都含有很多中間步驟,而這些中間步驟會導致誤差的累積,效能次優,且處理時間較長。本文提出的方法,只有FCN和NMS兩個中間步驟,放棄了不必要的中間元件和步驟,並允許進行端到端的訓練和優化。由此產生的框架是輕量級的單個神經網路,在效能和速度上都明顯優於所有以前的方法。
2. 實現
該演算法的關鍵部分是一個神經網路模型,該模型通過訓練直接預測圖形中的文字例項及其幾何形狀的存在。該模型是一種完全卷積神經網路,適用於文字檢測,輸出密集的每畫素的詞或文字行。這就消除了中間步驟如候選人提議,文字區域形成和分割槽。後處理步驟僅包括閾值化和預測幾何形狀的NMS。由於該檢測器是一種高效、準確的場景文字檢測管道,故將其命名EAST。
2.1 Pipeline
影象被送到FCN中並且生成畫素級的文字分數特徵圖和幾何圖形特徵圖的多個通道。其中一個預測通道是分數特徵圖,其畫素值範圍是[0,1]。剩下的通道表示從每個畫素檢視中包含單詞的幾何圖形。分數代表在同一位置預測的幾何形狀的置信度。
兩種文字區域的幾何形狀:旋轉框(RBOX)和
2.2 網路設計

- 特徵提取層:先用通用網路如VGG16,Pvanet,Resnet等作為基礎網路(文中用的是Pvanet),用於特徵提取。抽取不同大小的Feature map(輸出影象的 大小),用以應付多尺度變換問題;
- 特徵融合層:

其中 是合併基礎, 是合併的特徵圖,運算子[·;·]表示沿通道軸的連線。在每個合併階段,來自最後一個階段的特徵圖首先被輸入到一個反池化層來擴大其大小,然後與當前特徵圖進行連線。接下來,通過conv1×1瓶頸減少通道數量和計算量,接下來是conv3×3,將資訊融合以最終產生該合併階段的輸出。在最後一個合併階段之後,conv3×3層會生成合並分支的最終特徵圖並將其送到輸出層。 - 輸出層:最終的輸出層包含若干個conv1×1操作,以將32個通道的特徵圖投影到1個通道score 特徵圖Fs和一個多通道幾何圖形Fg。幾何形狀輸出只有RBOX或QUAD兩種,如下表所示:
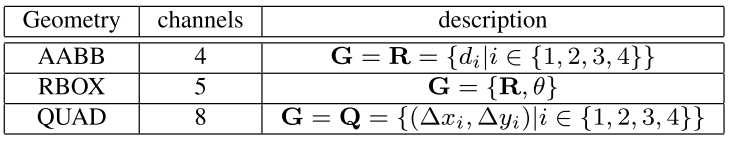
AABB4個通道分別表示從畫素位置到矩形的頂部,右側,底部,左側邊界的4個距離;
對於RBOX的幾何形狀由4個通道的軸對齊邊界框(AABB)R和1個通道的旋轉角度θ表示;
QUAD的8個數字表示從矩形的四個頂點到畫素位置的座標偏移。由於每個距離偏移量都包含兩個數字(Δxi;Δyi),因此幾何形狀輸出包含8個通道。
2.3 標籤生成

- 四邊形Score Map生成(圖a,b)
Score Maps是原始四邊形的縮小版。 是相對 的參考長度,D( , )是pi和pj的L2距離:
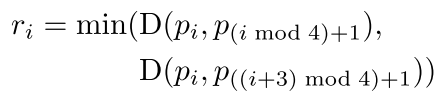
先縮小長對邊,再縮小短對邊。 - Geometry Map生成(圖c~e)
對於其文字區域以QUAD格式標註的資料集(例如ICDAR 2015),我們首先生成一個旋轉矩形,以最小面積覆蓋該區域。然後,對於每個有正分數的畫素,我們計算它與文字框4個邊界的距離,並將它們放到RBOX ground truth的4個通道中。對於QUAD ground truth,8通道幾何圖形每個畫素的正分數值是它與四邊形4個頂點的座標偏移。
2.4 損失函式
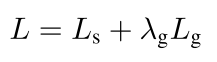
是
的權重,在本實驗中設定為1。
- Score Map的損失
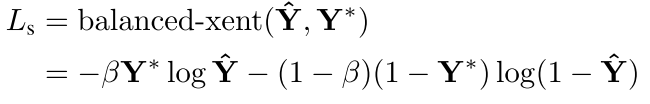
其中
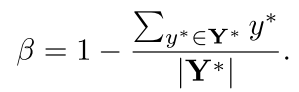
這是一種平衡交叉熵損失。 - 幾何損失
由於需要尺度不變的文字幾何預測,所以在RBOX迴歸的AABB部分採用IoU損失,QUAD迴歸採用尺度歸一化平滑L1損失。
2.5 訓練
使用ADAM優化器對網路進行端到端訓練。為了加快學習速度,我們將輸入影象大小固定在512x512,形成一個24尺寸的小批量。ADAM的學習率從1e-3開始,每27300個小批量衰減到十分之一,在1e-5停止。網路被訓練直到效能停止改善。
2.6 位置感知的NMS

在假設來自附近畫素的幾何圖形傾向於高度相關的情況下,提出逐行合併幾何圖形,並且在合併同一行中的幾何圖形時,我們將迭代合併當前遇到的幾何圖形與最後一個合併圖形。這種改進的技術在場景中以O(n)執行。合併的四邊形座標是通過兩個給定四邊形的得分進行加權平均的。是平均而非選擇,充當了投票機制,採取這種方法可以將所有框的座標資訊都加以利用,而不像常規NMS一樣直接棄掉得分低的框,也許會丟失資訊。
3. 結果
三個資料集:ICDAR2015、COCO-Text和MSRA-TD500
兩個基礎網路:VGG16(感受野小),Pvanet(感受野比VGG16大很多)
ICDAR 2015:

COCO-Text:

MSRA-TD500:

4. 總結
目前的限制:
- 檢測器可以處理的文字例項的最大大小是網路的感受野比例。這限制了網路預測更長的文字區域的能力,例如橫穿影象的文字行。因此處理長文字效果較差。
- 此外,該演算法可能會遺漏或給出不精確的垂直文字例項預測,因為它們只採用ICDAR 2015訓練集中的一小部分文字區域。
未來的方向:
- 檢測曲線文字
- 整合識別功能
- 普及到一般目標檢測
EAST優點:檢測多尺度、多方向文字
5. 參考資料
1.《EAST: An Efficient and Accurate Scene Text Detector》
2.論文翻譯
3.https://blog.csdn.net/qq_14845119/article/details/78986449
4.https://zhuanlan.zhihu.com/p/37504120