
[深度學習]Object detection物體檢測之Retinanet(12)
論文全稱:《Focal Loss for Dense Object Detection》
論文地址:https://arxiv.org/pdf/1708.02002.pdf
論文程式碼:https://github.com/facebookresearch/Detectron
目錄
綜述
目前one-stage的檢測演算法速度非常快,但是在精準度上表現的不如two-stage的演算法,然後two-stage的演算法的速度方面又不能達到實時性的要求。論文發現這兩者之間的鴻溝主要是由於前景和背景之間的嚴重的類別不平衡是該問題的核心,為了解決這個辦法,重新構造標準交叉熵損失focal loss
為了評估損失的有效性,作者設計和訓練了一個簡單的緻密探測器,稱之為RetinaNet。結果表明,當使用focal loss進行訓練時,RetinaNet能夠與之前one-stage的detector的速度相匹配,同時超過了現有所有最先進的two-stage detector的精度。

Focal Loss
cross entropy(CE)loss
focal loss就是為了減低在訓練期間前景和背景類別不平衡所帶來的精度損失的問題所設計的。傳統的cross entropy(CE)loss是下面這樣的:
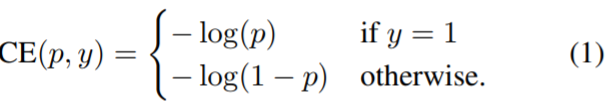
這種loss function有一個顯著的特徵就是對於很容易分類的example(pt概率比較大的)都會有比較大的loss,對應於下圖的藍色曲線。當訓練很多這樣的例子,就會覆蓋那些rare的example(難以辨別的例子)。

Balanced Cross Entropy
作為本論文focal loss比較的一個baseline,先引入一個常見的方法解決類失衡是引入權重因子α。在實踐中,α可以根據類別之間的頻率設定,也可以當做一個超引數,使用交叉驗證方法來設定。
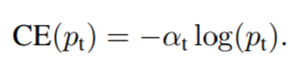
Focal Loss Definition
上面提到的引入α只是簡單地平衡positive/negative example的頻率,它不區分easy/hard的例子。所以focal loss使negative 中eacy的例子權重降低,從而將訓練集中在hard的例子。
那麼是怎麼做的呢?
首先,新增一個調製因子![]() ,其中
,其中![]() ,focal loss的公式:
,focal loss的公式:
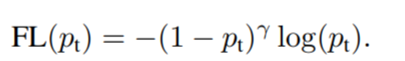
根據上面的曲線圖,注意到焦點損失的兩個性質。
- 1.當樣本分類錯誤且pt值較小時,調製因子接近1,loss不受影響。當pt→1,調製因子趨於0,對於很容易分辨的example,他們的對於loss的權重降低。
- 2.focusing 引數 γ平穩調整了easy examples對loss的權重。當γ= 0,FL相當於CE。當γ增加,調製因子也同樣增加了。
在實踐中,作者使用一個α-balanced加上focal loss的變體:
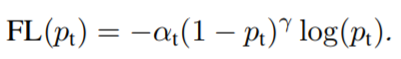
RetinaNet Detector
- RetinaNet = FPN + sub-network + FL
RetinaNet是由一個backbone網路和兩個特定於任務的子網路組成的單一、統一的網路。backbone網路負責計算整個輸入影象的卷積特徵對映,是一個自卷積網路。第一個子網路使用backbone的輸出作為輸入進行分類,第二個子網路則負責bounding box regression。下圖就是它的結構圖。

backbone網路使用了Feature Pyramid Network(FPN),它的主要特點是top-down pathway 自頂向下通路和 lateral connections 側向連線。可以參考https://blog.csdn.net/sinat_33487968/article/details/84328272。
這裡值得注意:
- 兩個子網路的結構相同,但是他們各自的權重引數都是獨立的。
- 採用了無分類的bbox regressior(Faster R-CNN是每個類各一個bbox regressor),減低的引數的數量。
Result
