
[深度學習]Object detection物體檢測之YOLO v2(7)
目錄
High Resolution Classifier(高解析度的分類器)
Convolutional With Anchor Boxes
Direct location prediction(直接位置預測)
論文全稱:《YOLO9000: Better, Faster, Stronger
論文地址:https://arxiv.org/abs/1612.08242
綜述
YOLO v2對比起v1主要改進有兩方面:
- 多種方法對原來的v1版本改進,在保持原有速度的基礎上,提升了檢測的精度。
- 提出了一種聯合訓練物件檢測和分類的方法。可以使用其他任務的資料(imagenet分類資料)聯合訓練物體檢測。
與用於分類和標記等其他任務的資料集相比,當前的物體檢測資料集是有限的。因為物體檢測的資料集構建本身成本非常高。
本論文提出了hierarchical view分層檢視,可以把不同的資料集合並在一起使用。本論文還提出了一種聯合訓練演算法,允許我們在檢測和分類資料上訓練目標檢測器。
多種方法對原來的v1版本改進
主要關注提高召回率recall和定位準確率,同時保證分類的準確率。下圖代表了各種不同的改進方法。

Batch Normalization
通過對YOLO中所有的卷積層新增batch normalization,在mAP中得到了超過2%的改進。通過batch normalization,可以在不過擬合的情況下從模型中刪除drop - out。
High Resolution Classifier(高解析度的分類器)
目前的目標檢測方法中,基本上都會使用ImageNet預訓練過的模型(classifier)來提取特徵,如果用的是AlexNet網路,那麼輸入圖片會被resize到小於256 * 256,導致解析度不夠高,給檢測帶來困難。為此,新的YOLO網路把解析度直接提升到了448 * 448,這也意味之原有的網路模型必須進行某種調整以適應新的解析度輸入。
對於YOLOv2,作者首先對分類網路(自定義的darknet)進行了fine tune,解析度改成448 * 448,在ImageNet資料集上訓練10輪(10 epochs),訓練後的網路就可以適應高解析度的輸入了。然後,作者對檢測網路部分(也就是後半部分)也進行fine tune。這樣通過提升輸入的解析度,mAP獲得了4%的提升。
Convolutional With Anchor Boxes
YOLO v1使用卷積特徵上的完全連線層直接預測 bounding boxes 的座標。v2的版本中作者借鑑了Faster rcnn僅使用卷積層的region proposal network(RPN) 去預測每一個anchor box的偏移量(與region中心點的偏移)和置信度。由於預測層是卷積層,RPN在feature map中的每個位置預測這些偏移量。預測偏移量而不預測box的座標簡化了問題,使網路更容易學習。
具體的做法是從YOLO刪除完全連線的層,使用anchor boxes來預測bounding boxes。首先,消除了最後一個池化層,使網路卷積層的輸出具有更高的解析度。然後降低了輸入的解析度至416*416而非448*448,因為想得到一張長寬為奇數的feature map。奇數的好處是每個location只有單一的center cell。對於很大的物體,傾向於佔據影象的中心,所以最好在中心有一個單獨的位置來預測這些物體,而不是四個在附近的位置(如果是偶數則有四個center cell,映射回image則有四個附件的位置)。v2版本最後得到13*13的feature map(降取樣的factor為32)。
加入了anchor boxes後,recall召回率上升,準確率下降。假設每個cell預測9個建議框,那麼總共會預測13 * 13 * 9 = 1521個boxes,而之前的網路僅僅預測7 * 7 * 2 = 98個boxes。具體資料為:沒有anchor boxes,模型recall為81%,mAP為69.5%;加入anchor boxes,模型recall為88%,mAP為69.2%。這樣看來,準確率只有小幅度的下降,而召回率則提升了7%,說明可以通過進一步的工作來加強準確率,的確有改進空間。
Dimension Clusters(維度聚類)
為了讓網路學習得更好,所以採用了k-means演算法挑選anchor box的先驗框,不採用faster rcnn人工挑選的方法。但是這裡的一個問題是如果使用標準的k-means演算法,即使用歐幾里得距離公式計算的話,大的box的錯誤會比小的box更大。然而,我們真正想要的是能夠帶來好的IOU分數的先驗,它與box的大小無關。因此,對於距離度量,使用如下公式:
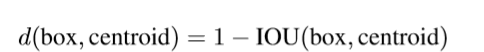
論文對不同的k執行k-means,用最接近質心繪製平均IOU(下圖)。最後選擇k = 5作為模型複雜度和高召回率之間的權衡。這些由k-means產生的先驗框比之前faster rcnn手工選擇的先驗框看起來很大不同。

下圖可以看到只使用5個聚類產生的先驗框就能夠達到Avg IOU 61.0,可以與faster rcnn媲美了,如果使用的是k=9則可以達到67.2。

Direct location prediction(直接位置預測)
作者在使用anchor boxes時發現的第二個問題就是:模型不穩定,尤其是在早期迭代的時候。因為任何anchor boxes可以在影象中任意一點結束。模型隨機初始化後,需要花很長一段時間才能穩定預測敏感的物體位置。
在此,作者就沒有采用預測直接的offset的方法,而使用了預測相對於grid cell的座標位置的辦法,作者又把ground truth限制在了0到1之間,利用logistic迴歸函式來進行這一限制。
網路在每一個網格單元中預測出 5 個 Bounding Boxes,每個 Bounding Boxes 有五個座標值 tx,ty,tw,th,t0,他們的關係見下圖(Figure3)。假設一個網格單元對於圖片左上角的偏移量是 cx、cy,Bounding Boxes Prior 的寬度和高度是 pw、ph,那麼預測的結果見下圖右面的公式:


Fine-Grained Features
YOLOv1在對於大目標檢測有很好的效果,但是對小目標檢測上,效果欠佳。為了改善這一問題,作者參考了Faster R-CNN和SSD的想法,在不同層次的特徵圖上獲取不同解析度的特徵。作者將上層的(前面26×26)高解析度的特徵圖(feature map)直接連到13×13的feature map上。把26×26×512轉換為13×13×2048,並拼接住在一起使整體效能提升1%。
Multi-Scale Training
和GoogleNet訓練時一樣,為了提高模型的魯棒性(robust),在訓練的時候使用多尺度[6]的輸入進行訓練。YOLOv2 每迭代幾次都會改變網路引數。每 10 個 Batch,網路會隨機地選擇一個新的圖片尺寸,由於使用了下采樣引數是 32,所以不同的尺寸大小也選擇為 32 的倍數 {320,352…..608},最小 320,最大 608,網路會自動改變尺寸,並繼續訓練的過程。
下圖是YOLO v2的速度與精度對比圖。

聯合訓練分類和檢測資料
該論文提出分類檢測資料聯合訓練機制。對於detection的data可以基於整個YOLO v2 的lossfunction進行反向傳播,而遇到了classification的data只反向傳播與分類有關的那部分。
不過這樣會出現一些問題,比如說分類的資料的label比檢測資料的label種類要更多更寬泛,如果需要同時利用這些資料,必須要有一個統一的方式來融合這些資料。一般的分類任務都使用softmax分類但是softmax是類與類之間是互相排斥的,比如在coco資料裡有一大類是狗,但是在imagenet分類資料集裡有一小類是某種特定的狗,那麼使用softmax是沒有方法做到區分的。
所以論文採用的是多標籤的label,使得資料集之間沒有互相排斥。
Hierarchical classification
為了構建multi-label多標籤的資料機構,藉助了WordNet。WordNet的結構是一個有向圖,而不是樹。這是因為語言是複雜的,可能存在迴路。例如,“狗”既是“犬”的一種,也是“家畜”的一種,兩者都是合成詞網。與使用全圖結構不同,本論文通過從ImageNet中的概念構建層次樹來簡化這個問題。
簡單點說就是把imagenet和coco資料集所含有的label利用這個WordNet來尋找他們之間的關係,然後剔除中間的從屬關係,最後剩下一顆層次樹。
最後的結果得到是WordTree,一個視覺概念的層次模型。

而predict某一類的時候採取預測了每個節點的條件概率,例如對於“terrier”這一大類:

如果我們想知道具體某一類的絕對概率,就這麼計算:

下面指出了與原來只使用一個softmax分類1k個分類不同,使用WordTree,在共低元上執行多個softmax操作。
