
【深度學習】實時物體檢測框架Single-Shot MultiBox Detector(SSD)(1)概述
一、ssd使用場景及效能分析
目標檢測是深度學習影象識別的技術領域,指對單張圖片中的物體的類別和位置進行標註。在ssd中,位置資訊是通過邊界框(bounding-boxes)來描述的。
邊界框是一組四個資料,xmin,ymin,xmax,ymax(VOC標準格式)共同描述物體的位置資訊。
在PASCAL VOC2007 的測試集上,ssd(300x300)取得了72.1的mAP,已經算是非常精準了,更可貴的是它比Fast、Faster R-CNN更快(經測試SSD在nvidia gtx970m上可以取得近30fps的準確度,接近實時,而faster r-cnn不足10fps)

因此,SSD模型在準確性和實時性上,都具有非常高的實用價值。
二、ssd原理初探
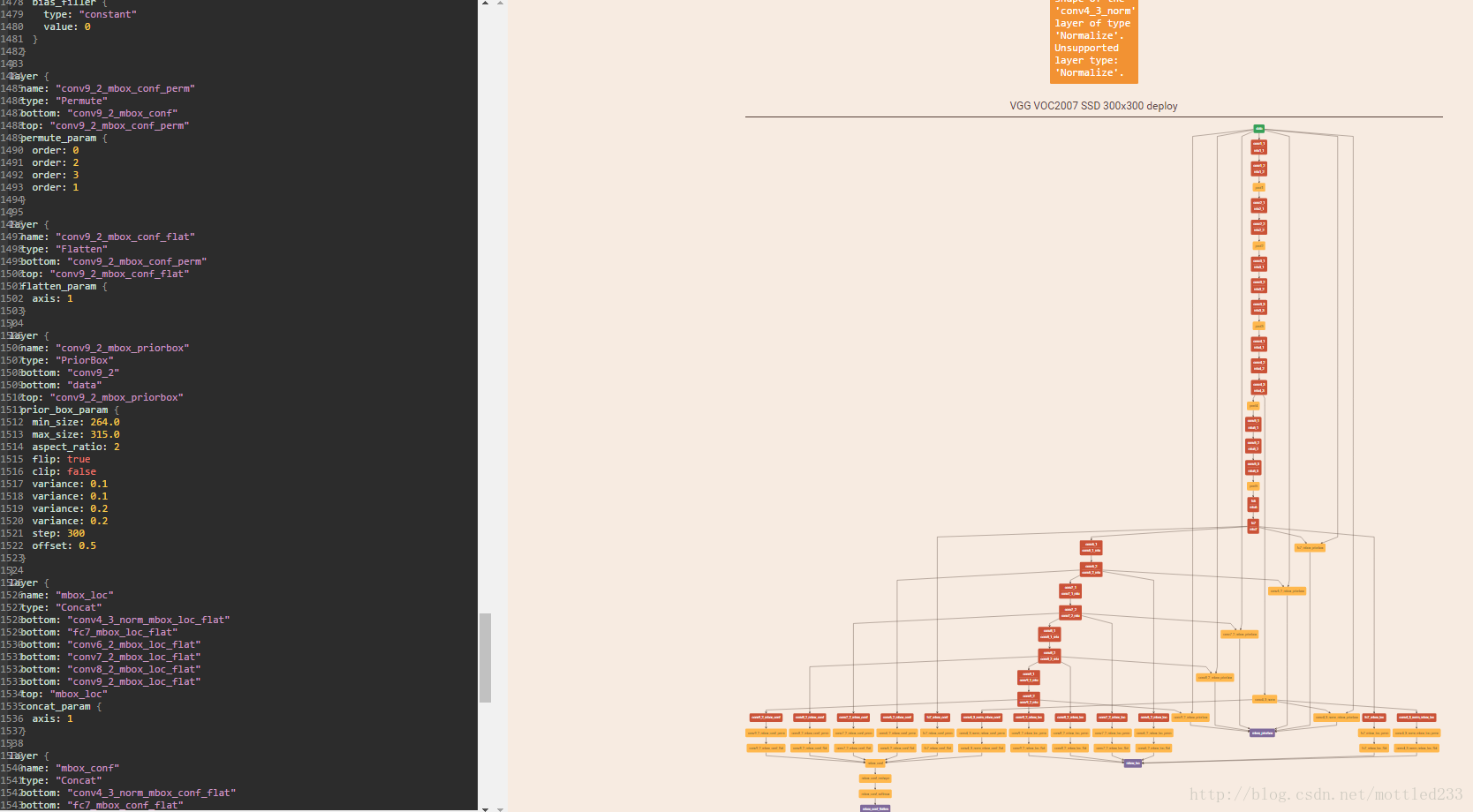
SSD(300x300)的網路結構如圖所示。

與 Fast R-CNN、Faster R-CNN 相似,這幾種檢測網路都用相同預訓練模型( ICLR 2015, VGG16),
並在 ILSVRC CLS-LOC 資料集上進行了預訓練
所以網路在圖上可以分為兩部分,前半部分是VGG-16的基礎網路(base network)
而後半部分是額外特徵層。
使用下圖可以看得更加清晰
state-of-art 的檢測系統大致都是如下步驟是:
- 根據生成邏輯(Selective Search等)生成一系列候選框
- 在這些候選框中提取特徵
- 經過一個分類器,來判斷裡面是不是物體,是什麼物體
- 非極大值抑制
但這類方法對於嵌入式系統,所需要的計算時間太久了,不足以實時的進行檢測。當然也有很多工作是朝著實時檢測邁進,但目前為止,都是犧牲檢測精度來換取時間
而ssd模型的原理是
- Multi-scale feature maps for detection
在基礎網路結構後,添加了額外的卷積層,這些卷積層的大小是逐層遞減的,可以在多尺度下進行預測。
Convolutional predictors for detection
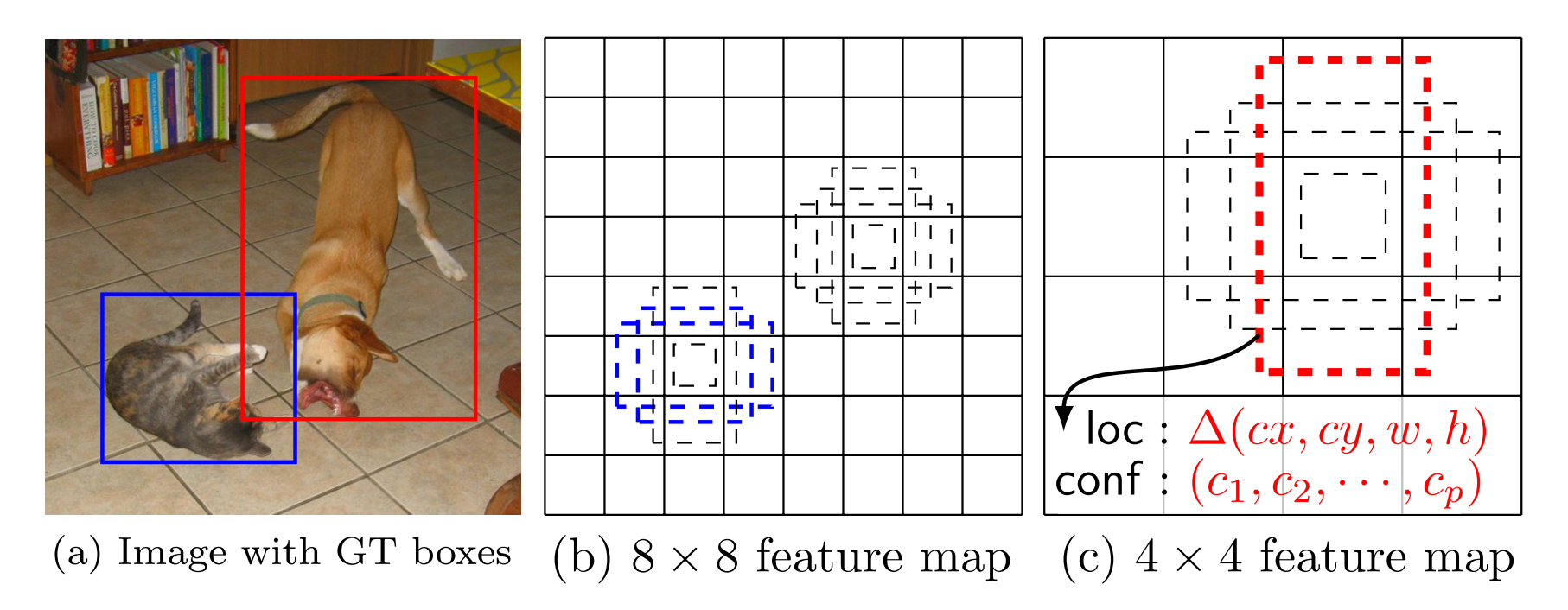
每一個新增的特徵層(或者在基礎網路結構中的特徵層),可以使用一系列卷積核,去產生一系列固定大小的 預測結果,具體見下圖。對於一個大小為 m×n,具有 p 通道的特徵層,使用的卷積核就是 3×3×p 的 kernels。產生的預測結果,那麼就是歸屬類別的一個得分,要麼就是相對於預設邊界框的位置偏移量(offset)。
在每一個 m×n 的特徵圖位置上,使用上面的 3×3 的 kernel,會產生一個輸出值。預測邊界框的位置偏移量值是輸出的預設邊界框位置與此時 feature map location 之間的相對距離(YOLO 架構則是用一個全連線層來代替這裡的卷積層)。
Default boxes and aspect ratios
每一個 box 相對於與其對應的特徵圖的“格”(feature map cell) 的位置是固定的。 在每一個 feature map cell 中,我們要預測得到的邊界框,與預設生成的邊界框(default boxes)之間的偏移量(offsets),以及每一個預測邊界框中包含物體的得分(每一個類別概率都要計算出)。
因此,對於一個位置上的 k 個邊界框中的每一個,我們需要計算出 c 個類,每一個類的分類得分,還有這個 邊界框相對於它的預設生成邊界框 的 4 個偏移值(offsets)。於是,在特徵圖中的每一個格上,就需要有 (c+4)×k 個卷積濾波核。對於一張 m×n 大小的特徵圖,即會產生 (c+4)×k×m×n 個輸出結果。Hard negative mining
在生成一系列的 predictions 之後,會產生很多個符合 ground truth box 的 predictions boxes,但同時,不符合 ground truth boxes 也很多,而且這個 negative boxes,遠多於 positive boxes。這會造成 negative boxes、positive boxes 之間的不均衡。訓練時難以收斂。
因此,本文采取,先將每一個物體位置上對應 predictions(default boxes)是 negative 的 boxes 進行排序,按照 default boxes 的 confidence 的大小。 選擇最高的幾個,保證最後 negatives、positives 的比例在 3:1。
本文通過實驗發現,這樣的比例可以更快的優化,訓練也更穩定。Data augmentation
本文同時對訓練資料做了 data augmentation,資料增廣。關於資料增廣,推薦一篇文章:Must Know Tips/Tricks in Deep Neural Networks,其中的 section 1 就講了 data augmentation 技術。
每一張訓練影象,隨機的進行如下幾種選擇:- 使用原始的影象
- 取樣一個 patch,與物體之間最小的 jaccard overlap 為:0.1,0.3,0.5,0.7 與 0.9
- 隨機的取樣一個 patch
取樣的 patch 是原始影象大小比例是 [0.1,1],aspect ratio 在 0.5 與 2 之間。
當 groundtruth box 的 中心(center)在取樣的 patch 中時,我們保留重疊部分。
在這些取樣步驟之後,每一個取樣的 patch 被 resize 到固定的大小,並且以 0.5 的概率隨機的 水平翻轉(horizontally flipped)
,
相關推薦
【深度學習】實時物體檢測框架Single-Shot MultiBox Detector(SSD)(1)概述
一、ssd使用場景及效能分析 目標檢測是深度學習影象識別的技術領域,指對單張圖片中的物體的類別和位置進行標註。在ssd中,位置資訊是通過邊界框(bounding-boxes)來描述的。 邊界框是一組四個資料,xmin,ymin,xmax,ymax(VOC標準
深度學習【50】物體檢測:SSD: Single Shot MultiBox Detector論文翻譯
SSD在眾多的物體檢測方法中算是比較重要的。之前學習過,但是沒過多久就忘了,因此決定將該論文翻譯一下,以加深印象。 Abstract 我們提出了用單個深度神經網路進行物體檢測的方法,稱為SSD。在每個特徵圖中的每個位置,SSD將bbox(bounding
【深度學習】線性迴歸(三)使用MXNet深度學習框架實現線性迴歸
文章目錄 概述 程式碼 概述 這篇文章使用MXNet深度學習框架中的Gluon包實現小批量隨機梯度下降的線性迴歸問題。可以參考我的上一篇文章【深度學習】線性迴歸(二)小批量隨機梯度下降及其python實現。 主要包
【深度學習:目標檢測】RCNN學習筆記(10):SSD:Single Shot MultiBox Detector
之前一直想總結下SSD,奈何時間緣故一直沒有整理,在我的認知當中,SSD是對Faster RCNN RPN這一獨特步驟的延伸與整合。總而言之,在思考於RPN進行2-class分類的時候,能否借鑑YOLO並簡化faster rcnn在21分類同時整合faster rcnn中anchor boxes實現m
【深度學習】基於MatConvNet框架的CNN卷積層與特徵圖視覺化
【題目】 程式設計實現視覺化卷積神經網路的特徵圖,並探究影象變換(平移,旋轉,縮放等)對特徵圖的影響。選擇AlexNet等經典CNN網路的Pre-trained模型,視覺化每個卷積層的特徵圖(網路輸入圖片自行選擇)。其中,第一層全部視覺化,其餘層選
【深度學習】---行人檢測應用
行人檢測綜述 涉及論文 主要圍繞王曉剛的幾篇關於深度學習在行人檢測的應用。 Ouyang, W. and X. Wang (2013). “Joint Deep Learning for Pedestrian Detection.” 2056-2
【深度學習】詞的向量化表示
model ref res font 技術 訓練 lin 挖掘 body 如果要一句話概括詞向量的用處,就是提供了一種數學化的方法,把自然語言這種符號信息轉化為向量形式的數字信息。這樣就把自然語言理解的問題要轉化為機器學習的問題。 其中最常用的詞向量模型無非是 one-h
【深度學習】批歸一化(Batch Normalization)
學習 src 試用 其中 put min 平移 深度 優化方法 BN是由Google於2015年提出,這是一個深度神經網絡訓練的技巧,它不僅可以加快了模型的收斂速度,而且更重要的是在一定程度緩解了深層網絡中“梯度彌散”的問題,從而使得訓練深層網絡模型更加容易和穩定。所以目前
【深度學習】常用的模型評估指標
是我 初學者 cnblogs 沒有 線下 均衡 顯示 總數 效果 “沒有測量,就沒有科學。”這是科學家門捷列夫的名言。在計算機科學中,特別是在機器學習的領域,對模型的測量和評估同樣至關重要。只有選擇與問題相匹配的評估方法,我們才能夠快速的發現在模型選擇和訓練過程中可能出現的
【深度學習】吳恩達網易公開課練習(class2 week1 task2 task3)
公開課 網易公開課 blog 校驗 過擬合 limit 函數 its cos 正則化 定義:正則化就是在計算損失函數時,在損失函數後添加權重相關的正則項。 作用:減少過擬合現象 正則化有多種,有L1範式,L2範式等。一種常用的正則化公式 \[J_{regularized}
【深度學習】深入理解ReLU(Rectifie Linear Units)激活函數
appdata 稀疏編碼 去掉 ren lock per 作用 開始 href 論文參考:Deep Sparse Rectifier Neural Networks (很有趣的一篇paper) Part 0:傳統激活函數、腦神經元激活頻率研究、稀疏激活性
【深度學習】一文讀懂機器學習常用損失函數(Loss Function)
back and 們的 wiki 導出 歐氏距離 classes 自變量 關於 最近太忙已經好久沒有寫博客了,今天整理分享一篇關於損失函數的文章吧,以前對損失函數的理解不夠深入,沒有真正理解每個損失函數的特點以及應用範圍,如果文中有任何錯誤,請各位朋友指教,謝謝~
【深度學習】ubuntu16.04下安裝opencv3.4.0
form 線程 ubunt con sudo ive tbb 依賴包 復制代碼 1、首先安裝一些編譯工具 # 安裝編譯工具 sudo apt-get install build-essential # 安裝依賴包 sudo apt-get install cmake
【深度學習】Pytorch 學習筆記
chang www. ans 如何 ret == 筆記 etc finished 目錄 Pytorch Leture 05: Linear Rregression in the Pytorch Way Logistic Regression 邏輯回歸 - 二分類 Lect
【深度學習】Semantic Segmentation 語義分割
翻譯自 A 2017 Guide to Semantic Segmentation with Deep Learning What exactly is semantic segmentation? 對圖片的每個畫素都做分類。 較為重要的語義分割資料集有:VOC2
【深度學習】Drop out
來源:Dropout: A Simple Way to Prevent Neural Networks from Overfitting 1. 原理 在每個訓練批次的前向傳播中,以概率p保留部分神經元。目的是:簡化神經網路的複雜度,降低過擬合風險。 根據保留概率p計算一個概率向量r
【深度學習】Tensorboard 視覺化好幫手2
轉自https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/4-2-tensorboard2/ 目錄 要點 製作輸入源 在 layer 中為 Weights, biases 設定變化
【深度學習】Tensorboard 視覺化好幫手1
轉自https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/4-1-tensorboard1/ 注意: 本節內容會用到瀏覽器, 而且與 tensorboard 相容的瀏覽器是 “Google Chrome”.
【深度學習】Tensorflow函式詳解
目錄 tf.truncated_normal tf.random_normal tf.nn.conv2d tf.nn.max_pool tf.reshape tf.nn.softmax tf.reduce_sum tf.reduce_max,tf.r
【深度學習】Tensorflow——CNN 卷積神經網路 2
轉自https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/5-05-CNN3/ 目錄 圖片處理 建立卷積層 建立全連線層 選優化方法 完整程式碼