
【逆向工程2】反爬蟲機制報告
今天的主題是反爬蟲機制,網站如何能保護好自己的資料,又不影響正常使用者體驗,所謂當今業界一場持久的攻防博弈。
一階爬蟲(技術篇)
應用場景一:靜態結果頁,無頻率限制,無黑名單。
攻:直接採用scrapy爬取
防:nginx層寫lua指令碼,將爬蟲IP加入黑名單,遮蔽一段時間(不提示時間)
應用場景二:靜態結果頁,無頻率限制,有黑名單
攻:使用代理(http proxy、VPN),隨機user-agent
防:加大頻率週期,每小時或每天超過一定次數遮蔽IP一段時間(不提示時間)
應用場景三:靜態結果頁,有頻率限制,有黑名單
攻:使用代理,隨機1-3秒爬取,爬10秒休息10秒,甚至範圍時間爬取,增加機器
防:當5分鐘內請求超過60次,彈出驗證碼頁面,通過驗證增加5分鐘無限制時間,不通過驗證碼則遮蔽增加一小時 (時間自擬)
應用場景四(Amazon):靜態結果頁,有頻率限制,有黑名單,有驗證碼
攻:python+tesseract驗證碼識別庫模擬訓練,或基於tor、crawlera(收費)的中介軟體(廣度遍歷IP)
防:前端非同步載入js,動態加密token
應用場景五(Aliexpress):動態結果頁,有頻率限制,有黑名單,有驗證碼
攻:python+Selenium,利用chrome核心載入動態結果頁,更推薦用node+hex+ie核心做一個爬取客戶端。java程式可以參考
防:見二階爬蟲
一階爬蟲屬於單純的技術性博弈,下面開始真正的人機互動博弈
二階爬蟲(進階篇)
應用場景六(PC天貓搜尋頁):https,動態結果頁,有頻率限制,無黑名單,有驗證碼
防:基於個性化為主導,提倡使用者主動登陸來獲取更優質的使用者體驗。根據購買習慣為使用者推薦一些正常促銷的商品,如9.9洗髮露、沐浴露、茶葉等(威露士經常做),以及一些優質的鑽展商品。不但能區別人機,還能蒐集使用者訪問喜好,針對性優化個性化大資料,還可以抵禦ddos,可謂一舉三得
攻:蒐集刷單賬號,用分散式任務
應用場景七(生意參謀):https,React單頁面應用,有驗證碼,LocalStorage,機器學習中介軟體
防:生意參謀本身是收費類的官方服務,從內測http過渡到https,而且近期加大對採集行為的打擊,直接採取封號警告策略。以增加使用者採集成本為限制,約束攻擊方收斂性為。
單頁面應用訪問是遵循一定正常軌跡的。例如請求:
1. 使用者資訊獲取
2. 資料列表1
3. 資料列表2
4. 資料詳情1
…
針對資料視覺化應用,大部分資料是經計算分析得到,並不會經常改變(甚至不變)。那麼,資料結果儲存入LocalStroage中,不但節省了網路請求加快頁面速度(相當於快取),還能區分使用者行為軌跡。
詳細的來說,通過程式程式設計得到的爬蟲,無論是基於url request,還是基於解壓webkit(如:jxbrower)。所生成的爬蟲物件都是臨時物件,那麼不會儲存LocalStroage資料,因此導致,訪問資料頁的請求軌跡每次都會是
1. 使用者資訊獲取
2. 資料列表1(實際應被儲存到LocalStroage)
3. 資料列表2(實際應被儲存到LocalStroage)
4. 資料詳情1
…
而正常使用者行為(一直通過瀏覽器訪問重複頁面)
1. 使用者資訊獲取
2. 資料詳情1
… 總之,不會請求LocalStorage裡有的
加解密的JS程式碼
setItem: function(e, t) {
return void 0 === t ? this.removeItem(e) : (localStorage.setItem(e, this._serialize(t)),
t)
},
getItem: function(e) {
return this.deserialize(localStorage.getItem(e))
},
另外,單頁面應用是非同步載入資料,一個頁面種有ABC三類,只有A類需要驗證碼時用dialog佔屏,BC類資料正常顯示,爬蟲開發時必然考慮不到這些情況,驗證碼並非強制要求輸入(重新整理後照常訪問)
還可以分析每天使用者請求數,訪問習慣等等
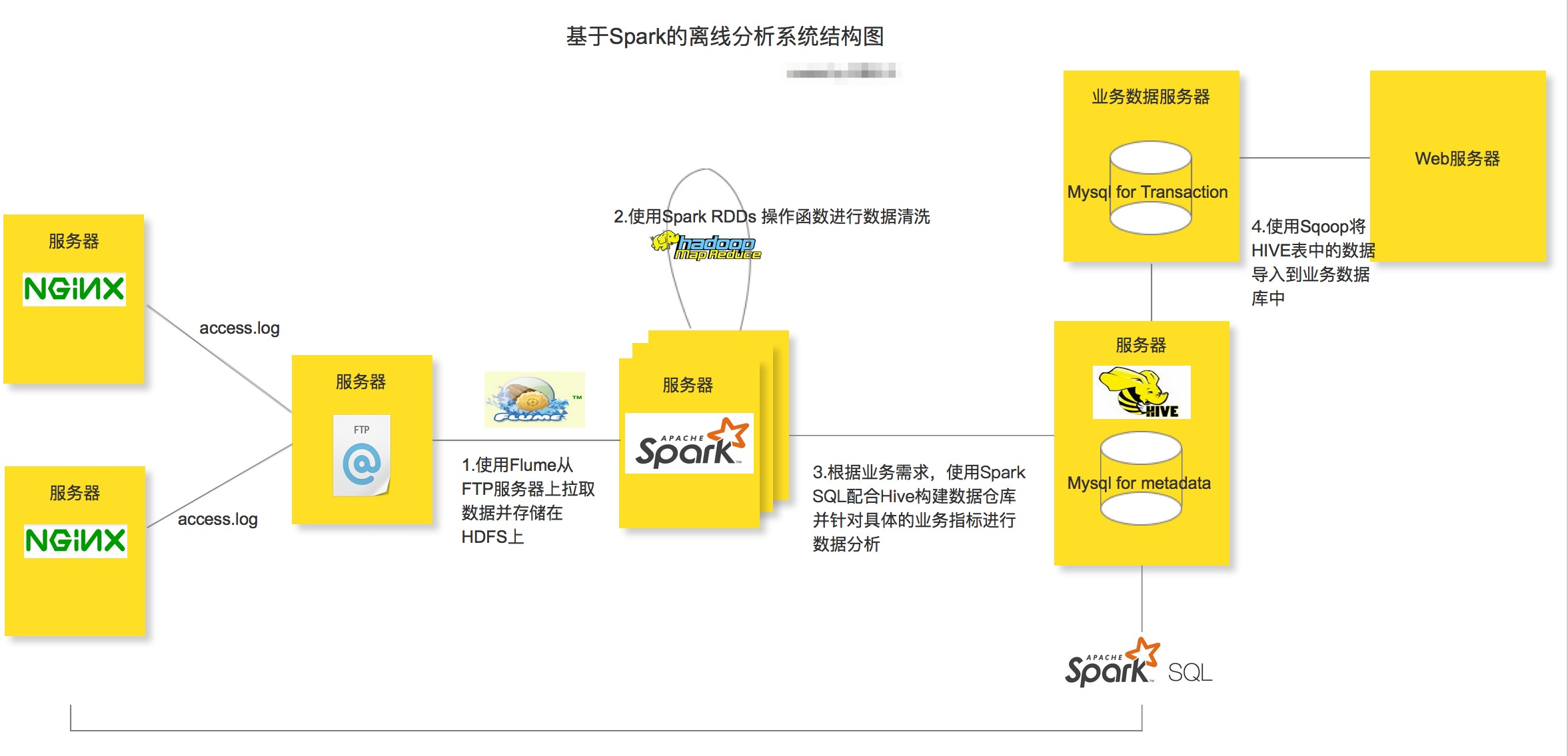
分析使用者行為軌跡的方式大致有3種:nginx流量中介軟體,web controller層攔截器,日誌收集(flume + hadoop + sperk)* 。可能基於貝葉斯或決策樹分析【實際怎麼算只有開發者知道】
曾經被封過一次, 不是實時性的第二天才被封, 所以應該時 日誌離線計算 得出的結果
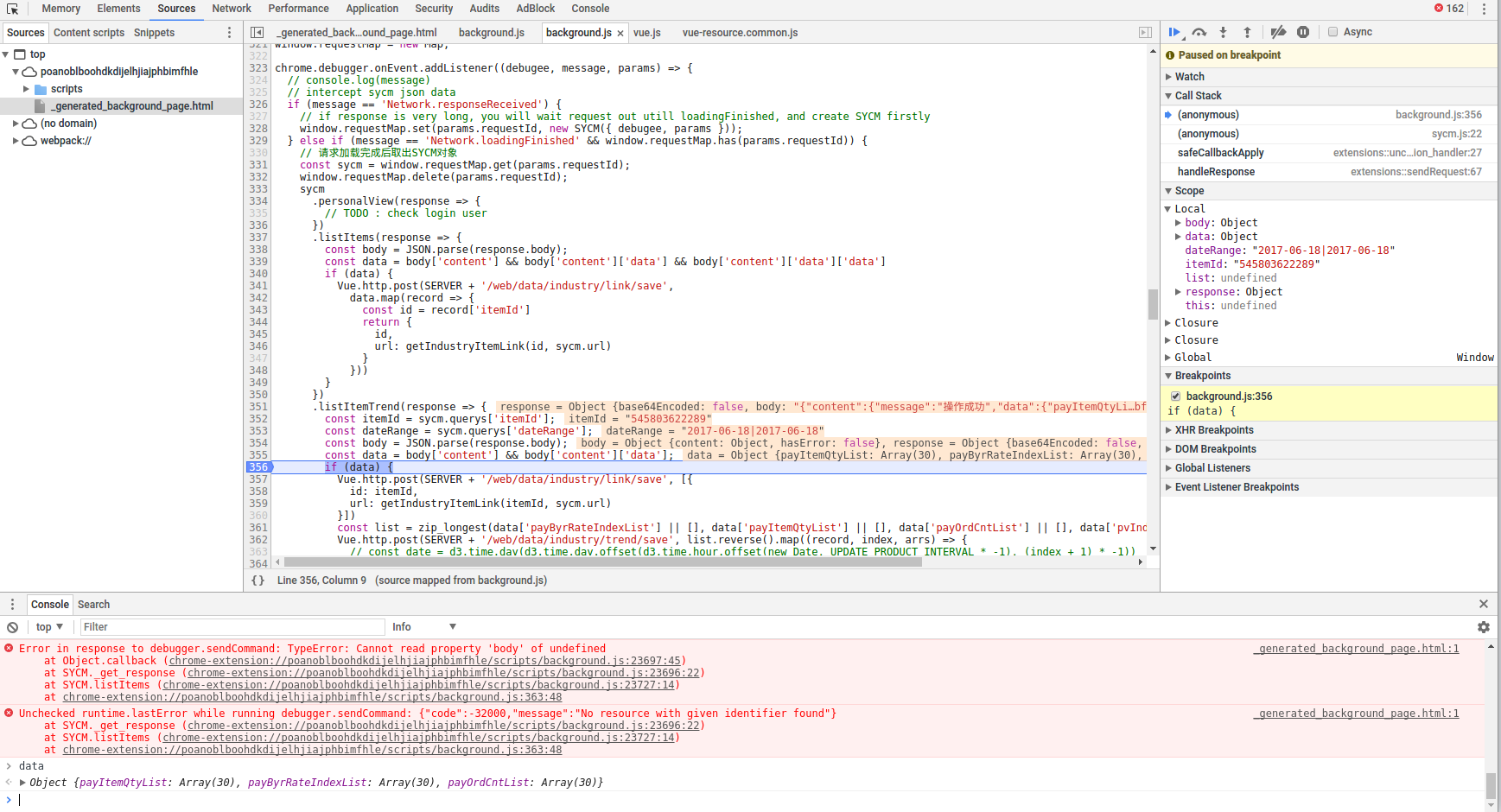
攻:chrome外掛(可獲取https流量),另外把頁面中的跳轉連結記錄到資料庫中. 因為一些連結只需要修改日期或ID等引數就可以複用. 連結中的一些鉚點可能就是計算用於軌跡的因素. PS:這也是生意參謀一直警告的方式, 所有行為由讀者自行負責, 與本文作者無關
三階爬蟲(反攻篇)
講道理攻擊方為何需要去爬取電商平臺的資料,就為一個目的,逆演算出平臺的權重計算,推匯出各類合理範圍內的指標(配合刷單,刷流量)。從技術層面上,永遠是一個相互博弈的過程,如果有人下血本採用半人工,堆機器的方式暴力抓取,也是難以防控的。而且眾所周知,電商技術的轉化含金量非常高,機器和人工的成本就是九牛一毛,如果你的模型與業務模型擦邊,輔助上一些內部渠道,無論是作為商家還是服務商都極快的變現
因此,反爬蟲的最終核心點是要讓攻擊者不知道自己已經被判定為爬蟲了。那麼,攻擊者只會悠哉的爬取資料,並興高采烈的開始演算。而從平臺方我們的最終目的是為了保護我們的資料和模型,那麼關鍵點就來了。需要是讓攻擊方獲取得資料不具有代表性,模型不可行即可。配合上流量木桶,定位到攻擊者,我們將原始資料進行一些離散加工,加入一些噪音,讓攻擊方往錯誤的方向上推導模型。最終攻擊方講無法區分哪些資料是可用,那些又是噪音。
這時候,你會說,如果系統誤殺正常使用者,給出個一些展示資料錯的離譜怎麼辦。這個度其實很好把握,我們只需要在排名*、成交單數、點選率等此類動態變化的維度加入噪音,不去加工價格、運費、產品詳情,即使被程式判定為攻擊者,並不影響正常使用者的體驗