
人臉識別之人臉對齊(七)--JDA演算法
其實,這裡JDA之前在人臉檢測中解釋過,這裡再轉一篇的目的在於,此文更貼近論文,同時,JDA本來包含人臉檢測和人臉對齊,作為一個整體訓練和測試的。
轉自:http://blog.csdn.net/shixiangyun2/article/details/50809078
第一節:
關鍵思想是將人臉檢測和人臉標點結合起來。
一個應用比較廣泛的人臉檢測方法,Viola-Jones檢測器是基於以下兩個原則進行檢測的:1,逐步提升的級聯結構;2,簡單的特徵。這種方法在日常生活場景中效果不甚理想。
其他有許多工作是針對多視角的人臉檢測【10,17,27,7】他們採用分治策略——在不同視角和頭部姿態下,分別訓練不同的檢測器。這種做法往往更加麻煩,使得系統性能和準確度降低。
一些創新的方法不再使用Boosted-cascade方法,如【32】(2012年)文獻之中,在多視角和多表情情況下,採用部分可變形混合模型來捕獲大規模人臉變化。這種模型很複雜並且可以同時進行人臉檢測,表情評估和麵部標點。【24】使用基於模範樣本的人臉檢測器並利用影象檢索技術,避免了費時的滑動視窗搜尋。這些新方法在一些比較難的相簿上的效果都比V-J要好得多【32,9】。然而這些方法,由於複雜性太高(【32】處理一張圖需要40秒),不太容易實用。
在本文中,演算法的效能和準確度都很高。仍然遵從boosted-cascade方法的原則——“提升級聯結構+簡單特徵”。使用畫素差作為特徵使得高效能得到保證。我們的演算法在VGA影象(640*480pixel)上的檢測效能是28.6ms/張。
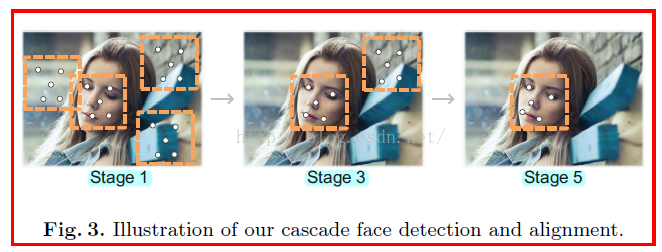
本文中的系統明顯優於其他系統【32,9,22】和一些商業系統,圖一所示說明我們的系統在多視角,遮擋和低光照度的情況下也能很好的完成檢測。
系統執行結果——在比較困難的場景也能完成檢測和標點

我們最初的動機是發現了精確的人臉標點對於判斷是否有臉很有裨益。
在第二節,我們實驗發現在後級處理階段,一個簡單的基於面部標定點特徵的SVM分類器可以極大地提高V-J檢測器的準確度。這一現象的原因是,面部標定可以找到人臉區域直接的對應關係,使得各區域可以直接對比,這簡化了人臉/非人臉的分類問題。
我們的問題是,當需求得到高召回率的時候,級聯的檢測器會返回很多錯誤的正樣本視窗,這使得SVM分類器判別減慢。
我們的方法靈感源於最近在級聯人臉標點上的研究【19,4,28,29,21】,這些研究中,人臉形狀通過提升的迴歸器逐漸更新。每一級上的迴歸器學習不僅取決於影象資訊,也取決於從前一級迴歸器估計到的形狀。這種方式的特徵學習稱之為形狀索引特徵。這種特徵在人臉形狀發生幾何變化上呈現出更高的不變性。這對獲得高的標點準確率和速度而言是很重要的。
由於級聯結構在檢測和標點上具有如此好的表現,我們提出的方法,將二者結合起來,相得益彰。
在第三節,我們提出一個同一的框架流程,將檢測和標點結合起來。由於嵌入了標點資訊,檢測環節的訓練學習變得更加高效。而且,人臉標點也是同時完成了。
在第四節,在我們新的框架下,我們拓展近期一個很前沿的標點方法【21】,我們展現了怎樣同時使用簡單的形狀索引特徵進行人臉檢測,以使得系統更高效。我們首次提出了聯合人臉檢測和人臉標點的方法,並首次展現了簡單形狀索引特徵對於人臉檢測也很高效。
在第五節,我們證明了我們方法在準確度和速度方面的超高效能。
第二節:標點如何幫助檢測人臉:一個後級的分類器。
1,使用OpenCv中的V-J檢測器,在一個比較低的閾值下檢測,以保證一個高的召回率。
2,將得到許多影象視窗,其中有許多是false positive(錯誤的正樣本),將這些視窗分為真假正樣本兩部分,用於訓練一個線性SVM分類器。
3,在測試的時候,將V-J檢測器輸出的視窗,送人SVM分類器中進行篩選。
所有的視窗都被歸一化到96*96pixel大小
我們實驗了幾種不同的特徵,是否使用標定點,結果如下:
a.將視窗分為6*6各不重疊的部分,在每一塊區域上進行SIFT描述子的提取。
b.選用27個面部的平均形狀點,並以這些點為中心,提取SIFT描述子。
c.按照【21】中演算法得到面部的27標點,並且以此為中心提取SIFT描述子。
上述三種情況下,所有的SIFT描述子都被連線成一個向量,送入SVM訓練。
畫出測試實驗中的分類情況分佈圖,(1)是原始的V-J檢測器,(2)(3)(4)分別是結合了上述三種特徵下訓練的SVM分類器的分類結果

實驗得出,利用了標定點資訊使得那些很難判斷的視窗可以得到有效的判決。
考慮到高效能的需求,對於一個標準的級聯檢測器來說,若需求高召回率時,基於人臉標點的後級分類器會顯得很慢。我們的實驗中,設定了前級V-J檢測器的召回率為99%,每個輸入圖片會得到3000個輸出視窗,再應用後級分類器往往需要幾秒的時間。——這很慢
第三節:一個統一的級聯人臉檢測和標點的框架
為了更好的利用標點資訊,我們提出了一個統一的框架。
級聯的檢測:
不失一般性,分類分數為:

測試一個待判決的視窗x時,每個弱分類器循序地評估,一旦出現f^n<cita^n,n=1,2,3...N。則立即將此視窗拒絕掉。級聯的檢測中,負視窗很快會被拒絕,使得其效能很高。
級聯的標定:
我們使用了一種結合姿態索引特徵和提升迴歸的姿態迴歸框架。這種框架在【4,28,29,21】中都證明了其人臉標點的高效性。
我們定義形狀S為一個2L維的向量,L是標點總數。逐步迴歸的過程是

每一個Rt是一個迴歸函式,它會在前一級形狀的基礎上增加一個形狀增量。學習時使當前形狀St與真實形狀S之間的誤差最小。——在所有的樣本上考慮這個誤差。如下式所示:

一個關鍵的創新點在於,在級聯標點框架中,每一個迴歸器Rt依賴於前一個形狀S(t-1),在訓練學習的過程中,特徵定義為與S(t-1)相關,所以稱之為姿態/形狀索引特徵【19,4】,這種特徵對面部形狀變化時,呈現出很好的幾何不變性。
將這種姿態/形狀索引特徵同樣的應用在檢測環節,方法是讓學習弱分類器的式(1)也依賴於人臉形狀資訊。注意到式(1)中的弱分類器的數目N通常是幾百上千的規模,遠比標點過程中層級T要大(T一般小於10)。為了統一這兩個訓練學習任務,我們將所有的N個弱分類器分為T個層級,每個層級有K=N/T個弱分類器。這樣方程(1)的形式變為如下(4)所示:

原則上,每一層級的迴歸函式和分類函式,不是一定需要同時訓練學習和應用。但是為了讓兩個環節使用同樣的特徵,為了加速效能,我們同時進行兩個環節的訓練學習。
演示了我們測試演算法的過程,負影象視窗逐漸被拒絕,並且正影象窗中人臉標定點的位置也不斷被校正。下一節,我們將呈現這種聯合學習方法。
第四節:我們的方法
如第三節所示,【4,28,29,21】中的標點方法都可以用來進行人臉檢測,我們選擇其中最新並且效果最好的一篇【21】,它其中的演算法最精準,最快,並且容易整合檢測過程中的弱分類器學習。
4.1 回顧【21】中的標點方法
迴歸函式Rt是K個基於樹的迴歸量的和
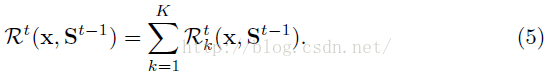
每一個迴歸量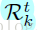
怎麼學習所有的決策樹(蕨)
1,估計每一個標定點位置的增量——區域性點的樹結構學習:
對每一個標定點,使用形狀索引畫素差特徵【4】,訓練學習一個標準的迴歸森林【2】,來估計這個點的增量。
2,全域性的樹輸出的訓練學習:
葉子上儲存單個標定點的增量的方法被棄置,相反的,每個葉子上儲存一個形狀增量(多個標定點的增量),並且所有的形狀增量使用方程(3)進行優化。注意到這是一個簡單的全域性線性迴歸問題。
演算法2是使用級聯人臉檢測和標點方法,對影象視窗x測試的過程。這個模型由所有的弱學習器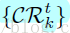
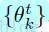

這個方法的優點在於這兩個步驟:
1,區域性學習即是在區域性塊上的單個點的迴歸,它在簡單的畫素特徵上可以達到更高的抵抗噪聲的能力(相比於【4】),同時,這種學習到的特徵比人工的SIFT特徵更加高效(【28】)。
2,全域性學習可以降低區域性標點的誤差和依賴,一旦給出固定的樹的結構,這個步驟能實現全域性的最優解,因此,這兩個訓練學習步驟實現了很強的區域性最優解(由方程(3)保證)
4.2 檢測和標點的聯合學習:
注意到,方程(4)中的弱分類器和方程(5)中的樹迴歸量具有相同的增加形式,所以我們提出在單個決策樹中同時學習分類器和迴歸量。也即,方程5中的每個迴歸樹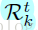
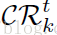


為了學習一個混合的分類/迴歸決策樹,我們在霍夫森林中使用了與文獻【6】中相同的策略(http://note.youdao.com/share/?id=14adbab56d90125d305e90c7268aa848&type=note):在進行每個節點的劃分時,我們隨機的選取要麼是最小化分類器的二進位制熵(概率為p),要麼最小化面部標定點在迴歸器中的增量的變化(概率為1-p),很直觀地,p在前級應該。儘量大,加快分類器拒絕負樣本視窗,後級時p應該小,使得迴歸器標點精度高
根據經驗,我們選取了一組隨迴歸層級t線性遞減的引數作為概率p
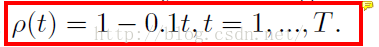
在進行樹內每個節點的分割時,我們對【4】中的形狀索引畫素差特徵進行了拓展——拓展為多尺度下的特徵。具體的,我們通過下采樣得到輸入影象在三種尺度下的影象(源影象,二分之一下采樣,四分之一下采樣)。為了生成特徵,我們隨機的選擇了一個影象尺度(三選一),在當前面部標點中選擇隨機的兩個點,根據對應點生成兩個隨機的偏移量,將這兩個偏移下的畫素差作為特徵。我們發現這種多尺度的畫素差向量對噪聲更加魯棒,對人臉檢測也更加必要。
在級聯分類器訓練過程中,我們使用ReaLBoost演算法,在學習決策樹之前,每個樣本i都賦予一個權重
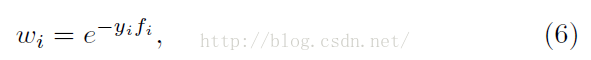
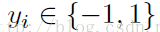
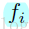
在每個樹的葉子節點處,分類分數由下式給出:
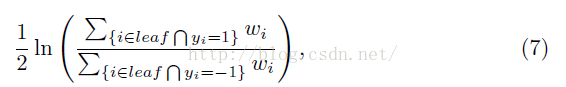
分子和分母分別是葉子節點上的所有正樣本和所有負樣本的權重之和
為了實現演算法3中,我們的訓練演算法。所有的人臉形狀都按照人臉框進行歸一化了。

1,輸入:所有訓練影象視窗樣本Xi,類別Yi(1/-1)
2,輸入:正樣本視窗中的標定點真實形狀,人為標定獲取
3,輸出:輸出所有得到的弱分類器

4,初始化所有樣本的形狀S(i,0),——通過在平均形狀(針對所有Xi)上增加一個隨機擾量
5 實驗
我們從網際網路上收集了20000張人臉圖片和20000張其他圖片(無臉)。所有的臉被手工標註了27個面部點的位置。同時也可使用他們的翻轉圖片做訓練,全部使用灰度影象。
每個分類/迴歸樹的深度為4,對樹內每個節點的分割測試次數為2000.這個訓練在16核的機器上花費了3天。
然後,我們如第二節所述,使用訓練圖片集的輸出視窗(有很多,分正負)訓練了基於標定點的SVM分類器,在檢測環節,我們使用了標準的滑動視窗搜尋。檢測器的輸出視窗再送入SVM分類器進行判決。所有通過SVM分類器的視窗,再通過一個裁剪過程:視窗矩形框會聚集起來,從矩形框叢集中選擇一個框作為最終的輸出。
評估時採用了三個很具挑戰的公開庫:FDDB,AFW,AMU-MIT。這些庫不包含我們的訓練圖片。FDDB和AFW是在外部環境下采集的。CMU-MIT是一個稍微過時但是人臉質量較低且與其他兩個庫區別較大的庫,我們用來測試檢測器的容量。。。
5.1 標點對檢測的影響:
下圖給出我們的方法與基準方法的對比,以證明標點對人臉檢測的影響。基準檢測器是採用相似的方式進行訓練的,只是缺失了演算法3的24行,基準的演算法中人臉形狀始終保持為最初的平均形狀。它有點類似標準V-J風格的級聯檢測器。
