
python爬蟲利器 scrapy和scrapy-redis 詳解一 入門demo及內容解析
阿新 • • 發佈:2020-10-29
## 架構及簡介
Scrapy是用純Python實現一個為了爬取網站資料、提取結構性資料而編寫的應用框架,用途非常廣泛。
Scrapy 使用了 Twisted(其主要對手是Tornado)非同步網路框架來處理網路通訊,可以加快我們的下載速度,不用自己去實現非同步框架,並且包含了各種中介軟體介面,可以靈活的完成各種需求。
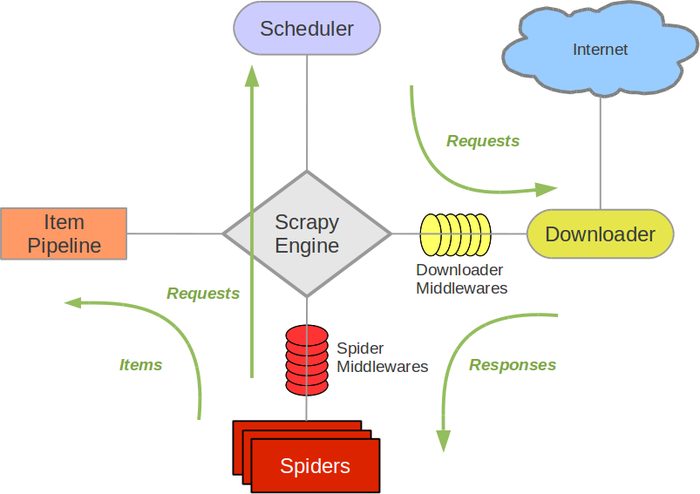
Scrapy Engine(引擎): 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,訊號、資料傳遞等。
Scheduler(排程器): 它負責接受引擎傳送過來的Request請求,並按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎。
Downloader(下載器):負責下載Scrapy Engine(引擎)傳送的所有Requests請求,並將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理,
Spider(爬蟲):它負責處理所有Responses,從中分析提取資料,獲取Item欄位需要的資料,並將需要跟進的URL提交給引擎,再次進入Scheduler(排程器),
Item Pipeline(管道):它負責處理Spider中獲取到的Item,並進行進行後期處理(詳細分析、過濾、儲存等)的地方.
Downloader Middlewares(下載中介軟體):你可以當作是一個可以自定義擴充套件下載功能的元件。
Spider Middlewares(Spider中介軟體):你可以理解為是一個可以自定擴充套件和操作引擎和Spider中間通訊的功能元件(比如進入Spider的Responses;和從Spider出去的Requests)
## 開發流程
開發一個簡單爬蟲步驟:
- 新建專案
```
scrapy startproject demo
```
- 編寫spider
- 種子url (請求)
- 解析方法
- 編寫item
結果資料模型
- 持久化
編寫pipelines
## 生成目錄介紹
```
scrapy.cfg :專案的配置檔案
mySpider/ :專案的Python模組,將會從這裡引用程式碼
mySpider/items.py :專案的目標檔案
mySpider/pipelines.py :專案的管道檔案
mySpider/settings.py :專案的設定檔案
mySpider/spiders/ :儲存爬蟲程式碼目錄
```
## 使用命令建立爬蟲類
```
scrapy genspider gitee "gitee.com"
```
## 解析
通常我們解析都會涉及到 xpath csspath 正則,有的時候可能還有jsonpath(python中json訪問基本不用使用複雜的jsonpath,字典訪問就可以)
scrapy 內建xpath和csspath支援
### Selector
而解析器本身也可以單獨使用
- xpath()
- extract_first()
- extract() #返回一個列表
- 索引訪問,因為scrapy.selector.unified.SelectorList繼承list,可以通過索引訪問
```
from scrapy import Selector
if __name__ == '__main__':
body = """
Title
, ]
print(type(pe))
#
print(type(pe[0])) #通過索引訪問
#
print(type(pe.pop()))
#
p=s.xpath("//p").extract_first()
print(p)
```
- css()
css選擇器我們::text選擇內容,用::attr() 選擇屬性
```
print(s.css("title").extract_first())
print(s.css("title::text").extract_first())
print(s.css("title::text").extract())
print(s.css("p.big::text").extract_first())
print(s.css("p.big::attr(class)").extract_first())
# Title
```
** 但re()返回列表,.re_first返回str,所以不能再繼續呼叫其他的選擇方法
## 在爬蟲中使用解析器
response物件已經
```
class GiteeSpider(scrapy.Spider):
name = 'gitee'
allowed_domains = ['gitee.com']
start_urls = ['https://gitee.com/haimama']
def parse(self, response):
print(type(response))
t=response.xpath("//title/text()").extract_first()
print(t)
##啟動爬蟲執行後的結果
# 執行結果省略日誌
#
# 碼馬 (haimama) - Gitee
```
**response物件型別為 `scrapy.http.response.html.HtmlResponse`,該類繼承`TextResponse` 。擁有xpath()和css()方法如下**
**所以response 可以直接使用前文中的Selector 的方式來解析**
```
def xpath(self, query, **kwargs):
return self.selector.xpath(query, **kwargs)
def css(self, query):
return self.selector.css(query)
```
## 配置檔案
**settings.py是爬蟲的配置檔案,要正常啟動爬蟲的話,一定注意將robo協議限制 修改為 `ROBOTSTXT_OBEY = False`**
其他相關配置,我們下節再介紹
## 啟動爬蟲
在爬蟲目錄編寫run.py方法,新增如下指令碼,這樣就可以直接執行爬蟲了。如果命令列執行的話`scrapy crawl gitee`。其中gitee為爬蟲名,對應`GiteeSpider`中的`name`欄位
```
# coding: utf-8
from scrapy import cmdline
if __name__ == '__main__':
cmdline.execute("scrapy crawl gitee".split())
# scrapy crawl gitee
```
> 完整參考程式碼 https://gitee.com/haimama/scrapy_demo001
> xpath參考 我的部落格[python使用xpath](https://www.cnblogs.com/mxjhaima/p/1377584
hello
hello
""" s = Selector(text=body) title=s.xpath("//title/text()").extract_first();#抽取 print(title) #Title pe = s.xpath("//p") print(s.xpath("//p").extract()) #['hello
', 'hello
'] print(pe) #[hello big
#hello big