Python爬蟲學習6:scrapy入門(一)爬取汽車評論並儲存到csv檔案
阿新 • • 發佈:2019-02-20
一、scrapy 安裝:可直接使用Anaconda Navigator安裝, 也可使用pip install scrapy安裝
二、建立scrapy 爬蟲專案:語句格式為 scrapy startproject project_name

生成的爬蟲專案目錄如下,其中spiders是自己真正要編寫的爬蟲。
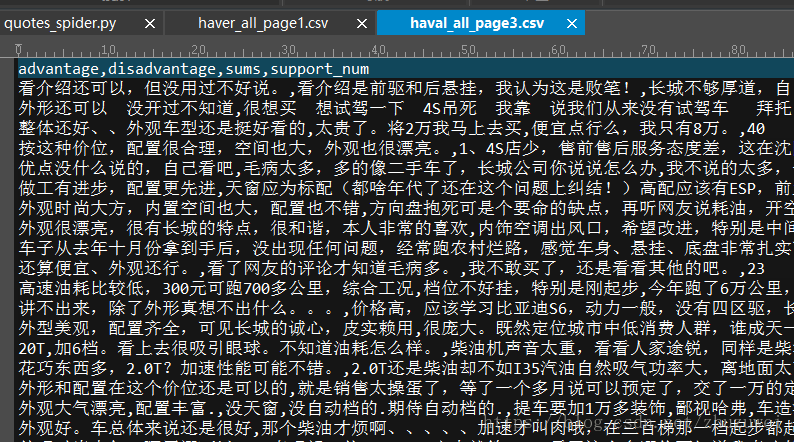
三、爬取騰訊新聞並儲存到csv檔案
1. 只爬取一個頁面:在spiders目錄下建立spider程式car_comment_spider.py 並編輯程式碼如下:
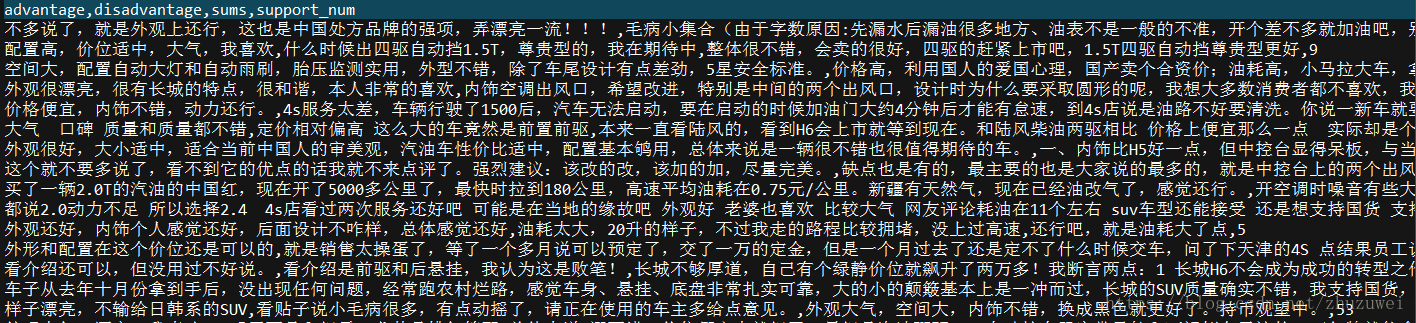
import scrapy class CarCommentSpider(scrapy.Spider): name = 'CarComment' # 蜘蛛的名字 # 指定要抓取的網頁 start_urls = ['https://koubei.16888.com/117870/'] # 網頁解析函式 def parse(self, response): for car in response.xpath('/html/body/div/div/div/div[@class="mouth_box"]/dl'): # 遍歷xpath advantage = car.xpath('dd/div[2]/p[1]/span[@class="show_dp f_r"]/text()').extract_first() disadvantage = car.xpath('dd/div[2]/p[2]/span[2]/text()').extract_first() sums = car.xpath('dd/div[2]/p[3]/span[2]/text()').extract_first() support_num = car.xpath('dd/div/div[@class="like f_r"]/a/text()').extract_first() print('優點:',advantage) print('缺點:',disadvantage) print('綜述:',sums) print('支援人數:',support_num)
在cmd命令列中執行scrapy runspider car_comment_spider.py

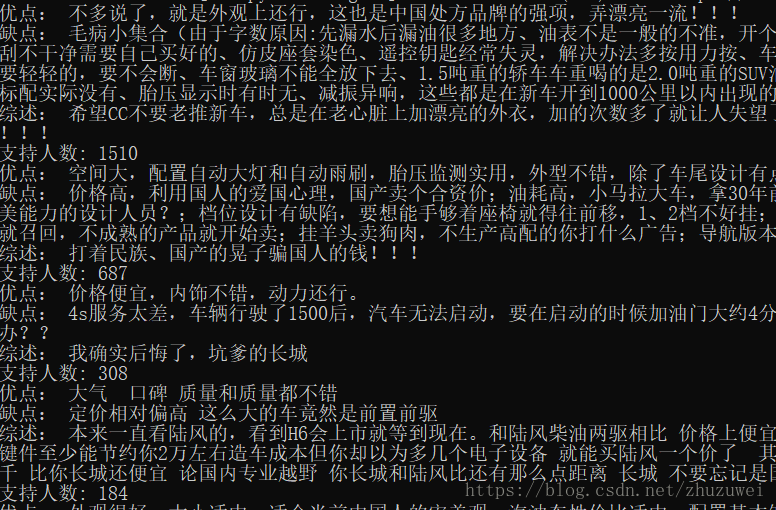
2. 爬取某個車型的所有評論並儲存到csv檔案
(1)自行組建不同頁面的url: 根據網頁url的規律可設定
start_urls = ['https://koubei.16888.com/117870/0-0-0-%s' % p for p in range(1,125)]
import scrapy class CarCommentSpider(scrapy.Spider): name = 'CarComment' # 蜘蛛的名字 # 指定要抓取的網頁, 從第1頁到第124頁,程式會自動解析每個url start_urls = ['https://koubei.16888.com/117870/0-0-0-%s' % p for p in range(1,125)] # 網頁解析函式 def parse(self, response): for car in response.xpath('/html/body/div/div/div/div[@class="mouth_box"]/dl'): # 遍歷xpath advantage = car.xpath('dd/div[2]/p[1]/span[@class="show_dp f_r"]/text()').extract_first() disadvantage = car.xpath('dd/div[2]/p[2]/span[2]/text()').extract_first() sums = car.xpath('dd/div[2]/p[3]/span[2]/text()').extract_first() support_num = car.xpath('dd/div/div[@class="like f_r"]/a/text()').extract_first() print('優點:',advantage) print('缺點:',disadvantage) print('綜述:',sums) print('支援人數:',support_num) if len(advantage) != 0 and len(disadvantage) != 0 and len(sums) != 0 and len(support_num) != 0: yield {'advantage':advantage, 'disadvantage':disadvantage, 'sums':sums, 'support_num':support_num}
(2)從每一頁的程式碼解析找到下一頁的url
下一頁的url在a標籤中,此處存在多個a標籤,故需要從中找到下一頁對應的a標籤

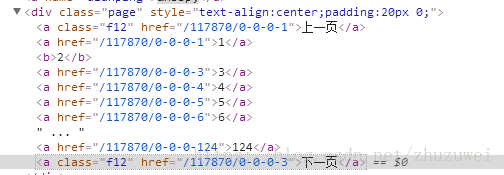
import scrapy class CarCommentSpider(scrapy.Spider): name = 'CarComment' # 蜘蛛的名字 # 指定要抓取的網頁, 從第1頁到第124頁,程式會自動解析每個url start_urls = ['https://koubei.16888.com/117870/0-0-0-1/'] # 網頁解析函式 def parse(self, response): for car in response.xpath('/html/body/div/div/div/div[@class="mouth_box"]/dl'): # 遍歷xpath advantage = car.xpath('dd/div[2]/p[1]/span[@class="show_dp f_r"]/text()').extract_first() disadvantage = car.xpath('dd/div[2]/p[2]/span[2]/text()').extract_first() sums = car.xpath('dd/div[2]/p[3]/span[2]/text()').extract_first() support_num = car.xpath('dd/div/div[@class="like f_r"]/a/text()').extract_first() print('優點:',advantage) print('缺點:',disadvantage) print('綜述:',sums) print('支援人數:',support_num) if advantage is not None and disadvantage is not None and sums is not None and support_num is not None: yield {'advantage':advantage, 'disadvantage':disadvantage, 'sums':sums, 'support_num':support_num} n = len(response.xpath('/html/body/div/div/div/div/div[@class="page"]/a')) for i in range(1,n+1): # 遍歷每個a元素,獲取下一頁的url text = response.xpath('/html/body/div/div/div/div/div[@class="page"]/a['+str(i)+']/text()').extract_first() if text == '下一頁': next_page = response.xpath('/html/body/div/div/div/div/div[@class="page"]/a['+str(i)+']/@href').extract_first() next_page = response.urljoin(next_page) # 將相對地址轉換為絕對地址 yield scrapy.Request(next_page, callback=self.parse) # next_page繼續進行spider解析