
演算法我也不知道有沒有下一個---一個題目的開端(索引堆與圖)
病痛了一週,折磨來折磨去,終於還是平靜了下來,現在能把上週末"貫穿"學到的最後一個基礎資料結構的知識給沉澱沉澱了。也是即將再單位分享的東西:圖論。這東西,想當年大二,學校的時候,只是理解或者畫圖,就已經很費勁了,當時我們平時作業包括後來的期末考試也只是到理解原理的層面,會畫圖,就行,實現什麼的,根本別想。我自己當年也是認真看過,死磕過幾個演算法的實現:最小生成樹、最短路徑等,然而,是看不懂的。這麼多年過去了,自己程式設計能力和見識多了,回過頭來,發現,其實並沒那麼難,只不過比平時的業務邏輯稍微複雜些,但是相較於框架的原始碼複雜度來說,還是遠遠夠不到的。這一次,我先以一道題開始,逐步將相關的知識點講下來,採取這種方式,最後,會拓展的講講其他的實現,恩,開幹
零、一些話
本次的題目,其實算是一道功能實現題,但是能很直接的看出使用的資料結構和大二資料結構課本中介紹的這種資料結構的基本幾個之一的演算法,所以非常考察當年本科計算機基礎的夯實程度與程式設計實踐能力。還是那句話,不要整天咔咔咔的寫個curd就覺得會程式設計,很牛逼。計算機能解決的問題,遠遠不止curd,程式設計能力也遠遠不止curd。同樣,這道題,也是一道面試題(具體出處,我就不說了),成敗與否,工資高與低,日子苦逼與否,可能往往取決於一道題,並非危言聳聽。有人覺得演算法沒用,平時用不到,都是api呼叫,我耗時耗力學,有啥回報呢,我能用來解決什麼問題呢?下面我來談談我的想法。
演算法,我覺得類似於我現在追的一部翻拍武俠劇《倚天屠龍記》中的兩部武學經典《九陽神功》與《乾坤大挪移》。張無忌整個過程中似乎並沒有學什麼具體的武功招式,與外家功夫,只學了這兩部內功聖經,就已經幹翻六大派高手,幹翻趙敏手下的一大堆的援軍與玄冥二老,稱霸武林。可是這兩部武學內功並沒有交張無忌一招一式啊!我覺得演算法如此。我們現在程式設計生活中,幾乎不用我們去實現連結串列,更不可能讓我們實現一個紅黑樹,更別提讓我們寫一個圖的深度遍歷,因為太多太多的框架都幫助我們實現了。然而,試想一種情況:如果一個開發者,能白板寫大頂堆小頂堆,能白板手寫紅黑樹,能立馬手動編碼實現一道基於資料結構的中等難度的LeetCode上面的習題,難道他不會呼叫spring的api?難道他不會寫個sql去查詢資料庫?我相信即使他不會,也比一般開發者學的快!更進一步,如果你發現你要根據具體的業務場景實現自己的業務負載均衡模型、在電信的業務模型中對具體的一個表示式進行解析(恩,我弄過)、在遊戲開發領域快速判斷兩點之間的連通性等等這些,都是必須要牢靠掌握資料結構與演算法能力的。哪怕是,我們想要更佳平滑的彌補HashMap的多執行緒坑,不懂資料結構,那是絕對不可能的。
也許百度百度,可能大家都能知道怎麼弄。可是自我思考得來的解決與百度來的解決,那是截然不同的兩種能力等級!解決問題的速度,也是不一樣的。更佳的,當面臨系統優化、制定規則引擎、寫一些系統工具,那演算法與資料結構就是無論如何都無法繞開的了。所以為什麼很多大廠面試,為啥願意面演算法,讓你手寫演算法,原因在此。本來就是更上了一個level啊!是否錄取一個應聘者,如何開工資,能力等級是多少,高下立判!
一、演算法原題
Kiwiland市的鐵路系統服務於多個城鎮。由於資金問題,所有線路均為“單向線路”。例如,由Kaitaia向Invercargill的方向有一條鐵路線,但反方向卻沒有路線。事實上,即使這兩個方向都有鐵路線,他們也可能是不同的線路軌跡,里程數也不一定相同。
這道題就是要幫助鐵路系統為乘客提供線路資訊。具體來講,你需要計算出某條線路的里程數,兩個城鎮之間的線路數量以及其中的最短線路。
**Input:**一個有向圖(directed graph),其中的節點表示一個城鎮,線表示兩個城鎮間的線路,線的權重表示距離。一條線路不得出現兩次或以上,且起點城鎮和終點城鎮不得相同。
**Output:**測試1至5,如果該線路不存在,則輸出 'NO SUCH ROUTE',否則就按照給定的線路行進,注意不要新增任何其他站點! 例如,在下面第1條線路中,必須從A城開始,直接到達B城(距離為5),然後直接到達C城(距離為4)。
- 線路A-B-C的距離
- 線路A-D的距離
- 線路A-D-C的距離
- 線路A-E-B-C-D的距離
- 線路A-E-D的距離
- 從C點開始,在C點結束,沿途最多可以有3個站點,符合該要求的線路有幾條? 在下面給出的示例資料中,共有2條符合線路:C-D-C (2 站),C-E-B-C (3 站)
- 從A點開始,在C點結束,要求線路上必須有4個站點,符合該要求的線路有幾條? 在下面給出的示例資料中,共有3條符合線路:A 到 C (通過 B,C,D); A 到 C (經過 D,C,D); 以及 A 到 C (經過 D,E,B).
- A 到 C的最短路線長度
- B 到 B的最短路線長度
- 從C點開始,在C點結束,要求距離小於30,符合該要求的線路有幾條? 在下面給出的示例資料中,符合條件的線路有:CDC, CEBC, CEBCDC, CDCEBC, CDEBC, CEBCEBC, CEBCEBCEBC.
測試輸入:
在測試輸入中,城鎮名字由A、B、C、D代表。例如AB5表示從A到B,線路距離為5.
圖表: AB5, BC4, CD8, DC8, DE6, AD5, CE2, EB3, AE7
要求輸出:
Output #1: 9
Output #2: 5
Output #3: 13
Output #4: 22
Output #5: NO SUCH ROUTE
Output #6: 2
Output #7: 3
Output #8: 9
Output #9: 9
Output #10: 7
從題目可以看出,其實就是要實現一個最簡單的圖,並最終實現一個最短路徑的演算法。當然這個過程中,會涉及一些資料結構與演算法:堆(索引最小堆)、鄰接矩陣表示圖、圖的深度優先遍歷、有環圖的遍歷、Dijkastra最短路徑演算法(正權邊)。下面會一個個來說。
二、最小堆
首先我們圍繞這道題,從最最基礎的結構 — 堆,說起。以往,各種教學,都從大頂堆講,然後自己私下去拓展學小頂堆,這回我們直接從小頂堆,來入手。首先讓我們看看堆的定義(來源於維基百科):
堆(英語:Heap)是電腦科學中的一種特別的樹狀資料結構。若是滿足以下特性,即可稱為堆:“給定堆中任意節點 P 和 C,若 P 是 C 的母節點,那麼 P 的值會小於等於(或大於等於) C 的值”。若母節點的值恆小於等於子節點的值,此堆稱為最小堆(min heap);反之,若母節點的值恆大於等於子節點的值,此堆稱為最大堆(max heap)。在堆中最頂端的那一個節點,稱作根節點(root node),根節點本身沒有母節點(parent node)。
總結下:
- 樹狀結構
- 完全二叉(多叉)樹(除了葉子節點,其他節點必須所有孩子都有值)
- 任意父親節點大於(小於)或者等於孩子節點
- 大於:最大堆;小於:最小堆
下面是堆的基礎模型圖:

相應的,我們使用的儲存堆的資料結構,更多的使用一個數組,如下:
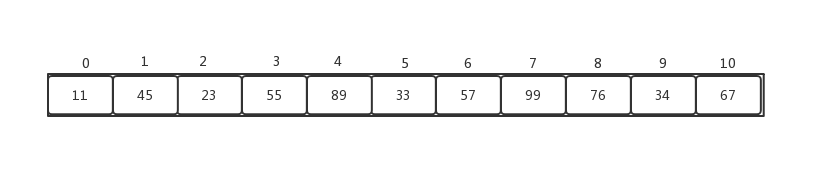
使用陣列具體的母子節點的換算公式是:
- 獲取當前節點的父親節點索引:parentNodeIndex = (currentNodeIndex-1)/2
- 獲取當前節點的孩子索引:
- 左孩子:leftNodeIndex = currentNodeIndex*2 + 1
- 右孩子:rightNodeIndex = currentNodeIndex*2 + 2
下面是我總結的大體上堆這種資料結構的優點:
- 快速的獲取最大(最小)值:O(1)複雜度
- 簡單、快速的底層儲存邏輯
- 堆排序(O(nlogn))
三、最小堆的核心實現(基於Java)
先給出基礎的骨架程式碼
public class MinPriorityQueue<K extends Comparable<K>> {
// 堆的基礎儲存資料結構
private Object[] elements;
// 當前堆中元素個數
private int size;
public MinPriorityQueue() {
this.elements = new Object[Common.INIT_SIZE];
this.size = 0;
}
private void checkLength(int index) {
if (index < 0 || index >= this.elements.length) {
throw new IllegalArgumentException("超出限制");
}
}
public int lchild(int index) {
checkLength(index);
return (index * 2) + 1;
}
public int rchild(int index) {
checkLength(index);
return (index * 2) + 2;
}
public int parent(int index) {
checkLength(index);
return (index - 1) / 2;
}
public void swap(int i, int j) {
checkLength(i);
checkLength(j);
K temp = (K) elements[i];
elements[i] = elements[j];
elements[j] = temp;
}
@Override
public String toString() {
return "MinPriorityQueue{" +
"elements=" + Arrays.toString(elements) +
", size=" + size +
'}';
}
}
有幾點:
- 內部儲存由於擦除原因,使用了Object
- 每個泛型引數型別都要是可比較型別(Comparable),因為要比較父子節點大小
- size表示當前堆中元素大小
- 當然,這裡可以直接使用Comparable型別的基礎陣列儲存
1、上浮操作與新增元素
上浮是保證整個堆保證原先資料規則的一種手段,主要用於新增元素的時候,每次新增元素,我們會直接放到內部基礎陣列最後一個索引位置,然後做上浮操作,下面我們隨便新增一個數字(9),然後看看整體上浮過程是如何變化的:
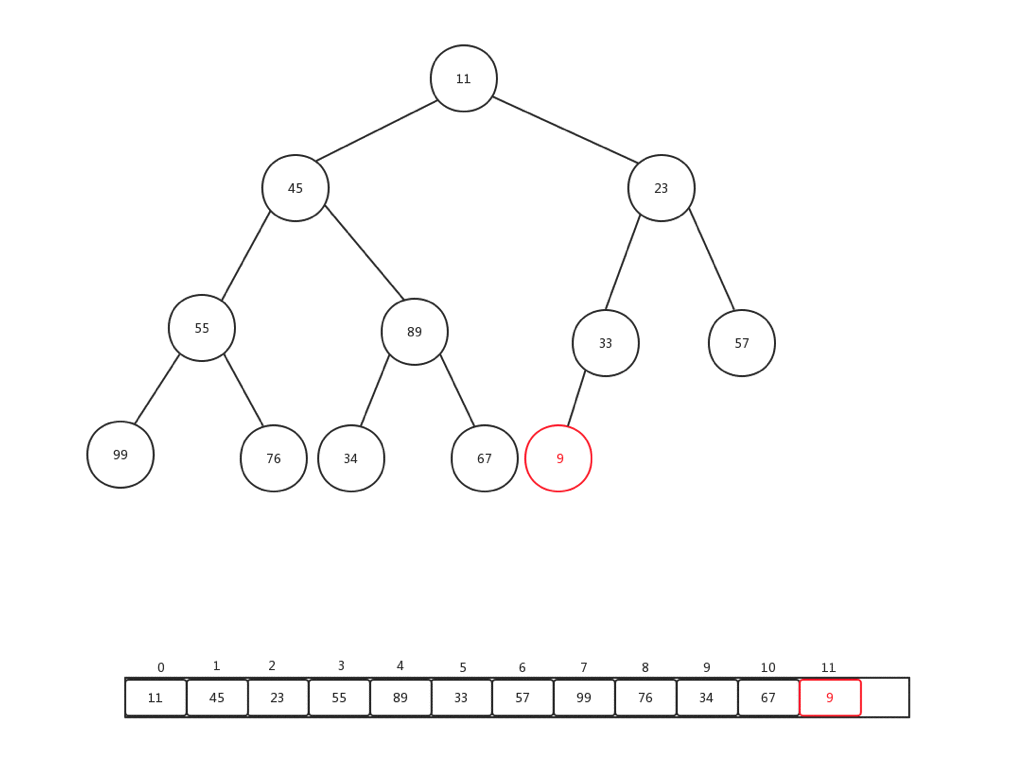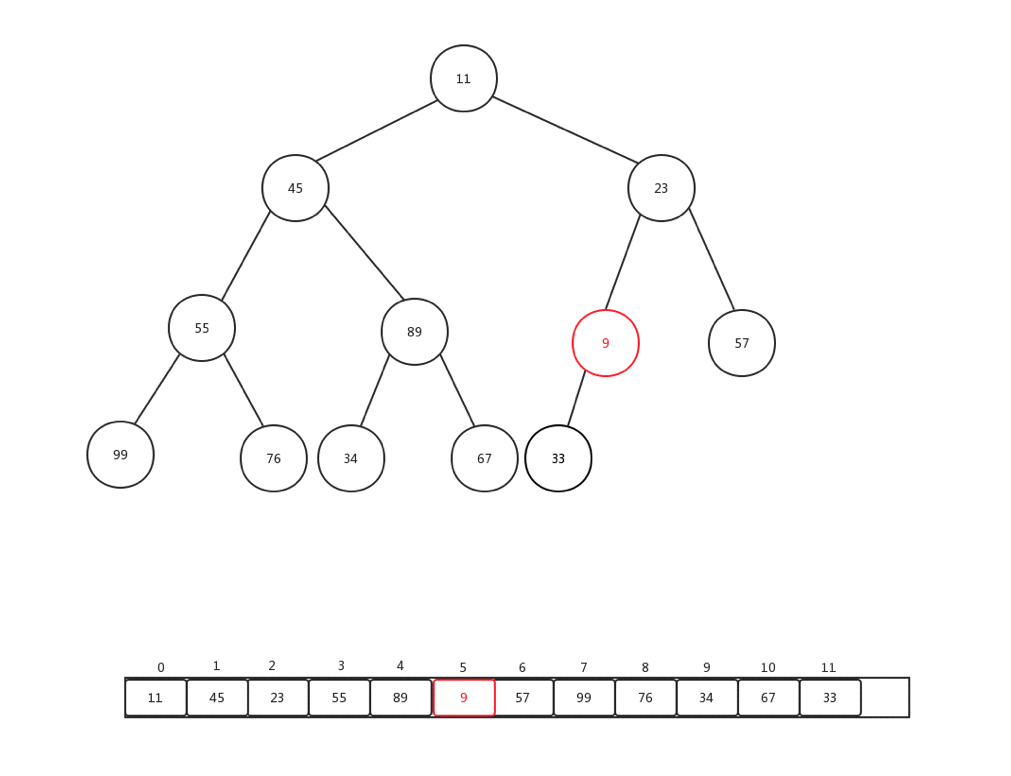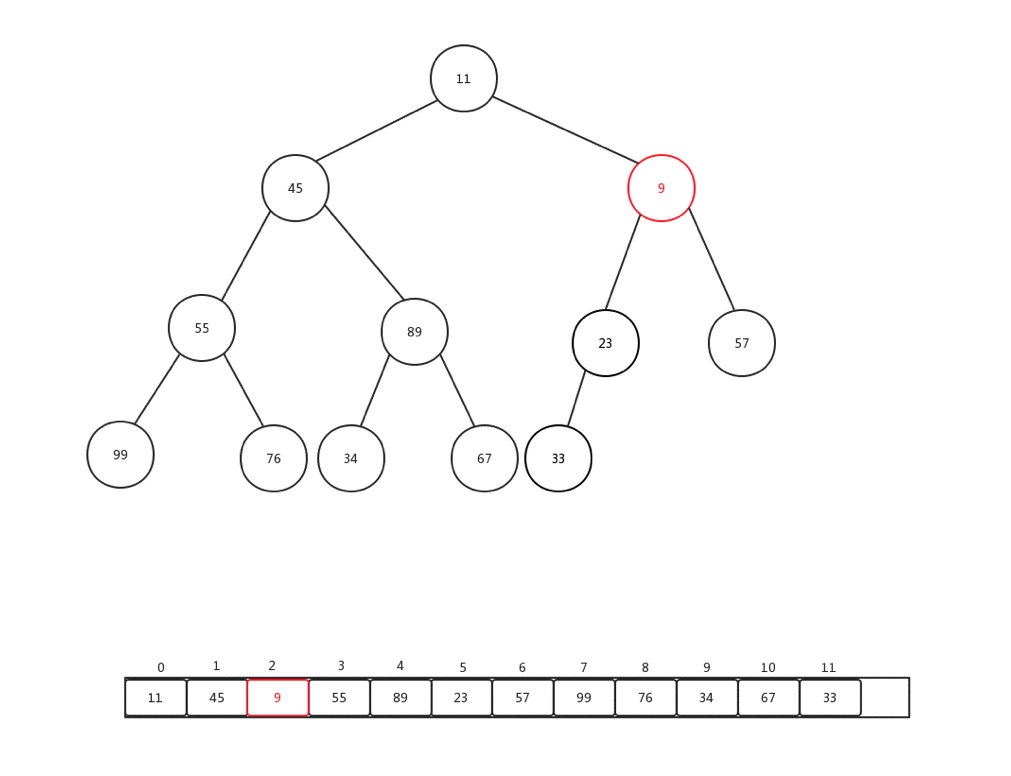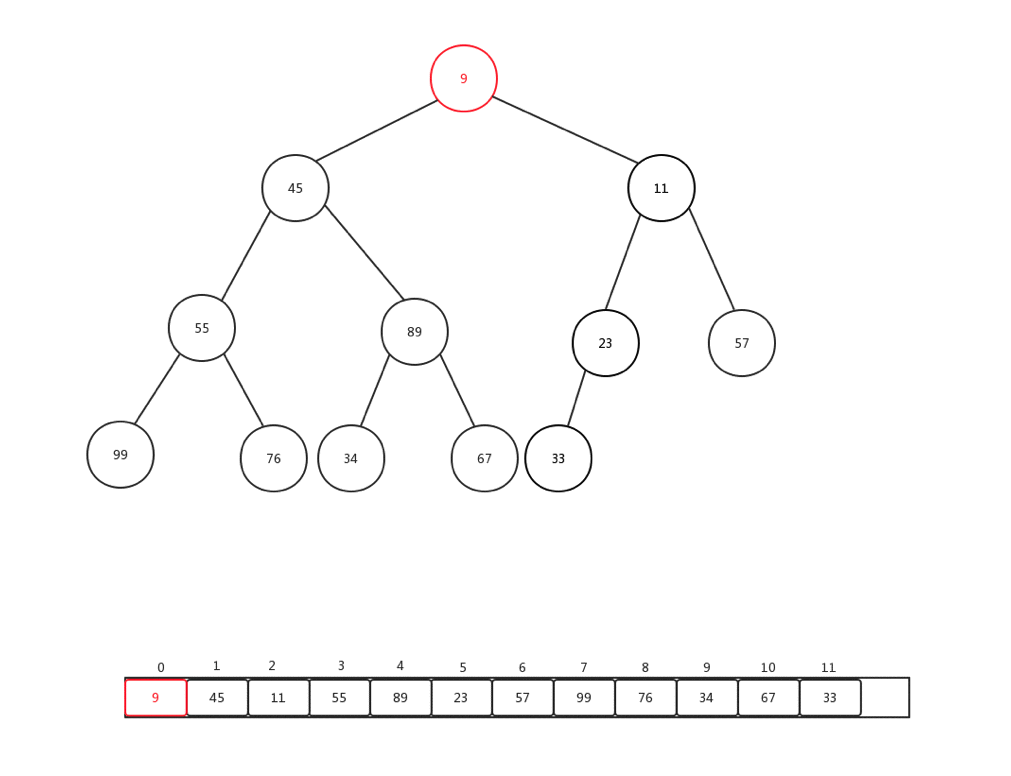
整個過程比較簡單,主要是當前節點和父親加點比較:
/**
* 上浮
*/
public void swam(int index) {
// 防止索引溢位
checkLength(index);
int p = index;
while (p > 0) {
K currentEle = (K) elements[p];
int parentIndex = parent(p);
// 核心,用於比對當前節點與父親節點的大小
if (currentEle.compareTo((K) elements[parentIndex]) < 0) {
// 交換當前索引與父親節點索引中的值
swap(p, parentIndex);
p = parentIndex;
} else {
// 一旦發現當前值大於父親節點,就停止迴圈
break;
}
}
}
有了上浮操作,那麼向堆中新增元素的程式碼也是比較簡單的了:
/**
* 新增元素
*/
public void addElement(K element) {
if (size == elements.length) {
// 新增堆的容量
resize();
}
elements[size] = element;
swam(size);
// 維護當前堆數量大小
size++;
}
/**
* 擴容
*/
public void resize() {
int length = elements.length;
Object[] tempArr = new Object[length + Common.GROW_SIZE];
System.arraycopy(elements, 0, tempArr, 0, length);
this.elements = tempArr;
}
2、下沉操作與刪除元素
相對比較來說,下沉會更加複雜一些,複雜點在於,每次都要進行當前節點與幾個孩子節點的比較操作,可是當前節點是否有孩子節點,還是要判斷的。總的來說,要花心思去保護索引溢位的情況。首先,讓我們看看刪除一個堆內元素是如何進行的:
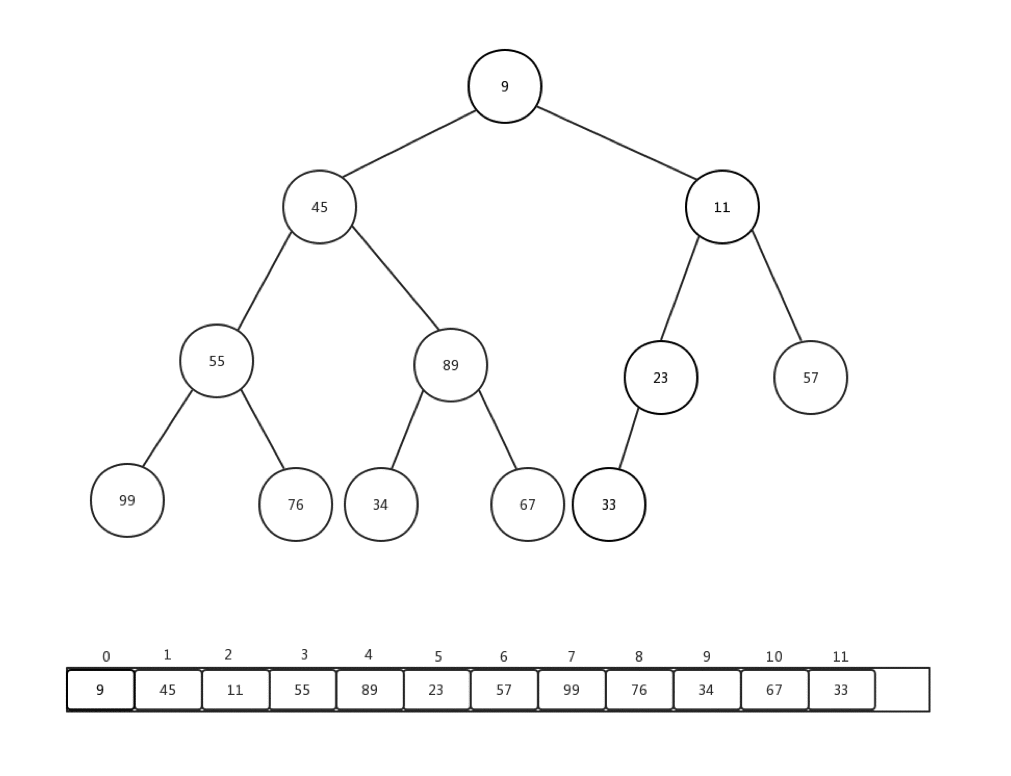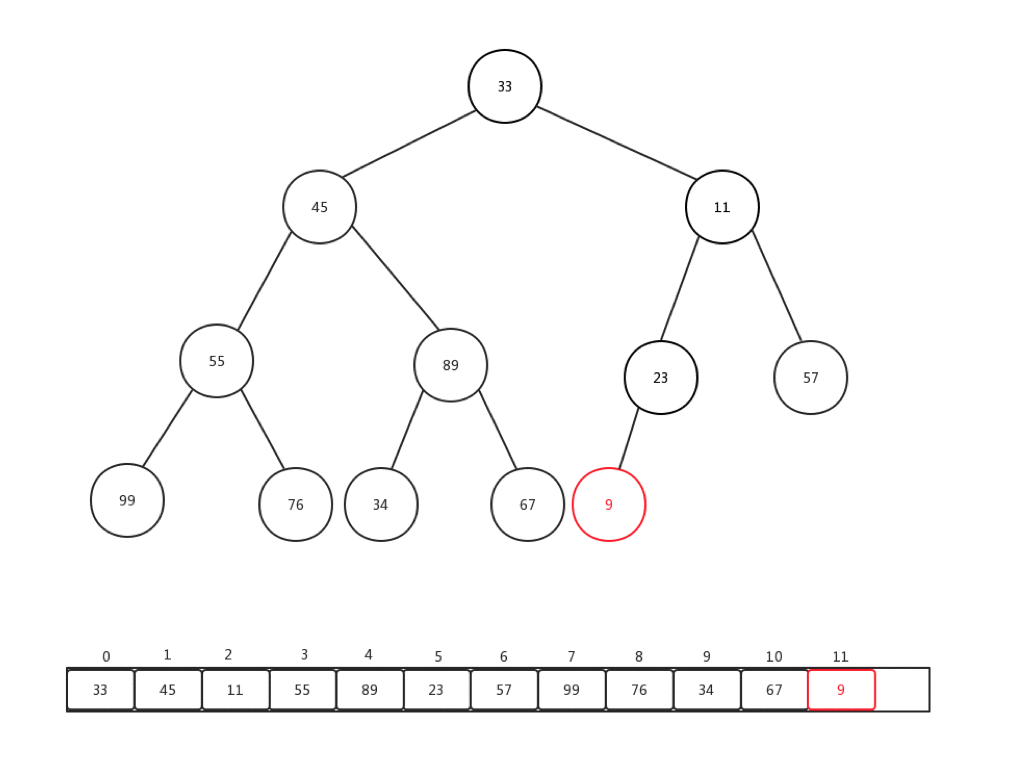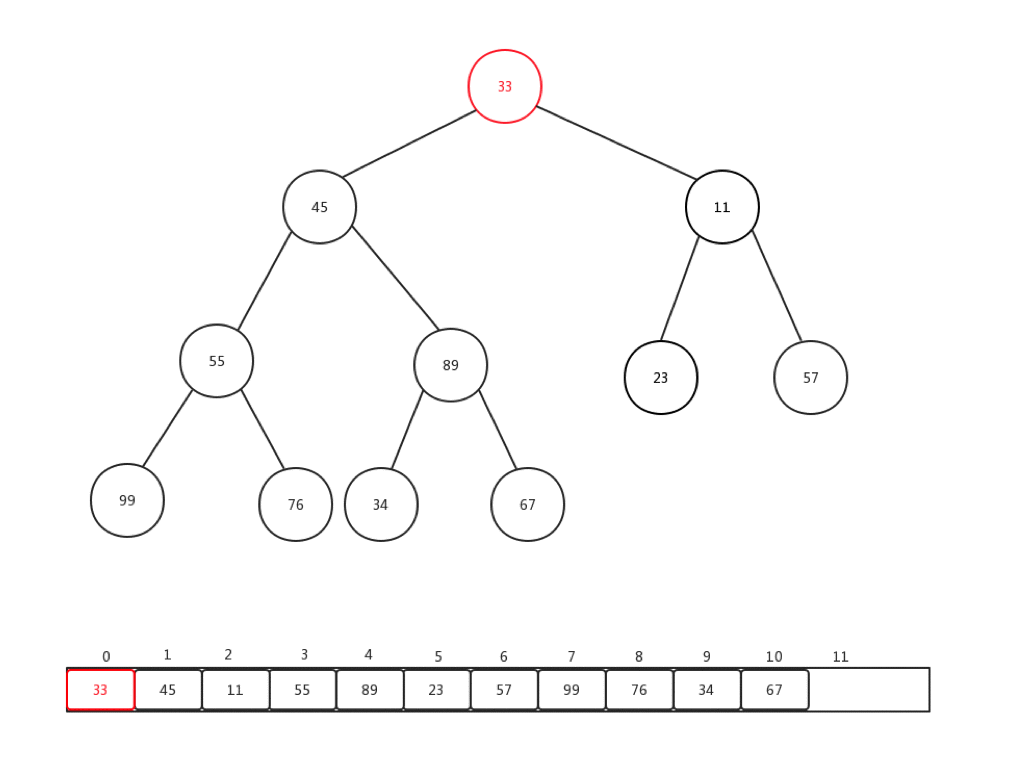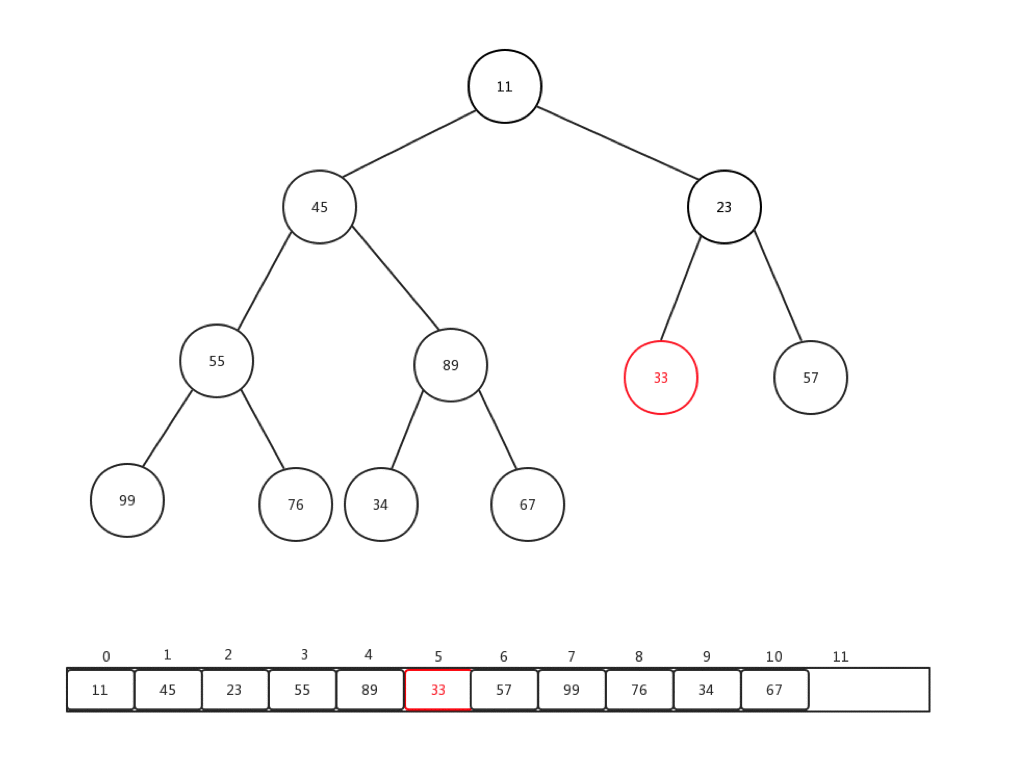
- 儲存堆頂元素的值
- 交換堆頂和最後的結點
- 刪除最後一個節點的值,指向null
- 對堆頂(索引為0)做下沉操作
下面是下沉操作的基礎程式碼:
/**
* 下沉
*/
public void sink(int index) {
checkLength(index);
int p = index;
/**
* 如果左孩子大於或者等於當前堆中元素個數的話,
* 表明當前節點已經是葉子節點,可以不用繼續遍歷了
*/
while (p < size && lchild(p) < size) {
K currentEle = (K) elements[p];
// 獲取左孩子索引
int lchild = lchild(p);
// 獲取右孩子索引
int rchild = rchild(p);
// 獲取左孩子的值
K lelement = (K) elements[lchild];
// 獲取右孩子的值
K relement = (K) elements[rchild];
// 核心,獲取左右孩子最小值的那個節點索引,注意,這裡右孩子有可能為空
int minChildIndex = Objects.isNull(relement) ? lchild :
(lelement.compareTo(relement) > 0 ? rchild : lchild);
// 使用當前節點值與最小值比較,如果當前值還要小,那就交換
if (currentEle.compareTo((K) elements[minChildIndex]) > 0) {
swap(p, minChildIndex);
p = minChildIndex;
} else {
break;
}
}
}
在這裡,主要對節點索引進行了詳盡的判斷與保護,接下來,就是刪除元素的方法程式碼:
/**
* 刪除堆頂元素
*/
public K delElemet() {
if(size == 0){
throw new IllegalArgumentException("當前堆已經空了");
}
K result = (K) elements[0];
if (size > 1) {
swap(0, size - 1);
elements[--size] = null;
sink(0);
} else {
size--;
}
return result;
}
3、調整陣列成為一個最小堆
通常情況下,我們接收到的是一整個陣列的值,然後需要我們整理,才能變成一個最小堆,這個過程我們稱它為:heapify。就是重新調整。讓我們來看下一組陣列Integer[] arr = {90,34,99,57,11,67,55,23,76,33,45}如何進行從新調整的:
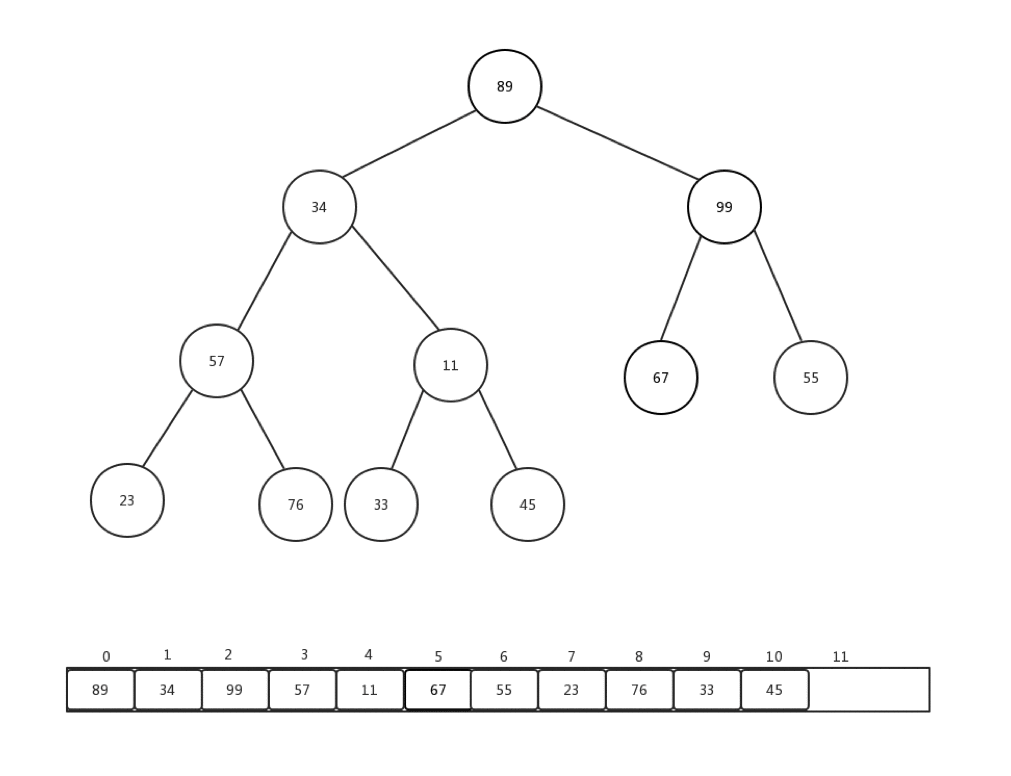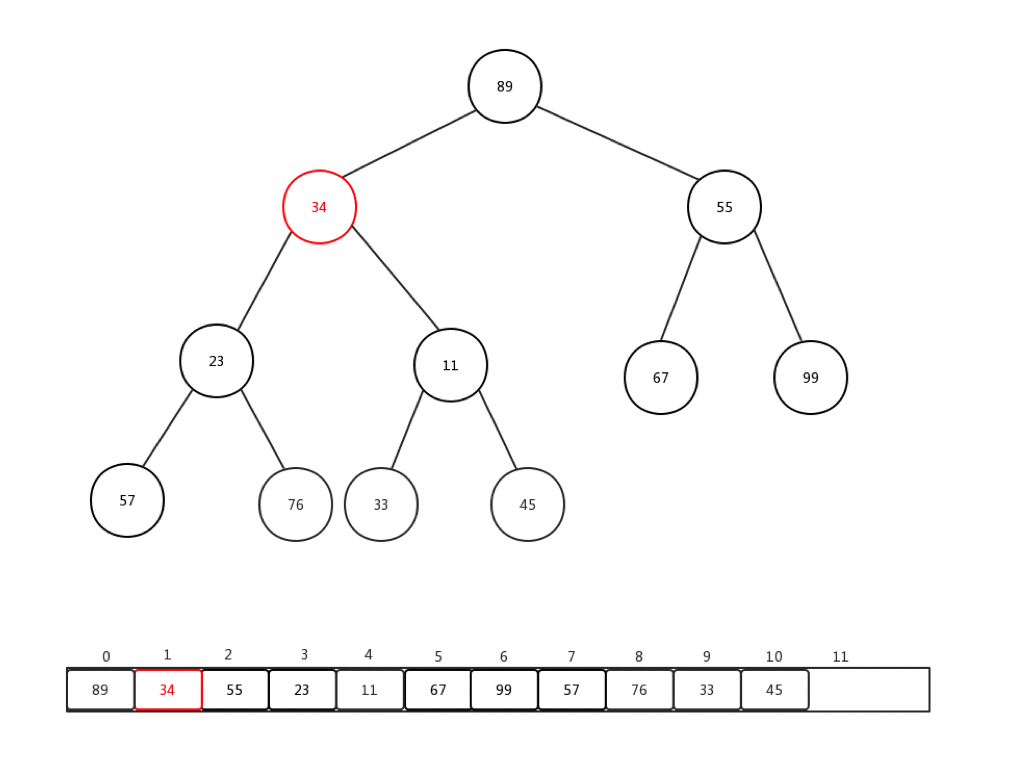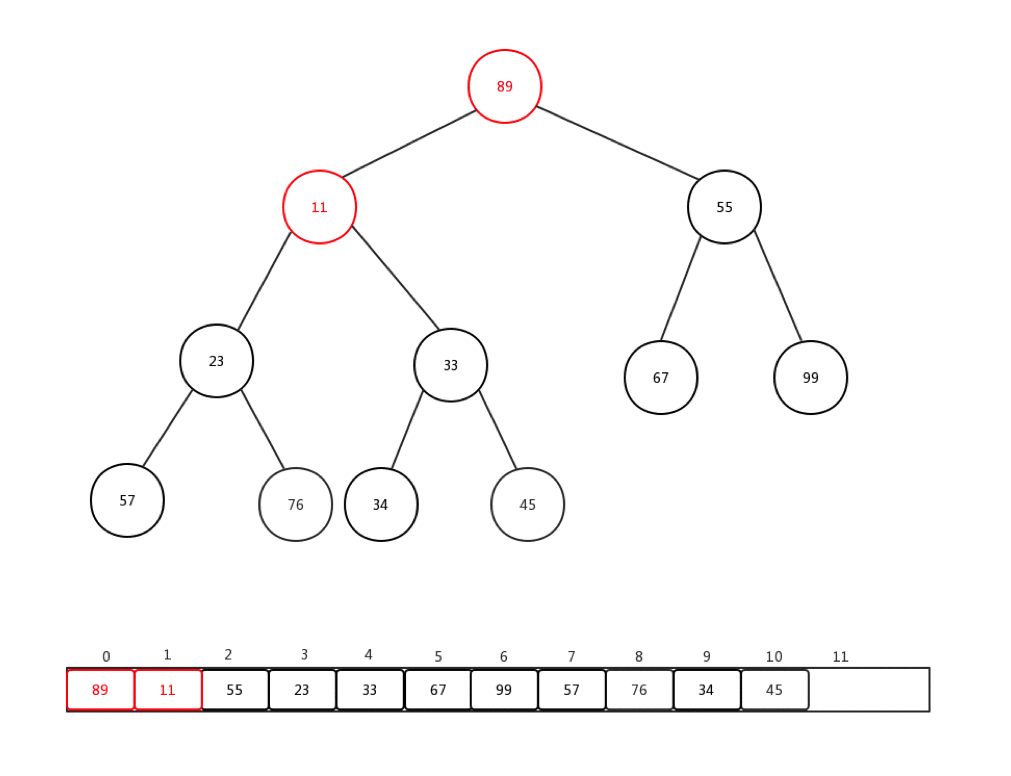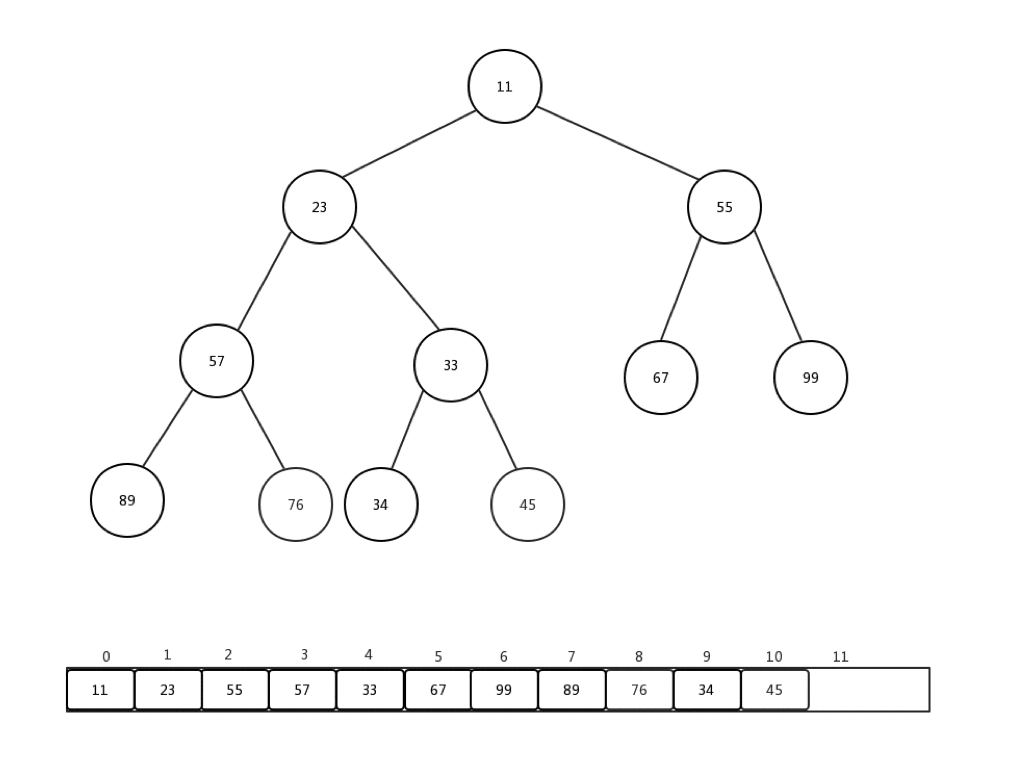
做一些介紹:
- 每次從第一個非葉子節點開始進行每個節點的下沉操作
- 第一個非葉子節點的索引 = (最後一個節點索引-1)/2
- 整體時間複雜度是:O(n)
下面就是基礎的程式碼實現:
// 每次傳入陣列的大小
public MinPriorityQueue(Comparable[] comps) {
if (Objects.isNull(comps) || comps.length == 0) {
throw new IllegalArgumentException("陣列不能為空");
}
this.elements = new Object[comps.length];
this.size = 0;
for (int i = 0; i < comps.length && comps[i] != null; i++) {
this.elements[i] = comps[i];
this.size++;
}
heapify();
}
private void heapify() {
if (this.size == 0) {
return;
}
int index = (this.size - 2) / 2;
for (int i = index; i >= 0; i--) {
// 下沉
sink(i);
}
}
到此,我們對於一個最小堆的全部實現,就完成了。下面開始介紹基於堆的一種拓展資料結構 — 索引最小堆
四、索引最小堆
經歷了最小堆的"洗禮",發現如下幾個問題:
- 每次交換都是使用原始元素進行交換
- 沒提供修改固定索引元素的方法
- 如果每個節點元素是一個複雜且龐大的值,那麼交換過程會導致很多問題(慢、記憶體溢位)
就此,索引堆概念出現了:
- 每個實際元素的陣列中的索引位置不變
- 另申請一個與堆同等大小的陣列,儲存每個元素在堆中實際位置
- 再來一個同等大小的陣列,反向索引具體堆中的位置(陣列索引 —> 堆上的索引)
(最後一點最不好理解,後面會有介紹)如此一來,每次元素新增到堆中,具體的元素就不會隨著上浮下沉而變換位置,真正變換的,是索引值(就是一個整型)。
1、索引最小堆演示
下面我根據上面最小堆,進一步擴充套件成索引最小堆,一步步演示,我們使用的原始陣列是:
Integer[] arr = {90,34,99,57,11,67,55,23,76,33,45}
(1)不加反向索引

可以看到全程沒有進行儲存元素的移動,全部是元素所對應的索引值進行移動,這樣一來,就能很好的解決上面元素複雜,移動緩慢的問題。
(2)加上反向索引
上面的索引堆還存在一個問題,就是,我更改堆中對應一個具體索引的元素值,之後,我並不知道這個值對應的具體在堆中的位置,例如:
- 改變索引4中元素11的值:data[4] = 12
- 我們想要確定11這個元素堆中的位置(其實是在索引陣列的第一個位置上,就是0上面)
- 然後根據這個位置,對這個位置前面的進行上浮操作,這個位置後面的進行下沉操作,這樣就能從新調整堆
這個時候,反向索引就有用了!我下面展現下最終加上反向索引的最終形式:

如果i表示具體索引值,recs表示反向索引陣列,indexes表示索引陣列,這幾個的關係是:
- recs[indexes[i]] = i
- indexes[recs[i]] = i
反向陣列不太好理解,可以多看看,多看看。其實就是一個儲存當前索引對應的資料,在堆中的位置,這個位置其實也是一個索引,只不過這個索引指向的是索引陣列
2、索引最小堆的基礎實現
首先是基礎框架的程式碼:
public class IndexMinPriorityQueue<K extends Comparable<K>> {
// 索引陣列
private int[] indexes;
// 原始資料的陣列
private Object[] elements;
// 反向索引陣列
private int[] recs;
// 當前堆元素的大小
private int size;
public IndexMinPriorityQueue() {
this.indexes = new int[Common.INIT_SIZE];
this.elements = new Object[Common.INIT_SIZE];
this.recs = new int[Common.INIT_SIZE];
this.size = 0;
for (int i = 0; i < Common.INIT_SIZE; i++) {
this.indexes[i] = -1;
this.recs[i] = -1;
}
}
public IndexMinPriorityQueue(int count) {
this.indexes = new int[count];
this.elements = new Object[count];
this.recs = new int[count];
this.size = 0;
for (int i = 0; i < count; i++) {
// 預設初始化時候,堆內沒有元素時候兩個索引陣列的每個欄位都初始化成-1
this.indexes[i] = -1;
this.recs[i] = -1;
}
}
}
加入了兩個輔助性質的陣列,我們來看看其他的一些修改點,首先是交換資料的方法:
public void swap(int i, int j) {
if (i < 0 || i >= size) {
throw new IllegalArgumentException("超出限制");
}
if (j < 0 || j >= size) {
throw new IllegalArgumentException("超出限制");
}
// 可以看到,每次只交換索引陣列中的值,真實資料陣列不變
int temp = indexes[i];
indexes[i] = indexes[j];
indexes[j] = temp;
// 反向索引陣列內部值的確認
recs[indexes[i]] = i;
recs[indexes[j]] = j;
}
相應的,上浮與下沉的方法也是要變動的:
/**
* 下沉
*/
public void sink(int index) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("超出限制");
}
int p = index;
while (p < size && lchild(p) < size) {
// 可以看到,每次取元素,都是要據具體的索引陣列的值來定位真實資料陣列的位置
K currentEle = (K) elements[indexes[p]];
int lchild = lchild(p);
int rchild = rchild(p);
K lelement = (K) elements[indexes[lchild]];
// 索引陣列的值為-1,表示當前元素被刪除或者就是沒存入
int minChildIndex = indexes[rchild] == -1 ? lchild :
(lelement.compareTo((K) elements[indexes[rchild]]) > 0
? rchild : lchild);
if (currentEle.compareTo((K) elements[indexes[minChildIndex]]) > 0) {
swap(p, minChildIndex);
p = minChildIndex;
} else {
break;
}
}
}
/**
* 上浮
*/
public void swam(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("超出限制");
}
int p = index;
while (p > 0) {
K currentEle = (K) elements[indexes[p]];
int parentIndex = parent(p);
K pelement = (K) elements[indexes[parentIndex]];
if (Objects.nonNull(pelement) && currentEle.compareTo(pelement) < 0) {
swap(p, parentIndex);
p = parentIndex;
} else {
break;
}
}
}
新增是對新增蒜素的修改:
/**
* 新增元素
*/
public void addElement(K element) {
if (size == elements.length) {
// 擴容
resize();
}
// 索引陣列的末尾新增這個元素的索引值
indexes[size] = size;
// 反向索引也是最後一位新增
recs[size] = size;
// 其實這也是最後一位新增,因為此時indexes[size] = size
elements[indexes[size]] = element;
// 先對最後一位的索引進行上浮操作,然後再將size加一
swam(size++);
}
/**
* 擴容
*/
public void resize() {
int length = elements.length;
Object[] tempArr = new Object[length + Common.GROW_SIZE];
int[] tempIndexes = new int[length + Common.GROW_SIZE];
int[] tempRecs = new int[length + Common.GROW_SIZE];
System.arraycopy(elements, 0, tempArr, 0, length);
System.arraycopy(indexes, 0, tempIndexes, 0, length);
System.arraycopy(recs, 0, tempRecs, 0, length);
for (int i = length; i < tempIndexes.length; i++) {
tempIndexes[i] = -1;
tempRecs[i] = -1;
}
this.elements = tempArr;
this.indexes = tempIndexes;
this.recs = tempRecs;
}
下面看看刪除一個堆頂元素的修改:
/**
* 刪除堆頂元素
*
* @return 堆頂的具體元素值
*/
public K delElemet() {
K result = (K) elements[indexes[0]];
delEl();
return result;
}
/**
* 刪除堆頂元素
*
* @return 堆頂的具體元素索引值
*/
public int delElemetIndex() {
int result = indexes[0];
delEl();
return result;
}
private void delEl() {
if (size > 1) {
// 這裡其實是交換索引陣列的第一位和最後一位的值
swap(0, size - 1);
}
// 此時要把末尾的索引值對應的元素置空,代表刪除原始資料
elements[indexes[--size]] = null;
// 當然,反向索引陣列的值也要刪除,置位-1
recs[indexes[size]] = -1;
// 當然,最後要把索引陣列值刪除,其實就是最後一位
indexes[size] = -1;
// 對索引陣列,就是第一位開始,做下沉
sink(0);
}
最後的最後,我們就可以看看如何修改一個堆中的元素了
public void change(int index, K element) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("超出限制");
}
this.elements[index] = element;
// 這時候,反向索引陣列就顯示作用了:獲取這個修改值對應的堆中的索引值
int currentHeapIndex = this.recs[index];
swam(currentHeapIndex);
sink(currentHeapIndex);
}
五、圖的基礎
好吧,到了圖這裡,已經深入到電腦科學領域了,我作為一個工程狗,真心無法,也沒有能力一箭到底!所以在此,我先上定義,然後我們擷取最簡單,切合具體的實際問題(這裡就是第一章那道題)來說相關的圖論的基礎結構與演算法,其他的,有關圖論的東西太多太多,有興趣可以自己深入研究。下面是wiki上面的一個定義:
圖有多種變體,包括簡單圖、多重圖、有向圖、無向圖等,但大體上有以下兩種定義方式。
二元組的定義
一張圖
是一個二元組
,其中
稱為頂點集,
稱為邊集。它們亦可寫成
和
。
表示,其中
。
三元組的定義
一張圖
,其中
稱為關聯函式,
。如果
那麼稱邊
連線頂點
,而
恩,說實話,我也看不懂,具體對於我們這次要解決的實際問題,相關的資料結構的知識點,提取出以下幾點:
- 我們要實現一個有向圖
- 而且是有向加權圖
- 會有環
- 邊用E(edge)來表示
- 節點用V(Vertices)來表示
- 我們這裡固定使用一種表示方法來進行圖的儲存:鄰接表
下面我們就開搞!
1、有向圖
我們來看看題目中,要我們實現的有向圖的基本輸入是:
AB5, BC4, CD8, DC8, DE6, AD5, CE2, EB3, AE7
根據此文字表述,我們畫出如下的示意圖:

有話說:不要在意邊的長短與權值大小的對應比例,只是一種展示、展示、展示!
接下來我們就用程式碼來實現相應的V(定點)與E(邊)
// 定點的抽象資料定義
public interface IVertices<V> {
// 獲取這個節點的值
V getData();
// 獲取當前節點的索引值
int getIndex();
}
// 邊的抽象資料定義
public interface IEdge<V> {
// 獲取一條邊起始頂點的物件
V getV1();
// 獲取一條邊結束頂點的物件
V getV2();
// 獲取一條邊的權值
int getWeight();
}
2、鄰接表儲存表示法
最常用的圖的表示法有兩種:鄰接矩陣、鄰接表。響應的適用場景如下:
- 鄰接矩陣:適用於稠密圖
- 鄰接表:適用於稀疏圖
一般來說,我們解決實際問題,都是稀疏圖,所以常用鄰居表,本次我們只看鄰接表的表示法,來儲存一個圖。下面是基本的鄰接表示意圖:
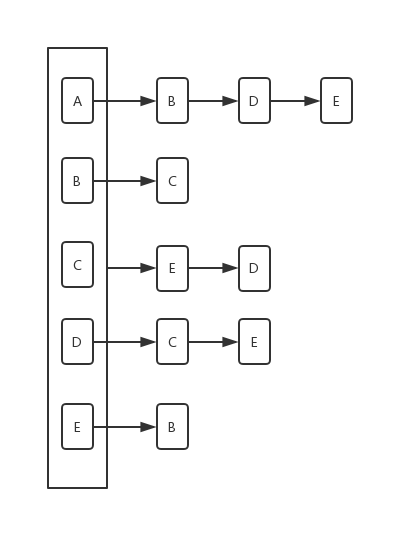
根據上面這個圖的展示,整個圖使用鄰接表儲存,會有下面的幾點:
- 一個圖物件儲存一個map
- key值是圖中的頂點
- value值是list,list中的每個值是以key值頂點為起始的邊
- 頂點物件要實現hashCode與equals方法,因為要當key
下面就是一個圖的基本程式碼實現,使用鄰接表的方式:
public class Graph<V extends IVertices, E extends IEdge<V>> {
// 當前圖中的結點數目
private int vsize;
// 當前圖中的邊的數目
private int esize;
// 鄰接表
private Map<V, List<E>> vectors;
public Graph() {
this.vsize = 0;
this.esize = 0;
this.vectors = new HashMap<>();
}
// 根據所有的結點來初始化
public Graph(V[] datas) {
if (Objects.isNull(datas) || datas.length == 0) {
throw new IllegalArgumentException("初始化失敗");
}
this.vsize = datas.length;
this.esize = 0;
this.vectors = new HashMap<>();
for (int i = 0; i < this.vsize; i++) {
this.vectors.put(datas[i], new LinkedList<>());
}
}
// 新增一條邊
public void addEdge(E w) {
List<E> ts = this.vectors.get(w.getV1());
if (ts == null) {
throw new IllegalArgumentException("這個節點不存在");
}
if (!ts.contains(w)) {
ts.add(w);
this.esize++;
}
}
// 獲取總節點數
public int getVsize() {
return vsize;
}
// 獲取總邊數
public int getEsize() {
return esize;
}
public Map<V, List<E>> getVectors() {
return vectors;
}
}
六、圖的遍歷(深度優先)
根據題目,我這裡介紹深度優先遍歷的整個過程與實現。當然還有廣度優先遍歷,會在後面的最短路徑上深入介紹。
1、題目節點遍歷展示
我們隨便找出一個小題:
從C點開始,在C點結束,沿途最多可以有3個站點,符合該要求的線路有幾條? 在下面給出的示例資料中,共有2條符合線路:C-D-C (2 站),C-E-B-C (3 站)
從上面的圖,我們來看下整體深度遍歷是如何進行的:
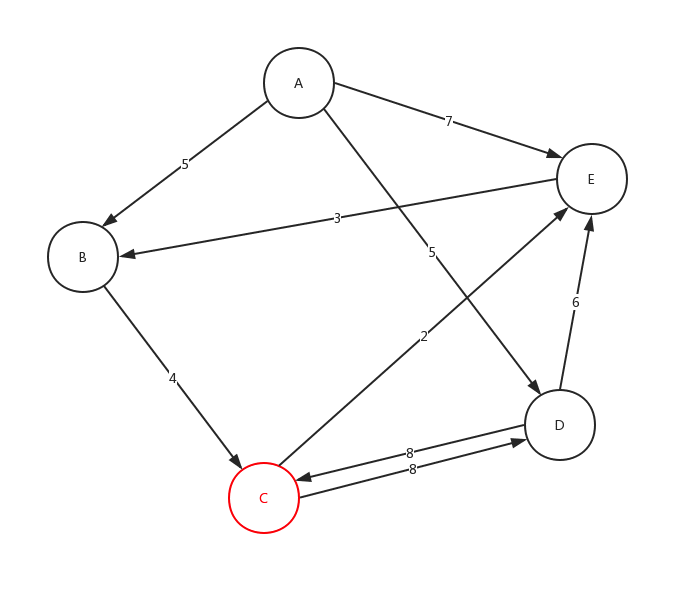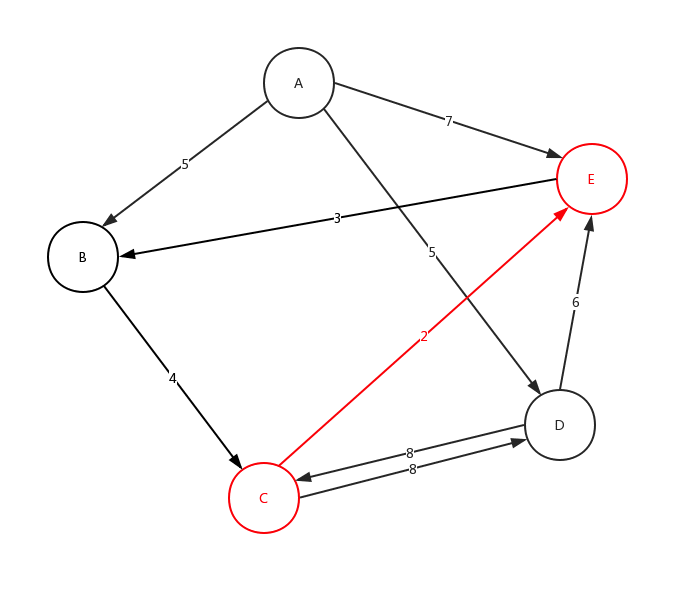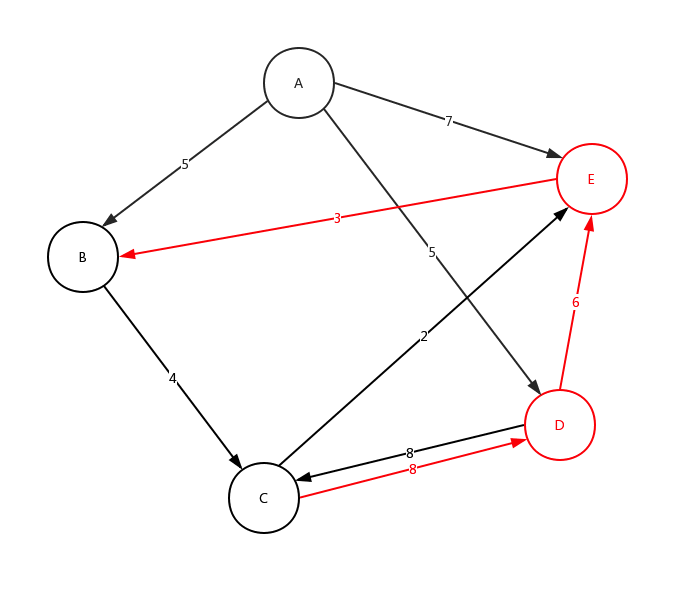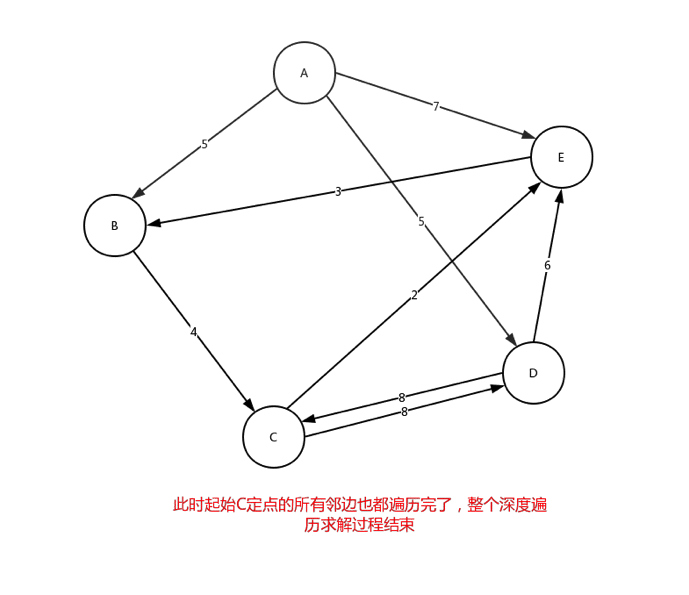
細心的看這個動態圖,很好的展示了,整個深度遍歷的求解過程。
2、程式碼實現
下面我就用程式碼來實現這一過程。相對來說,要實現這個過程並非那麼容易,因為要控制類似於:"最多","剛好","最多長度"等這些個區間求解。所以,要有響應的訪問計數值,來進行輔助。首先我們來看看深度遍歷圖的物件的基礎:
public class WordDepestPath {
// 要遍歷的圖
private Graph<WordVector, WordEdge> graph;
// 記錄當前邊被訪問到的次數
private Map<WordEdge, Integer> edgeVisitedCount;
// 記錄當前頂點被訪問到的次數
private Map<WordVector, Integer> verticesVisitedCount;
public WordDepestPath(Graph<WordVector, WordEdge> graph) {
this.graph = graph;
this.edgeVisitedCount = new HashMap<>();
this.verticesVisitedCount = new HashMap<>();
// 獲取圖的鄰接表
Map<WordVector, List<WordEdge>> vectors = graph.getVectors();
// 遍歷所有的邊,進行初始化
for (Map.Entry<WordVector, List<WordEdge>> entry : vectors.entrySet()) {
List<WordEdge> value = entry.getValue();
for (WordEdge it : value) {
// 起始狀態頂點和邊都沒有被訪問到一次
edgeVisitedCount.put(it, 0);
verticesVisitedCount.put(it.getV1(), 0);
}
}
}
}
這裡的WordVector、WordEdge分別是IVertices、IEdge的實現,主要頂點內包裝了個字串,例如:"A"。當然,因為要作為map的key值,必須要實現hashcode與equals方法,如下程式碼:
public class WordEdge implements IEdge<WordVector>, Comparable<WordEdge> {
private WordVector v1, v2;
private int weight;
public WordEdge() {
}
public WordEdge(WordVector v1, WordVector v2, int weight) {
this.v1 = v1;
this.v2 = v2;
this.weight = weight;
}
@Override
public WordVector getV1() {
return v1;
}
@Override
public WordVector getV2() {
return v2;
}
@Override
public int getWeight() {
return weight;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
WordEdge wordEdge = (WordEdge) o;
return weight == wordEdge.weight &&
Objects.equals(v1, wordEdge.v1) &&
Objects.equals(v2, wordEdge.v2);
}
@Override
public int hashCode() {
return Objects.hash(v1, v2, weight);
}
@Override
public String toString() {
return "WordEdge{" +
"v1=" + v1 +
", v2=" + v2 +
", weight=" + weight +
'}';
}
@Override
public int compareTo(WordEdge o) {
return this.weight - o.getWeight();
}
}
public class WordVector implements IVertices<String>, Comparable<WordVector>{
private int index;
private String word;
public WordVector() {
}
public WordVector(int index, String word) {
this.index = index;
this.word = word;
}
@Override
public int getIndex() {
return index;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
WordVector that = (WordVector) o;
return index == that.index &&
Objects.equals(word, that.word);
}
@Override
public int hashCode() {
return Objects.hash(index, word);
}
@Override
public String toString() {
return word;
}
@Override
public int compareTo(WordVector o) {
return this.getIndex() - o.getIndex();
}
@Override
public String getData() {
return this.word;
}
}
下面是深度遍歷的入口方法:
public List<List<WordEdge>> depestPath(WordVector src, WordVector dest) {
List<List<WordEdge>> result = new ArrayList<>();
Map<WordVector, List<WordEdge>> vectors = this.graph.getVectors();
List<WordEdge> wordEdgesSrc = vectors.get(src);
List<WordEdge> wordEdgesDest = vectors.get(dest);
if (wordEdgesSrc == null || wordEdgesDest == null) {
throw new IllegalArgumentException("沒有此次搜尋路徑的結點");
}
for (WordEdge edge : wordEdgesSrc) {
Stack<WordEdge> stack = new Stack<>();
stack.push(edge);
edgeVisitedCount.put(edge, edgeVisitedCount.get(edge) + 1);
depestPathLargest3(edge, dest, 1, stack, result);
edgeVisitedCount.put(stack.peek(), 0);
stack.pop();
}
return result;
}
最後是我們核心深度遞迴遍歷圖的方法:
/**
* 最多三站地的路徑求解方法
* 解決思路:
* 如果整個路徑上面最多隻允許有三個頂點(除開起始節點)
* 那麼就是說,如果是一個有環有向圖,那麼這個解的邊
* 最多隻能被訪問一次。如果多被訪問一次,那麼就會超出
* 三個頂點的題目要求,所以整個過程,重點要控制這個邊
* 的訪問次數
* @param currentEdge 當前遍歷到的邊
* @param dest 目標頂點
* @param largest 當前遍歷到的站點的數量
* @param stack 棧,用於輔助儲存遍歷節點
* @param result 結果集,儲存了所有符合條件的路徑
*/
private void depestPathLargest3(WordEdge currentEdge, WordVector dest, int largest,
Stack<WordEdge> stack, List<List<WordEdge>> result) {
// 遞迴終止條件
if (edgeVisitedCount.get(stack.peek()).intValue() >= 2) {
stack.pop();
return;
}
WordVector v2 = currentEdge.getV2();
// 注意這裡:如果到了目的頂點,但是不滿足最長路徑值,同樣不能成為結果
if (v2.getData().equals(dest.getData()) && largest <= 3) {
// 此分支,就是表示一條我們求解的路徑
ArrayList<WordEdge> rightPath = new ArrayList<>();
result.add(rightPath);
for (WordEdge it : stack) {
rightPath.add(it);
}
}
List<WordEdge> edges = this.graph.getVectors().get(v2);
// 這種情況表示下個頂點沒有臨邊,那就要棧頂的邊不可走,要出棧
if (edges.isEmpty()) {
stack.pop();
return;
}
// 對當前層遍歷到的邊的結束頂點,進行鄰接邊的遍歷
for (WordEdge it : edges) {
// 每每遍歷到了一個鄰接邊,要進行入棧+計數
stack.push(it);
edgeVisitedCount.put(it, edgeVisitedCount.get(it) + 1);
// 開始遞迴
depestPathLargest3(it, dest, largest + 1, stack, result);
}
/**
* 注意這裡,走到了這個地方,表示遍歷鄰邊已經結束,
* 每次彈出一個值的之前,要把這個鄰邊對應的訪問計數
* 清零,為了不影響後面的遞迴結束判斷
*/
edgeVisitedCount.put(stack.peek(), 0);
stack.pop();
}
根據這種思路,我們要求解下面兩個問題,也是依葫蘆畫瓢了:
- 從A點開始,在C點結束,要求線路上必須有4個站點,符合該要求的線路有幾條? 在下面給出的示例資料中,共有3條符合線路:A 到 C (通過 B,C,D); A 到 C (經過 D,C,D); 以及 A 到 C (經過 D,E,B).
- 從C點開始,在C點結束,要求距離小於30,符合該要求的線路有幾條? 在下面給出的示例資料中,符合條件的線路有:CDC, CEBC, CEBCDC, CDCEBC, CDEBC, CEBCEBC, CEBCEBCEBC.
七、圖的最短路徑問題
我們這裡求最短路徑,使用最經典的迪傑克斯拉演算法(Dijkstra),這個演算法,用來求單源最短路徑使用,有一定的限制:
- 所有邊的權值只能是正數,不能有負權邊
- 每次要使用索引堆進行輔助
下面我們一步步來講解下,如何求上面演算法題中的一小題,就是最短路徑的問題:
A 到 C的最短路線長度
1、迪傑克斯拉演算法展示
下面是動圖展示,然後我們一步步說如何求解:

一些前置條件:
- 索引堆中,索引值對應每個節點:1->A,2->B,3->C,4->D,5->E
- 索引堆中,具體的真實值儲存選取的單源節點到當前節點最短的路徑值:A->0,B->5,C->9,D->5,E->7
下面是具體的求解過程:
- 首先將原點加入到堆中,那原點對應的值是0
- 開始迴圈從堆中拿堆頂的資料,直到堆為空為止
- 每次拿到資料之後,遍歷拿到的節點的所有鄰邊
- 拿到每個鄰邊的另一端的結點,判斷這個節點是否被確定下來
- 如果沒有確定下來,那就看當前從此路徑過來的總路徑,是否比當前節點的路徑要短
- 如果短,則跟新當前節點的路徑值,如果不短,則跳過
- 當然,這個結點有可能還沒有統計過路徑長度,路徑為空,這種時候直接將節點,對應的路徑值,壓入索引堆中
- 如果當前節點已經是確定路徑的結點了,那就跳過當前節點與鄰邊的遍歷
- 注意:每次從堆頂拿到的,是最小的路徑值,那這個路徑對應另一端的節點就被確認下來,因為我們沒有考慮負權邊,所以不可能存在另外一個路徑,到這個節點還要短,所以每次堆頂拿到的值,必須要被標記成已確定
- 如此遍歷,直到堆為空的情況結束
這就是全過程,下面我們來看看程式碼實現
2、迪傑克斯拉演算法的程式碼實現
public class Dijsktra {
// 我們要求解的原圖(鄰接表儲存)
private Graph<WordVector, WordEdge> graph;
// 索引小頂堆
private IndexMinPriorityQueue<Integer> queue;
// 儲存每個節點是否被確認下來的對映,預設是false
private Map<WordVector, Boolean> isMarked;
// 儲存源節點到每個節點的最小路徑值
private Number[] distTo;
// 儲存每個節點的最短路徑是從那個鄰邊到達的
private WordEdge[] from;
public Number[] getDistTo() {
return distTo;
}
public Dijsktra(Graph<WordVector, WordEdge> graph, WordVector src) {
this.graph = graph;
this.queue = new IndexMinPriorityQueue<>(graph.getVsize());
this.isMarked = new HashMap<>();
distTo = new Number[graph.getVsize()];
from = new WordEdge[graph.getVsize()];
// 預設將每個節點的確認對映,設定成false,就是都是未確認狀態
for (Map.Entry<WordVector, List<WordEdge>> entry : graph.getVectors().entrySet()) {
WordVector key = entry.getKey();
isMarked.put(key, false);
}
// 初始化最短路徑儲存陣列,與最短路徑的鄰邊陣列
for (int i = 0; i < graph.getVsize(); i++) {
distTo[i] = 0.0;
from[i] = null;
}
// 第一個將源節點加入到結構中
from[src.getIndex()] = new WordEdge(src, src, 0);
// 注意,加入的索引值與對應的結點,還有值是路徑的長度
this.queue.insert(src.getIndex(), from[src.getIndex()].getWeight());
this.isMarked.put(src, true);
// 開始遍歷索引堆
while (!this.queue.isEmpty()) {
// 獲取堆頂的元素索引
Integer nodeIndex = this.queue.delElemetIndex();
// 通過索引值與鄰邊陣列,獲取對應的當前遍歷的堆頂定點
WordVector v2 = from[nodeIndex].getV2();
// 當前節點就是最短路徑了,所以標記已被確認
this.isMarked.put(v2, true);
// 開始遍歷當前節點的所有鄰邊
List<WordEdge> edges = this.graph.getVectors().get(v2);
for (WordEdge it : edges) {
// 查詢鄰邊另一邊的結點,看看路徑情況
WordVector nextNode = it.getV2();
if (!this.isMarked.get(nextNode)) {
int nextNodeIndex = nextNode.getIndex();
/**
* 核心:首先的if邏輯判斷很關鍵,
* 看看當前節點索引對應的路徑值有沒有開始統計,
* 並且如果開始統計有值的話,就計算從當前鄰邊到
* 達當前節點的路徑長度,是否小於已經存在的路徑
* 如果小,就要更新,不小就略過。
*/
if (from[nextNodeIndex] == null
|| distTo[v2.getIndex()].intValue()
+ it.getWeight() < distTo[nextNodeIndex].intValue()) {
// 內部,表示要更新當前節點的最短路徑,那就要改各個陣列與索引堆中的值
distTo[nextNodeIndex] = distTo[v2.getIndex()].intValue()
+ it.getWeight();
from[nextNodeIndex] = it;
// 索引堆也有兩種情況,有這個值,沒這值
if (queue.contain(nextNodeIndex))
queue.change(nextNodeIndex, distTo[nextNodeIndex].intValue());
else
queue.insert(nextNodeIndex, distTo[nextNodeIndex].intValue());
}
}
}
}
}
}
如此,其實已經解決了我們題