
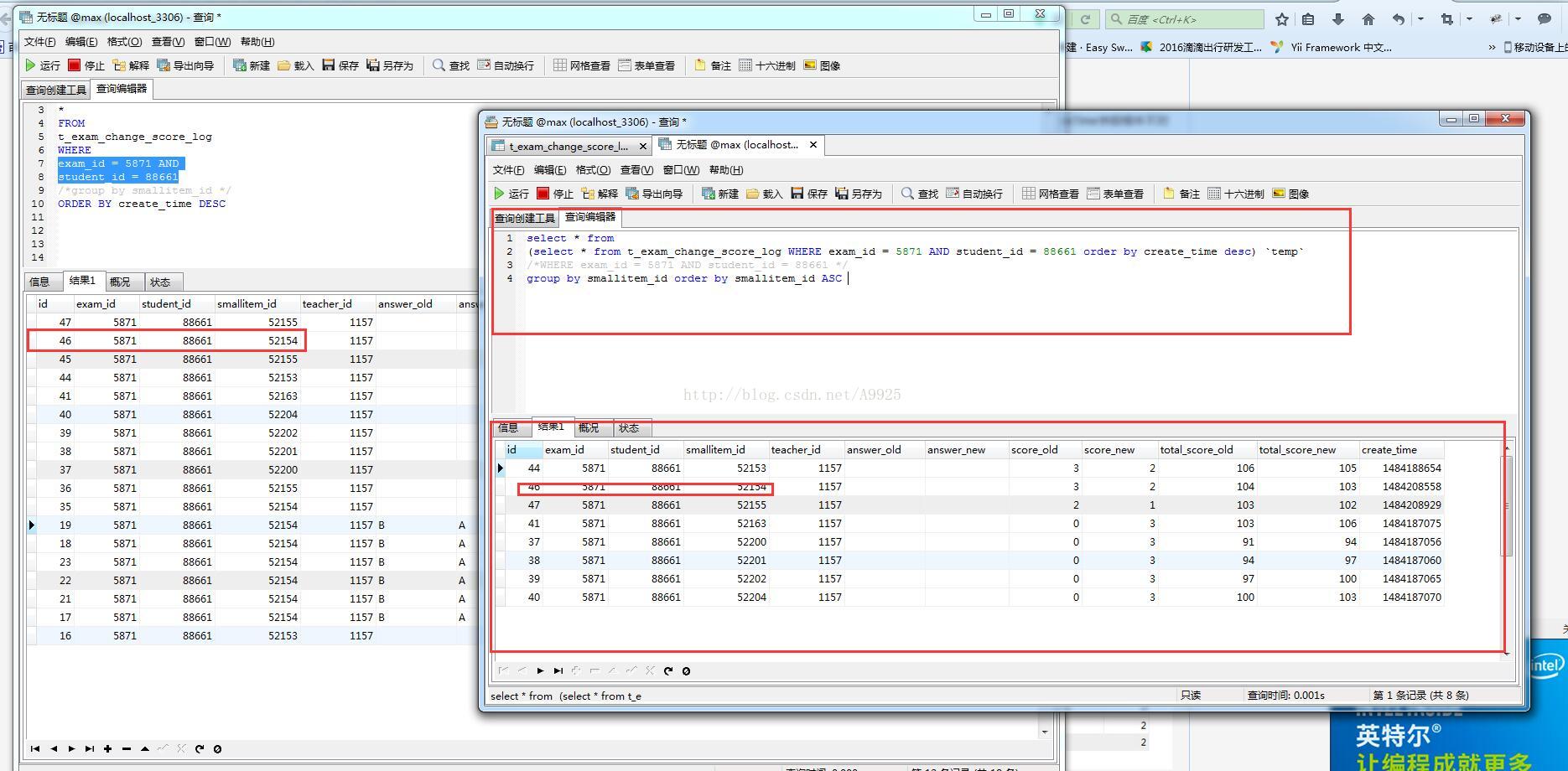
多資料分組重複取時間大的一條
思路
先降序,把大的時間排上去, 再分組,取出來的自然是最大的第一條
根據 考試id exam_id 和學生id 查出來的集合 (裡邊有smallitem_id 是重複的 )
select * from (select distinct cretate_time from t_exam_change_score_log order by cretate_time desc) f group by smalitem_id
相關推薦
多資料分組重複取時間大的一條
思路 先降序,把大的時間排上去, 再分組,取出來的自然是最大的第一條 根據 考試id exam_id 和學生id 查出來的集合 (裡邊有smallitem_id 是重複的 ) 重複的 我取 create_time 最大的那個記錄 select * from (s
mysql刪除重複資料只保留id最大一條記錄
一:首先是這麼想的 DELETE FROM t_4g_phone WHERE id NOT IN ( SELECT max(b.id) AS id FROM
mysql使用GROUP BY分組實現取前N條記錄的方法
cls class ges rom 當前 分組 實現 一個 images MySQL中GROUP BY分組取前N條記錄實現 mysql分組,取記錄 GROUP BY之後如何取每組的前兩位下面我來講述mysql中GROUP BY分組取前N條記錄實現方法。 這是測試表(也
mysql或者oracle分組排序取前幾條數據
esc rom group over nbsp oracle oracl 排序 _id mysql: select a.* from(select t1.*,(select count(*)+1 from 表 where 分組字段=t1.分組字段 and 排序字段<t
查詢資料分組之後的前幾條資料 可根據不同情況篩選
需求 : 1)獲取每個企業新發布的4個產品 2)VIP企業獲取8個產品 簡單的demo 這是所有的資料 SELECT product_name, company_id, add_time, vip, rn FROM
mysql 分組排序 取第N條全部記錄 同時存在條件篩選
1.首先利用條件篩選出基本資料SELECT * from test where columna = 'xxx' AND columnb = 'xxx' and ......2.對基本資料分組並利用SUB
parttion by ~~~針對某個欄位或多個欄位重複,資料只取前n條。問題例子:1.主評論下的評論按著 時間正序最多隻取前5條 2.獲取最新登入記錄......
分組目前已知partition by、group by partition by用於給結果集分組分割槽,如果沒有指定那麼它把整個結果集作為一個分組,最後顯示具體資料 group by:通過所查詢的資料的某一欄位或屬性進行分組,最後顯示組資料,而不是具體資料,因為select 後面的所有列中,沒有使用聚合函
Oracle去除重複(某一列的值重複),取最新(日期欄位最新)的一條資料
解決思路:用Oracle的row_number() over函式來解決該問題。 解決過程: 1.查看錶中的重複記錄 select t.id, t.device_id, &nb
SQL 聯合主鍵跨表刪除最小時間那條重複資料,跨表 for UPdate
一、過濾出需要刪除的重複資料的ID select aac001 from ei_app_recheck_citi_id inner join std_app on std_app.app_id=ei_app_recheck_citi_id.app_id where s
C# linq 多項分組 ,每一組根據條件(時間等)返回資料
var linq = from a in entities.Table group a by new { a.Column1, a.Column2} into temp let time= .Max(a => a.Column3)
oracle-查詢資料,其中指定欄位重複的只取其中一條
今天學了一句sql和大家分享一下: oracle資料庫,情景:表(客戶-業務員)中資料都不完全重複,但是可能多條資料其中某些欄位重複。我想要取得表中符合條件的記錄,但是這些記錄中的客戶id和客戶名稱發生重複的話只能留一個。 如上圖我想找出“馮冬梅”負責的
多條相同資料中,選根據選擇最近時間一條記錄
表結構(table):game_id name score coure time 1 AA 30 Java 2017-04-01
Oracle相同ID有多條記錄,取時間最近的一條
select * from (select t.*, row_number() over(partition by t.strcasei
獲取分組後取某欄位最大一條記錄(求每個類別中最大的值的列表)
獲取分組後取某欄位最大一條記錄 方法一:(效率最高) select a.* from test a, (select type,max(typeindex) typeindex from test group by type) b where a.
EF 分組取最後一條的實例
dev rep pat pan bsp div pos logs spa var qGroup = from dispatch in _dispatchRepository.GetAll() group dispatch
Python爬取數萬條北京租房資料,從6個維度揭穿房租瘋漲的祕密!!!
導讀:昨天還幻想海邊別墅的年輕人,今天可能開始對房租絕望了。 8月初,有網友在“水木論壇”發帖控訴長租公寓加價搶房引起關注。據說,一名業主打算出租自己位於天通苑的三居室,預期租金7500元/月,結果被二方中介互相擡價,
【原始碼追蹤】SparkStreaming 中用 Direct 方式每次從 Kafka 拉取多少條資料(offset取值範圍)
我們知道 SparkStreaming 用 Direct 的方式拉取 Kafka 資料時,是根據 kafka 中的 fromOffsets 和 untilOffsets 來進行獲取資料的,而 fromOffsets 一般都是需要我們自己管理的,而每批次的 untilOffsets 是由
Oracle刪除重複資料並且只留其中一條資料
資料庫操作中,經常會因為導資料造成資料重複,需要進行資料清理,去掉冗餘的資料,只保留正確的資料 一:重複資料根據單個欄位進行判斷 1、首先,查詢表中多餘的資料,由關鍵欄位(name)來查詢。 select * from table_name where name in (sel
分組查詢取最大時間記錄的方法Oracle
sql語句: [sql] create table dispatch_result ( dr_id &n
實際開發中,獲得到的list為重複的最後一條資料問題解決
在開發中迴圈把物件中的值賦給list,最後取得list進行返回。老是會出現獲得的list是重複的值,並且值為最後一個物件。 這就是開發中沒有宣告好物件和list的位置。都應該在外面宣告list和物件。 注意:物件要在迴圈裡重新初始化一次,否則最後一個數據會把前面的資料全部覆蓋掉。注意第9