
【TensorFlow】第三課 卷積神經網路與影象應用
一,Image classification popeline
一般來說想要使用純程式設計的方式來讓機器識別一張圖片中的東西是非常困難的,常用的方法就是使用一些運算元來獲取影象中的很多的特徵,然後使用分類演算法如SVM等進行分類,這樣的話需要識別率不高。目前比較流行的方法是用資料驅動的方法來識別圖片中的物體。比如使用卷積神經網路的方式來識別,通過向網路輸入若干同類型的圖片來讓模型最終能識別出該類圖片。
一般的步驟有:a,收集資料; b,用神經網路來訓練;c,測試
二,資料集
常用的公共開放資料集有:
a,CIFAR-10:
10 classes, 50,000 training images, 10,000 test images, 32x32x3 images
https://www.cs.toronto.edu/~kriz/cifar.html
b,CIFAR-100:
100 classes, 50,000 training images, 10,000 test images, 32x32x3 images
https://www.cs.toronto.edu/~kriz/cifar.html
有20個大類,每個大類下面有5個小類。
c,MNIST:
10 classes, 60,000 training images, 10,000 test images, 28x28 images
http://yann.lecun.com/exdb/mnist/
d,SVHN:
10 classes, 73,257 training images, 26,032 test images, 32x32x3 images
http://ufldl.stanford.edu/housenumbers/
老吳實驗室搞出來的資料集,主要是含有門牌號的照片。一張圖片上可能有多個圖片。
e,Caltech 101:
101 classes, ~5,050 images in total, 300x200x3 images
http://www.vision.caltech.edu/Image_Datasets/Caltech101/
f,Imagenet:
1000 classes, ~1.4M images in total, normalized to 256x256x3 images
http://www.image-net.org/
ImageNet比賽,很有名。
前五種資料集的規模不大,一般作為學術研究使用。只有最後一個數據集Imagenet是工業界常用的。
三,卷積神經網路
卷積的主要步驟的卷積(convolutional)和降取樣(pooling)
卷積的目的其實是求影象中與自己相似的地方,在數學層面上卷積是對矩陣做內積。卷積------->內積------->相似度
a,一張彩色影象的3通道的,比如:128*128*3,在與一張同樣是是3通道的卷積核發生卷積之後,就成為一個單通道的矩陣了;而當我們設定多個卷積核的時候就會得到多個矩陣,可以將這些矩陣組合在一起當做多通道的結果輸出。那麼有多少卷積核就有多少個通道。
b,在做完卷積核之後,通常要對得到的矩陣做非線性變換,也就是使用一個啟用函式得到非線性的結果作為輸出結果。
c,pooling層不是必須的,不一定要一層卷積之後跟一層降取樣
四,ImageNet比賽上奪冠的CNN模型
12年AlexNet:

14年VGGNet

15GoogLeNet

與其他CNN的不同之處:

16ResNet:

有一個很神奇的Resident block技術
五,一些補充
1,啟用函式:
目前比較常用的啟用函式是Relu,它的公式是:f(x)=max(x),它的圖如下所示:

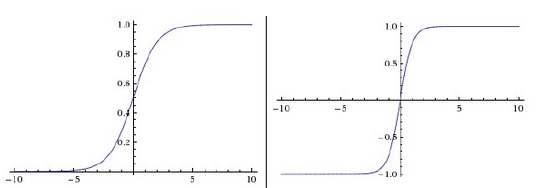
其他常用的啟用函式有:sigmoid和tanh:


它們的顯示圖,如下所示:
2,用來防止網路過擬合的dropout
Dropout Learning是訓練深度學習網路訓練引數的一種方法,它可以避免過擬合併且可以有效結合指數個數(2n,n表示神經元的個數)的網路結構。Dropout就是在訓練網路時隨機的捨棄掉隱層和可視層的一些神經元,其輸入及輸出連線也相應的去掉。最簡單的情況便是獨立的以概率P來選擇一個神經元,P=0.5會使訓練達到最優。但對於輸入層P=1時最優。網路各層都使用權值共享。每次訓練時都會隨機的選擇一些神經元來組成一個“變瘦”的網路,下次訓練時會重新選擇神經元組成新的網路,但權重會使用上次訓練好的值,一直這樣繼續下去,直到滿足誤差或達到一定的迭代次數。(有n個神經元,每個神經元都有可能被選擇到,所以共有Cn0+ Cn1 +Cn2+…+ Cnn=2n個,可以結合下圖理解)而在測試階段不捨棄神經元,只是將訓練網路的神經元權重乘以P,使其達到與訓練時輸出相同的效果。示意圖如下:
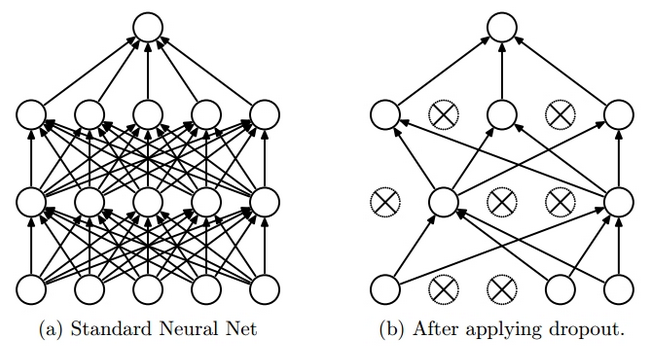
圖1的左圖表示網路的正常架構,右圖表示使用Dropout Learning後的網路結構,有連結的神經元表示被選中的神經元,打差號的為未被選中的神經元。這樣無論前向傳播還是後向傳播,都只使用被選擇到的神經元。
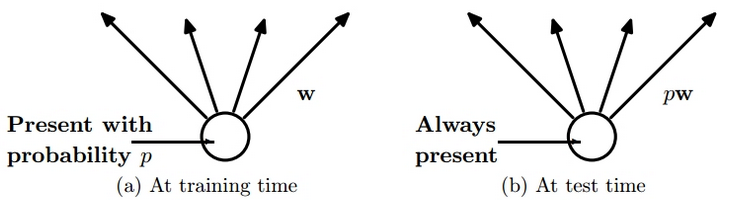
圖2左圖表示訓練時,該神經元以概率P被選到,值在其上傳播時使用的權值為W。右圖表示測試時,這時不捨棄任何神經元,而是將所有神經元的的權重乘以其被選擇的概率P,這樣可以使在測試時神經元的輸出與在訓練時神經元的輸出相同。
六,參考文章