
機器學習筆記(十四):TensorFlow實戰六(經典卷積神經網路:AlexNet )
1 - 引言
2012年,Imagenet比賽冠軍的model——Alexnet [2](以第一作者alex命名)。這個網路算是一個具有突破性意義的模型
首先它證明了CNN在複雜模型下的有效性,然後GPU實現使得訓練在可接受的時間範圍內得到結果,讓之後的網路模型構建變得更加複雜,並且通過GPU加速越來越得到關注
論文原文:http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
神經網路整體結構如下圖所示:
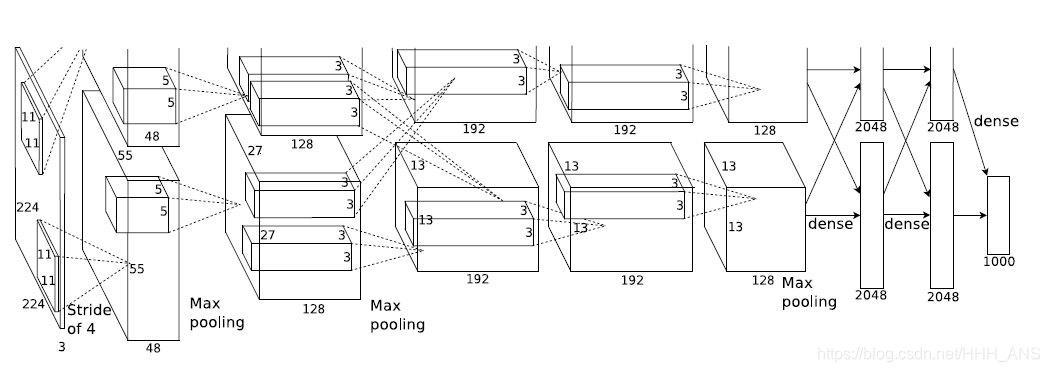
Alexnet 模型的創新之處:
-
ReLU
一般神經元的啟用函式會選擇sigmoid函式或者tanh函式,然而Alex發現在訓練時間的梯度衰減方面,這些非線性飽和函式要比非線性非飽和函式慢很多。在AlexNet中用的非線性非飽和函式是f=max(0,x),即ReLU。實驗結果表明,要將深度網路訓練至training error rate達到25%的話,ReLU只需5個epochs的迭代,但tanh單元需要35個epochs的迭代,用ReLU比tanh快6倍。 -
雙GPU加速
為提高執行速度和提高網路執行規模,作者採用雙GPU的設計模式。並且規定GPU只能在特定的層進行通訊交流。其實就是每一個GPU負責一半的運算處理。作者的實驗資料表示,two-GPU方案會比只用one-GPU跑半個上面大小網路的方案,在準確度上提高了1.7%的top-1和1.2%的top-5。值得注意的是,雖然one-GPU網路規模只有two-GPU的一半,但其實這兩個網路其實並非等價的。 -
LRN區域性響應歸一化
ReLU本來是不需要對輸入進行標準化,但本文發現進行區域性標準化能提高效能。
這種響應歸一化實現了一種模模擬實神經元的橫向抑制,從而在使用不同核心計算的神經元輸出之間產生較大的競爭
-
重疊池化
實驗表示使用 帶交疊的池化的效果比的傳統要好,在top-1和top-5上分別提高了0.4%和0.3%,在訓練階段有避免過擬合的作用。 -
Dropout
Dropout是一種隨機使神經元失活的一種正則化方法,可以有效的避免過擬合。在我們之前實現用LeNet-5來識別MNIST訓練集的時候就使用了這種方法
下面讓我們來詳細的介紹AlexNet
2 - AlexNet模型結構分析
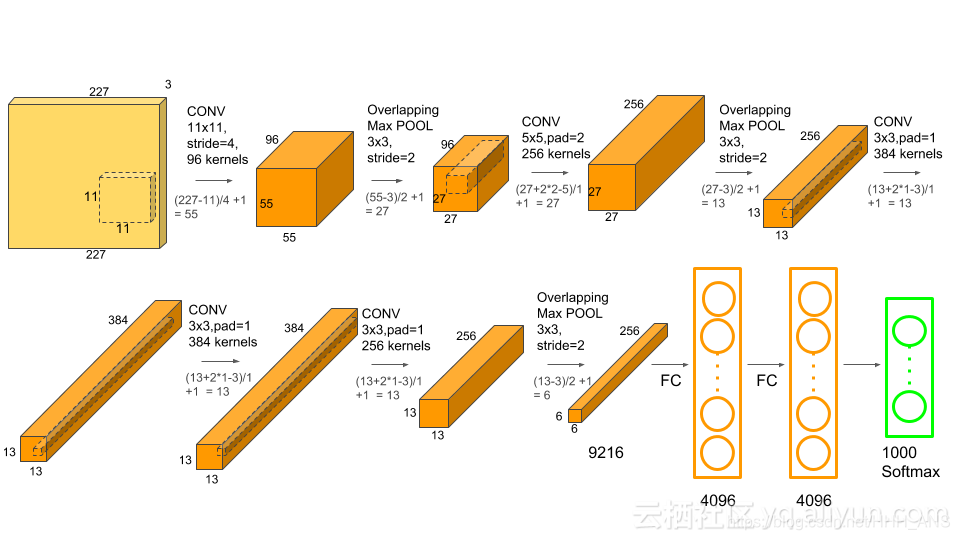
2.1 - Conv1階段
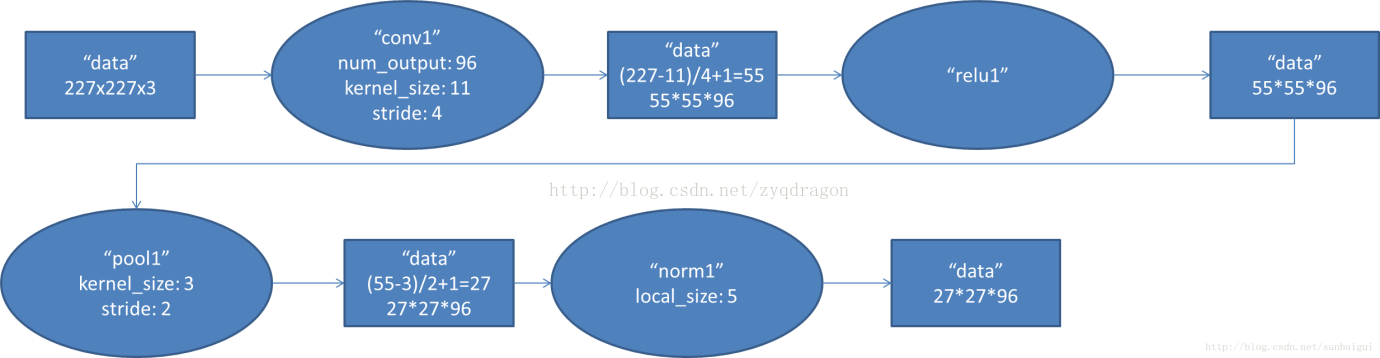
- 輸入資料:227x227x3
- 卷積核:11x11x3
- 卷積核移動步長:4
- 卷積核數量:96
- 池化層:3x3
- 池化層移動步長:2
- 輸出資料:27x27x96
2.2 - Conv2階段
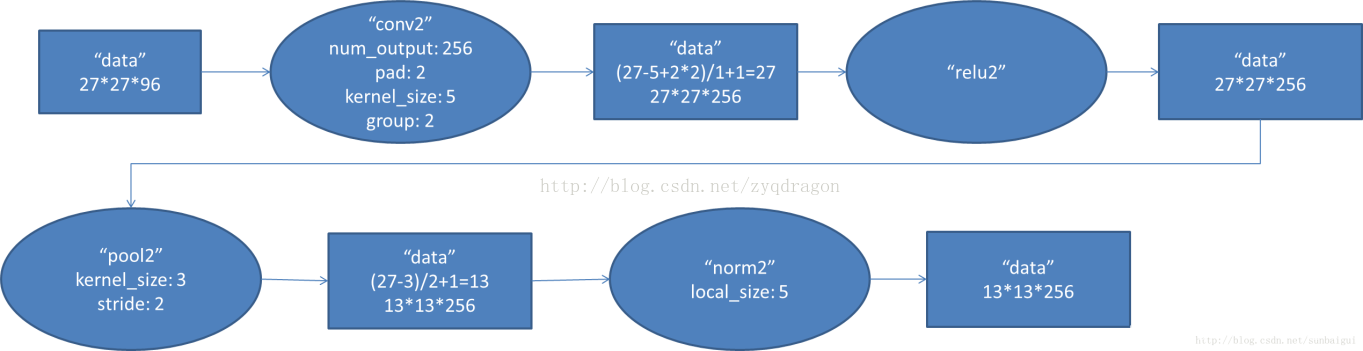
- 輸入資料:27x27x96
- 卷積核:5x5
- 卷積核數量:256
- 卷積核移動步長:2
- padding : 2
- 池化層:3x3
- 池化層移動步長:2
- 輸出資料:13x13x256
2.3 - Conv3階段

- 輸入資料:13x13x256
- 卷積核:3x3
- pading : 1
- 卷積核數量:384
- 輸出資料:13x13x384
2.4 - Conv4階段

- 輸入資料13x13x384
- 卷積核:3x3
- pad:1
- 卷積核數量:384
- 輸出資料:1313384
2.5 - Conv5階段
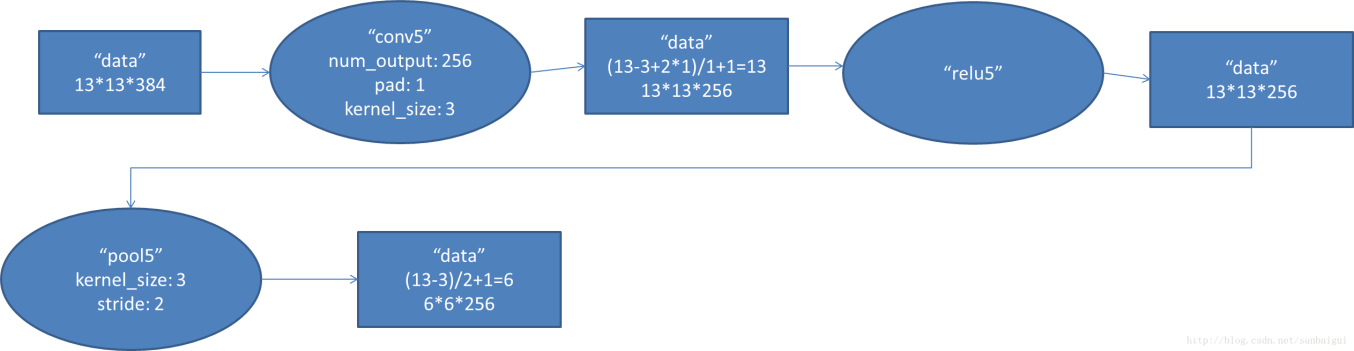
- 輸入資料13x13x384
- 卷積核:3x3
- pad:1
- 卷積核數量:256
- 輸出資料:1313256
之後三個階段為全連線階段引數如圖所示
2.6 FC6階段
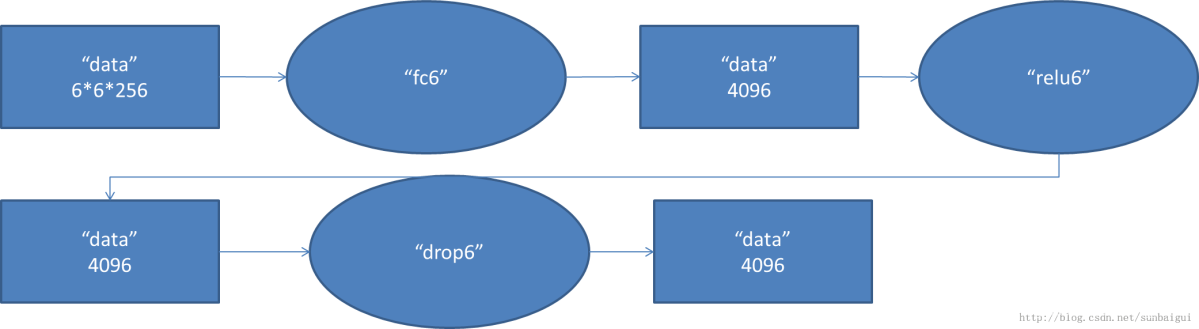
2.7 FC6階段
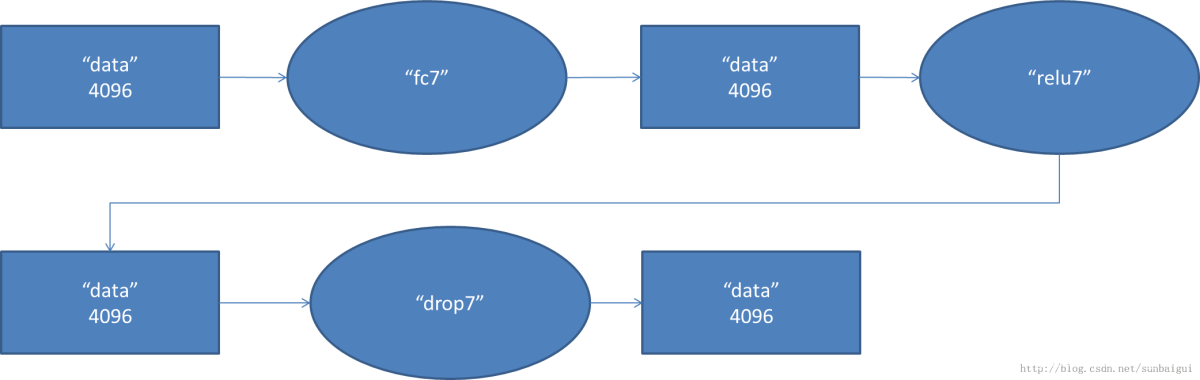
2.8 FC6階段

3 - TensorFlow搭建AlexNet模型:
Keras簡介:
Keras中文手冊 https://keras-cn.readthedocs.io/en/latest/
Keras是一個高層神經網路API,Keras由純Python編寫而成並基Tensorflow、Theano以及CNTK後端。Keras 為支援快速實驗而生,能夠把你的idea迅速轉換為結果,如果你有如下需求,請選擇Keras:
簡易和快速的原型設計(keras具有高度模組化,極簡,和可擴充特性)
支援CNN和RNN,或二者的結合
無縫CPU和GPU切換
Keras適用的Python版本是:Python 2.7-3.6
Keras是一個在TensorFlow之上的高階深度學習框架,可以理解為Keras為TensorFlow的使用提供了多種方便的API,我們可以通過Keras提供的API快速的使用TensorFlow搭建我們所需要的神經網路模型
def AlexNet():
model = Sequential()
model.add(Conv2D(96,(11,11),strides=(4,4),input_shape=(227,227,3),padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(256,(5,5),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='softmax'))
return model
以上是使用Kears快速搭建的一個AlexNet結構。
完整的AlexNet應用模型(Tensorflow)版github地址:
https://github.com/kratzert/finetune_alexnet_with_tensorflow