
千萬級MySQL分頁優化
阿新 • • 發佈:2019-02-08
對於只有幾萬條資料的表這樣做當然沒問題,也不會在使用者體驗上有何不妥,但是要是面對成百萬上千萬的資料表時,這樣就不足以滿足我們的業務需求了,如何做到對千萬級資料表進行高效分頁?首先要學會使用 explain 對你的SQL進行分析,如果你還不會使用 explain 分析SQL語句 傳送門 http://blog.itpub.net/559237/viewspace-496311
一丶合理使用 mysql 查詢快取 結合複合索引進行查詢分頁
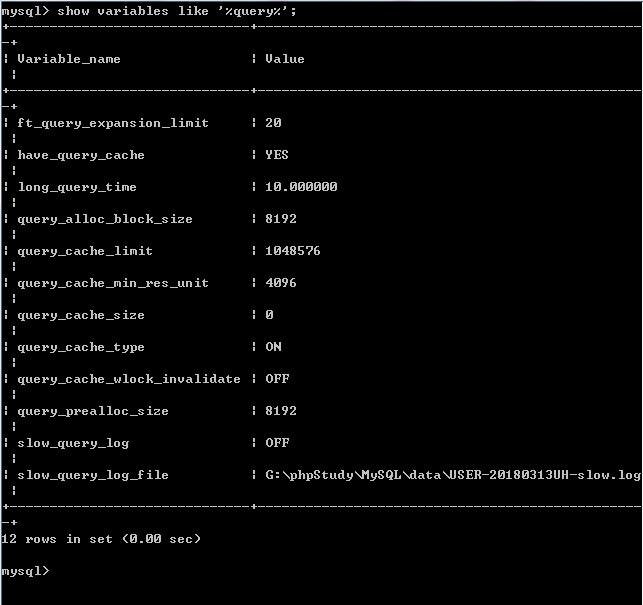
query_caceh_type 是否開啟查詢快取
0 表示不開啟查詢快取,
1 表示始終開啟查詢快取(不要快取使用sql_no_cache) ,
2 表示按需開啟查詢快取 (需要快取使用 sql_cache)。
query_cache_size 給快取分配的最大記憶體空間
對於查詢快取的一些操作。
FLUSH QUERY CACHE; // 清理查詢快取記憶體碎片。
RESET QUERY CACHE; // 從查詢快取中移出所有查詢。
FLUSH tabName; //關閉所有開啟的表,同時該操作將會清空查詢快取中的內容。
分頁說到底也是查詢的一種,既然是查詢我們就可以為他設定索引來提高查詢速度
二丶SQL語句的優化(不使用索引)
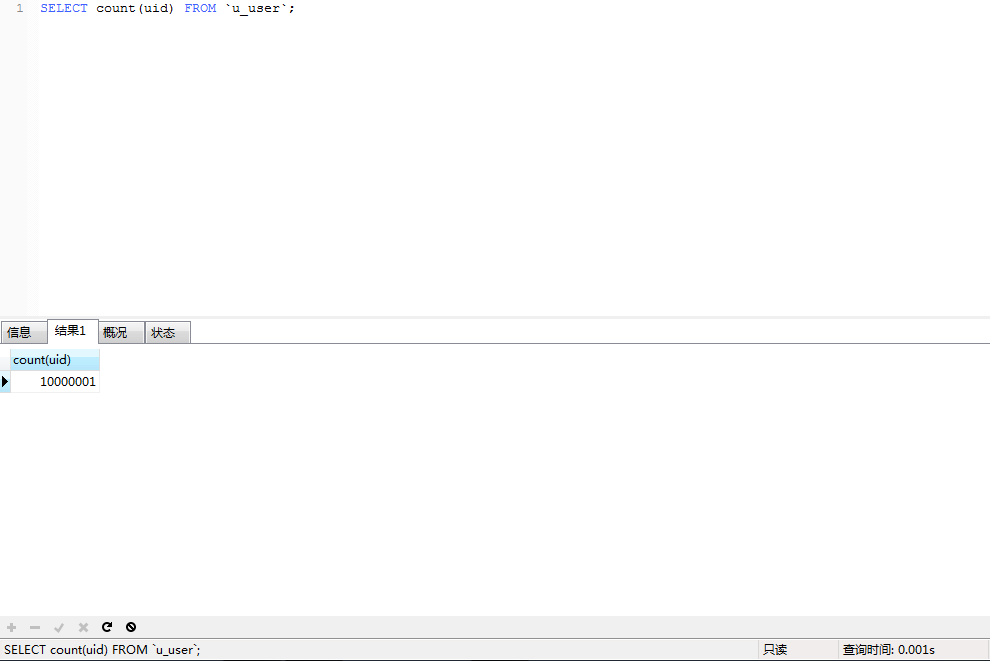
這裡有一張千萬級別的資料表,表結構如下
使用 SELECT * FROM LIMIT 0,10 分別對錶進行常規分頁,當偏移量達到一百萬和七百萬時的對比如下
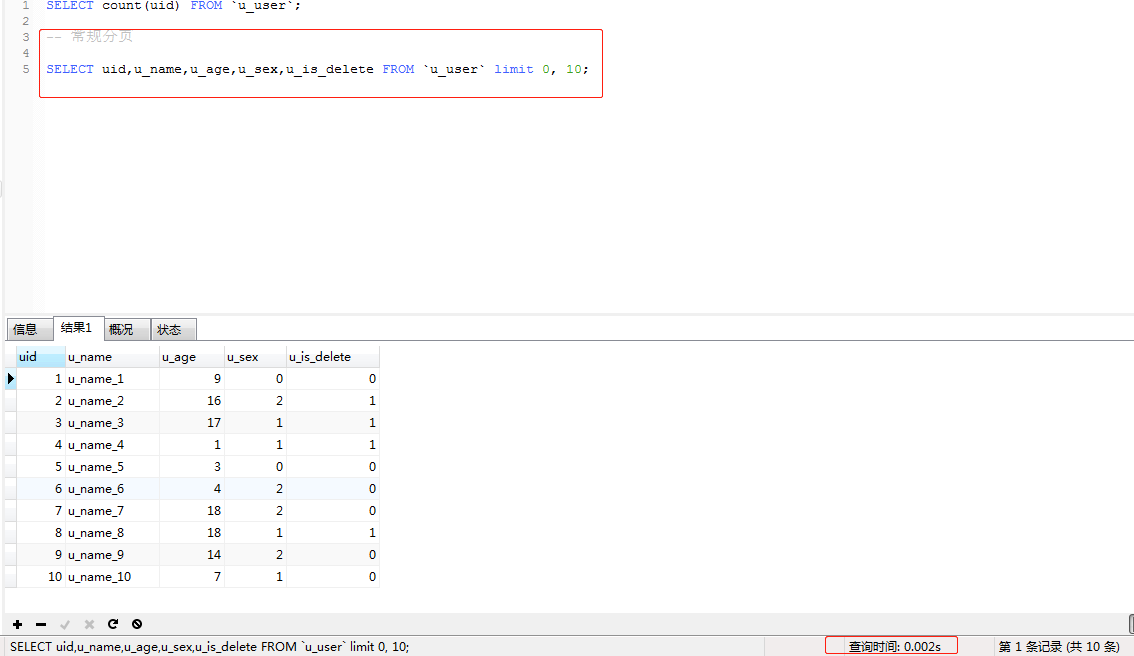
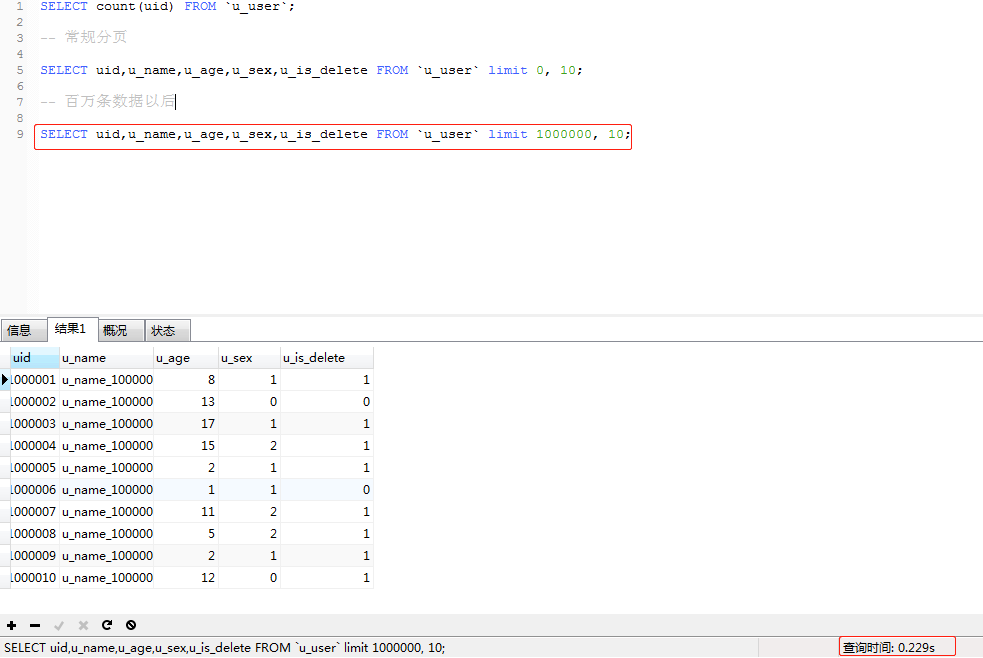
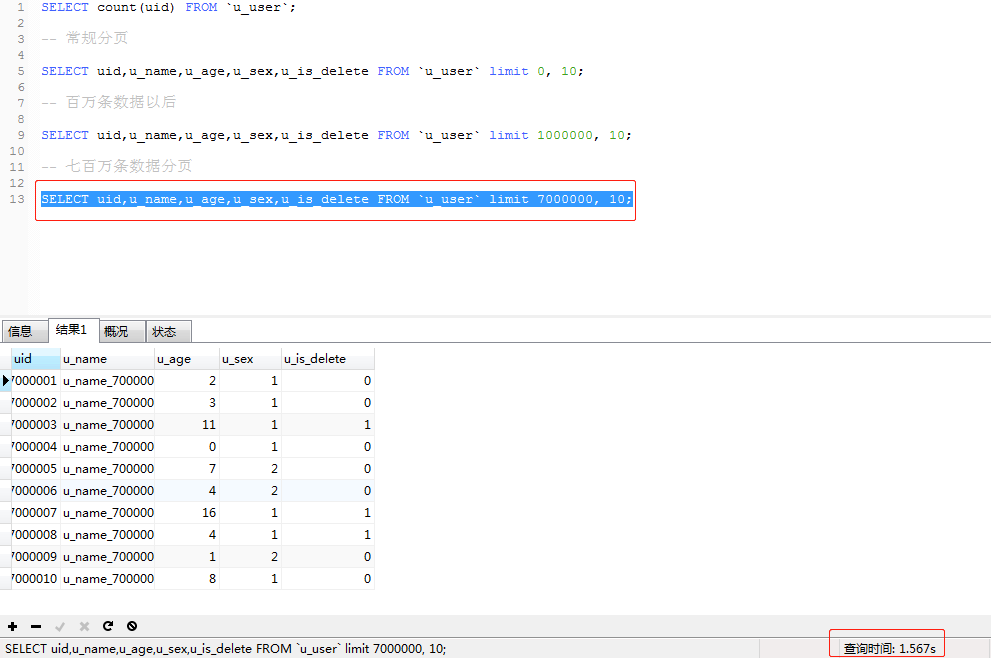
當偏移量達到七百萬時 的查詢時間是1.57s,現在這在我們得業務場景中是不能被應用的,接下來對這句SQL進行優化
a. 查詢出最大偏移量的uid,再進行分頁 (SELECT uid,u_name,u_age,u_sex,u_is_delete FROM u_user WHERE uid >=(SELECT uid FROM `u_user` LIMIT 7000000, 1) LIMIT 10)
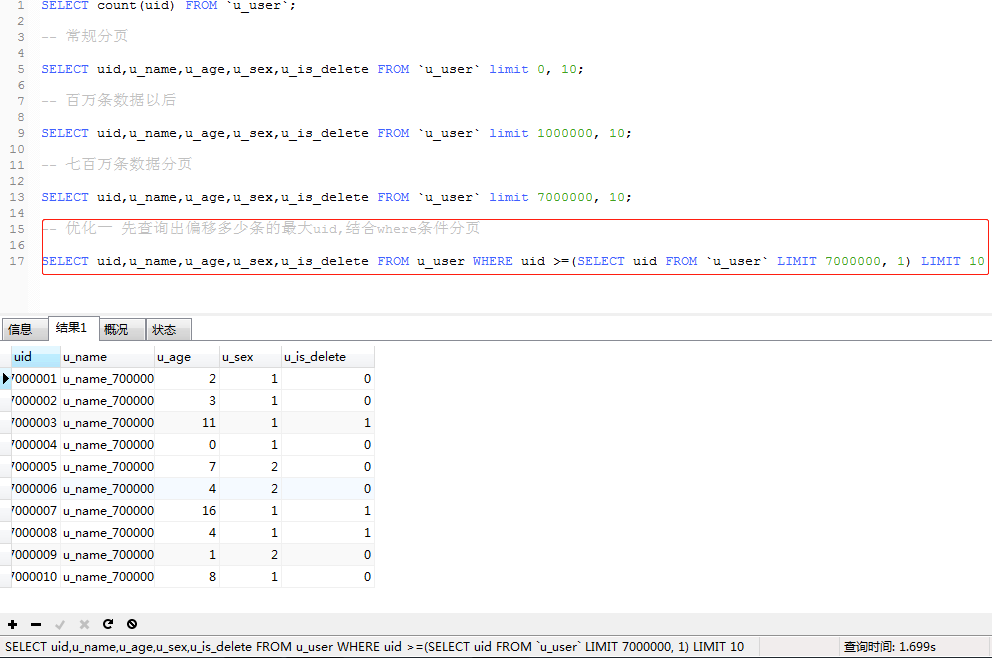
b.先去查詢到最大偏移量然後再進行分頁,這樣看來時間好像變得更長了,顯示這種方式不符合我們的場景,對這句SQL再次進行優化 (SELECT uid,u_name,u_age,u_sex,u_is_delete FROM u_user WHERE uid>7000000 LIMIT 10;)
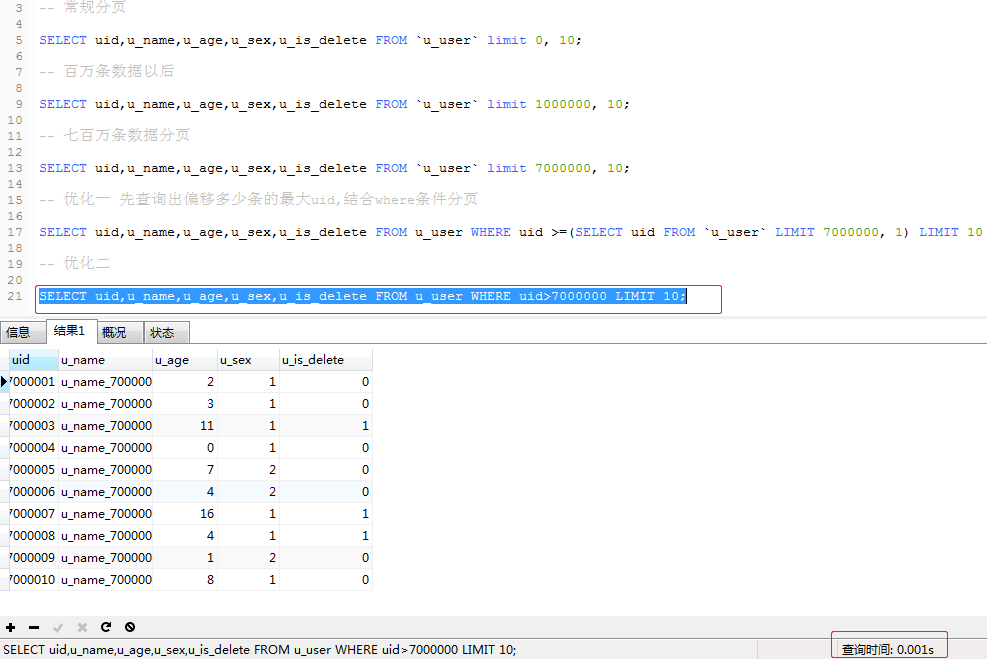
非常棒的查詢時間,0.001s,幾乎是秒查詢,這樣即使是千萬級的資料表分頁起來也能輕鬆應對
當然,這只是我能想到的實現千萬級資料表分頁的兩種方案,若有其他方式,歡迎評論