
mysql分頁查詢優化(索引延遲關聯)
阿新 • • 發佈:2018-12-12
對於web後臺報表匯出是一種常見的功能點,實際對應服務後端即資料庫的排序分頁查詢。如下示例為公司商戶積分報表匯出其中一個sql ,當大批量的匯出請求進入時候,mysql的cpu急劇上升瞬間有拖垮庫的風險。
SELECT * FROM coupons.cp_score_log WHERE `m_shopid` = 40861 AND `add_time` BETWEEN 1483200000 AND 1544543999 ORDER BY add_time DESC LIMIT 118000 ,1000 ;
報表匯出功能存在幾個問題:
1、時間跨度太大,資料量劇增。(可以結合業務需求,限制一定時間範圍,比如只能匯出3個月以內資料)
2、DB方面沒有限制併發。(需要dba一起參與)
3、sql未考慮LIMIT分頁過大,查詢效能問題。(索引延遲關聯,本文重點 或者 限制分頁上限)
執行結果:18.94s (結果受到機器峰值影響,可能低一些,可能更高)
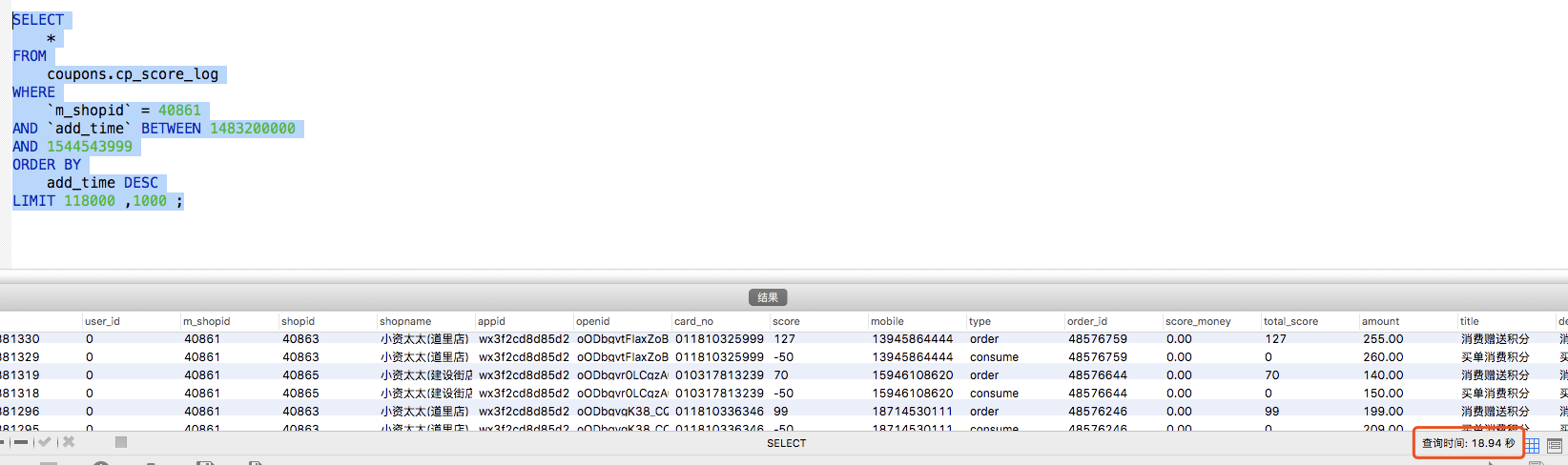
sql執行計劃 :
表結構:
CREATE TABLE `cp_score_log` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, ...... `m_shopid` int(10) DEFAULT '0' COMMENT '總店id', ...... `add_time` int(10) DEFAULT '0', `......PRIMARY KEY (`id`), KEY `idx_cardno` (`card_no`), KEY `idx_shopid` (`shopid`) USING BTREE, KEY `idx_orderid` (`order_id`), KEY `idx_shopid_add_time_score` (`shopid`,`add_time`,`score`), KEY `idx_mshopid` (`m_shopid`,`add_time`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=24130302 DEFAULT CHARSET=utf8 COMMENT='積分記錄表'
表的資料基本在2400萬左右未進行拆分,通過檢視sql和執行計劃發現已經命中索引【idx_mshopid】,但是查詢效率仍然很低。拋開其他問題只針對sql來說,核心的問題出在LIMIT。
MySQL中 【LIMIT offset, m】並不是跳過offset然後取m行資料,而是直接取【offset+m】行資料,丟棄前offset行返回m行。因此查詢的效率就特別的低,特別當offset特別大的時候。
針對上面提出第3點問題,可以考慮使用後索引延遲關聯,即 通過建立中間表覆蓋索引查詢返回需要的主鍵,再根據主鍵關聯原表獲得需要的資料。 同時限制最大的分頁數量,比如百度最發分頁即為79頁 。
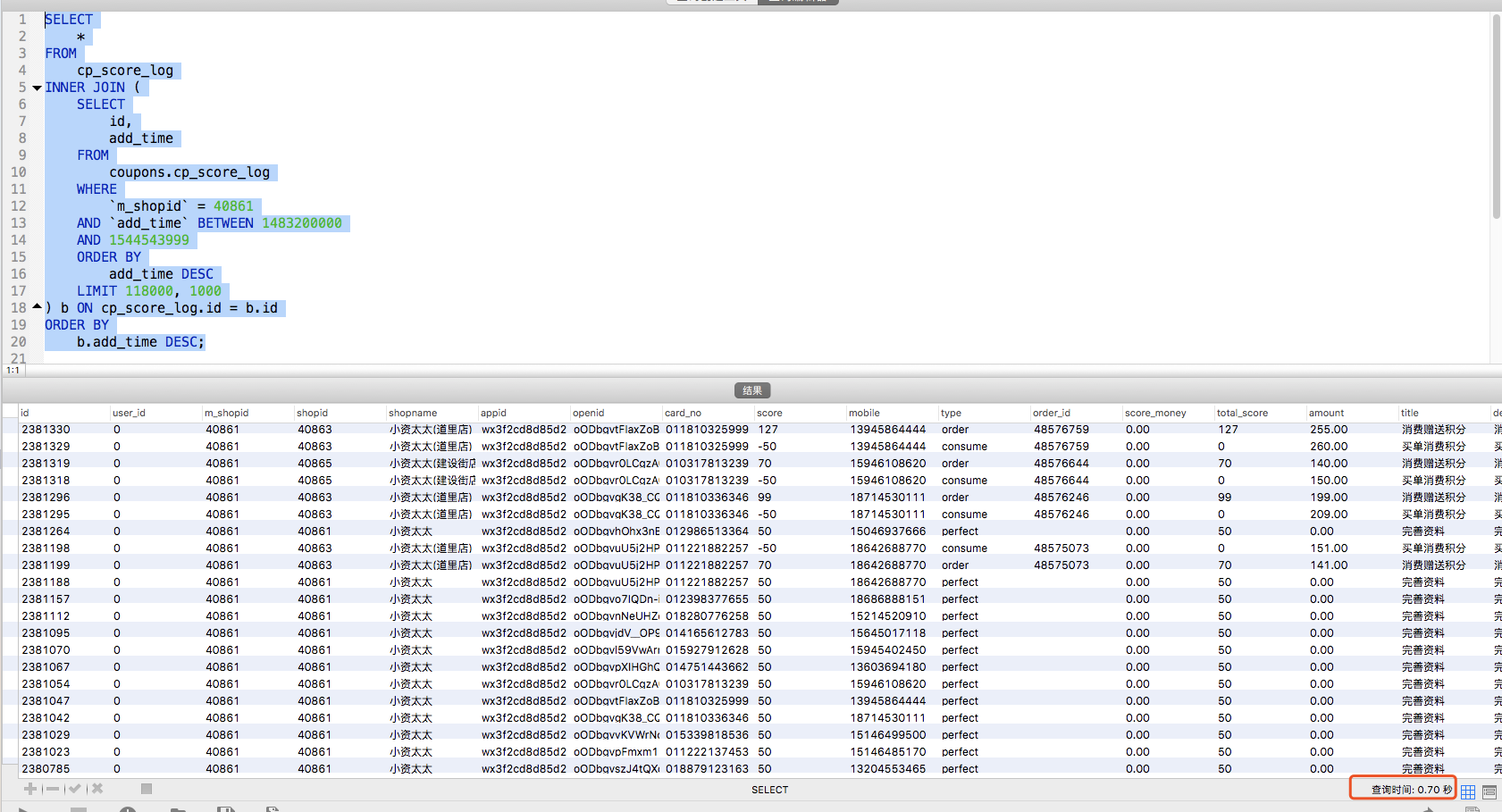
SELECT * FROM cp_score_log INNER JOIN ( SELECT id, add_time FROM coupons.cp_score_log WHERE `m_shopid` = 40861 AND `add_time` BETWEEN 1483200000 AND 1544543999 ORDER BY add_time DESC LIMIT LIMIT 118000 ,1000 ) b ON cp_score_log.id = b.id ORDER BY b.add_time DESC;
執行結果:0.7s (天差地別)
sql執行計劃:
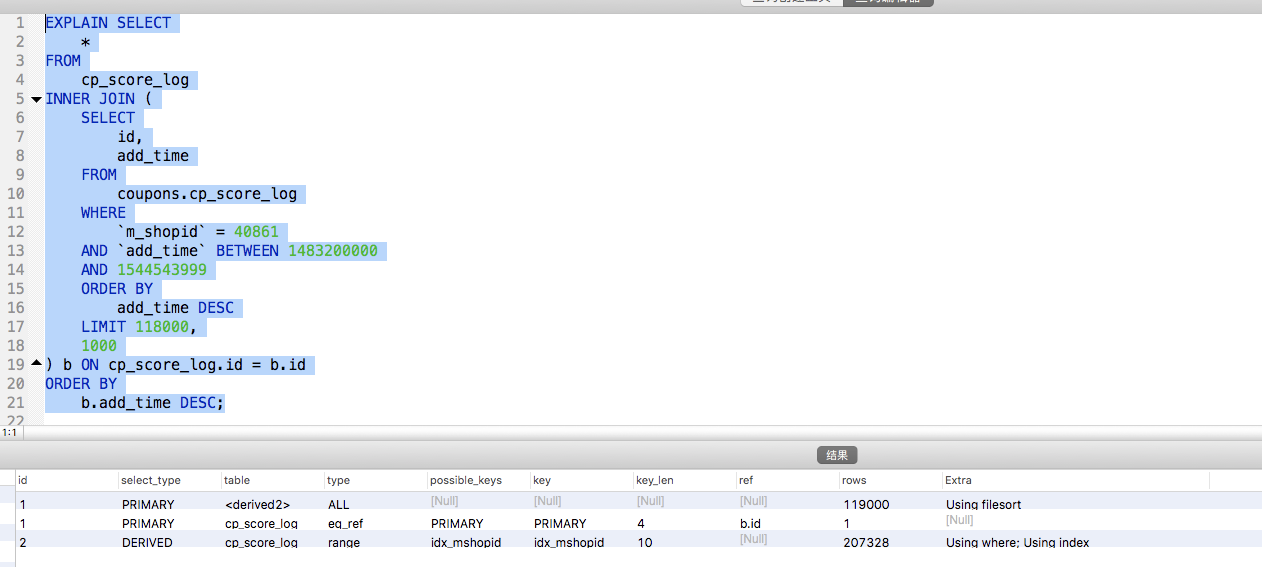
由此可見,使用sql延遲關聯sql效率確實提升明顯。但是並非能解決所以問題,當表資料過大已經資料庫併發提高時,還是會出現查詢慢甚至拖垮db當風險。所以因綜合考慮,將請求量削峰。