
GoogLeNet 之 Inception-v1 解讀
本篇部落格的目的是展示 GoogLeNet 的 Inception-v1 中的結構,順便溫習裡面涉及的思想。
1 版本主要思想詳述
1.1 Inception v1
Inception V1 在ILSVRC 2014的比賽中,以較大優勢取得了第一名,top-5錯誤率6.67%。Inception V1降低引數量的目的有兩點,第一,引數越多模型越龐大,需要供模型學習的資料量就越大,而目前高質量的資料非常昂貴;第二,引數越多,耗費的計算資源也會更大。Inception V1引數少但效果好的原因除了模型層數更深、表達能力更強外,還有兩點:一是去除了最後的全連線層,用全域性平均池化層
這裡對傳統的卷積層結構做個介紹,原理如下所示:
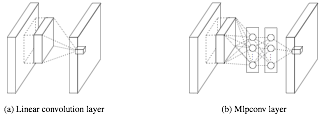
左側是是傳統的卷積層結構(線性卷積),在一個尺度上只有一次卷積;右圖是Network in Network結構(NIN結構),先進行一次普通的卷積(比如3x3),緊跟再進行一次1x1的卷積,對於某個畫素點來說1x1卷積等效於該畫素點在所有特徵上進行一次全連線的計算,所以右側圖的1x1卷積畫成了全連線層的形式,需要注意的是NIN結構中無論是第一個3x3卷積還是新增的1x1卷積,後面都緊跟著啟用函式(比如relu)。將兩個卷積串聯,就能組合出更多的非線性特徵。舉個例子,假設第1個3x3卷積+啟用函式近似於f1(x)=ax2+bx+c,第二個1x1卷積+啟用函式近似於f2(x)=mx2+nx+q,那f1(x)和f2(f1(x))比哪個非線性更強,更能模擬非線性的特徵?答案是顯而易見的。
1.1.1 結構原理
Inception架構的主要想法是考慮怎樣近似卷積視覺網路的最優稀疏結構並用容易獲得的密集元件進行覆蓋。注意假設轉換不變性,這意味著我們的網路將以卷積構建塊為基礎。我們所需要做的是找到最優的區域性構造並在空間上重複它。
為了避免塊校正的問題,目前Inception架構形式的濾波器的尺寸僅限於1×1、3×3、5×5,這個決定更多的是基於便易性而不是必要性。另外,由於池化操作對於目前卷積網路的成功至關重要,因此建議在每個這樣的階段新增一個替代的並行池化路徑應該也應該具有額外的有益效果。其原理如下圖所示:

第一個分支對輸入進行1*1的卷積,它可以進行跨通道的特徵變換,提高網路的表達能力,同時可以對輸出通道升維和降維;
第二個分支先使用了1*1卷積,然後連線3*3卷積,相當於進行了兩次特徵變換;
第三個分支先是1*1的卷積,然後連線5*5卷積;
第四個分支則是3*3最大池化後直接使用1*1卷積;
Inception Module的4個分支在最後通過一個聚合操作合併(在輸出通道數這個維度上聚合)。
其中:
在圖片資料中,天然的就是臨近區域的資料相關性高,因此相鄰的畫素點被卷積操作連線在一起。而我們可能有多個卷積核,在同一空間位置但在不同通道的卷積核的輸出結果相關性極高。
1*1的卷積作用:
- 可以進行跨通道的特徵變換,把這些相關性很高的、在同一個空間位置但是不同通道的特徵連線在一起,提高網路的表達能力;
- 同時可以對輸出通道升維(拉伸)和降維(壓縮),計算量小。
多尺度卷積再聚合的作用:
- 直觀感覺上在多個尺度上同時進行卷積,能提取到不同尺度的特徵。
- 利用稀疏矩陣分解成密集矩陣計算的原理來加快收斂速度。
- Hebbin赫布原理。用在inception結構中就是要把相關性強的特徵匯聚到一起。有點像上面提到的這點。
總的來說,Inception Module中包含了3種不同尺寸的卷積和1個最大池化,增加了網路對不同尺度的適應性,讓網路的深度和寬度高效率地擴充,提升準確率且不致於過擬合。
1.1.2 網路結構
Inception Net有22層深,除了最後一層的輸出,其中間節點的分類效果也很好。因此在Inception Net中,還使用到了輔助分類節點(auxiliary classifiers),即將中間某一層的輸出用作分類,並按一個較小的權重(0.3)加到最終分類結果中。這樣相當於做了模型融合,同時給網路增加了反向傳播的梯度訊號,也提供了額外的正則化(實際上這在低階的層級上處理用處不大),對於整個Inception Net的訓練很有裨益。其完整結構如下所示:

參考資料: