
Inception(V1-V4)
環境:Win8.1 TensorFlow1.0.1
軟體:Anaconda3 (整合Python3及開發環境)
TensorFlow安裝:pip install tensorflow (CPU版) pip install tensorflow-gpu (GPU版)
TFLearn安裝:pip install tflearn
參考:
1. Inception[V1]: Going Deeper with Convolutions
2. Inception[V2]: Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
3. Inception[V3]: Rethinking the Inception Architecture for Computer Vision
4. Inception[V4]: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
1. 前言
上篇介紹的 NIN 在改造傳統 CNN 結構上作出了矚目貢獻,通過 Mlpconv Layer 和 Global Average Pooling 建立的網路模型在多個數據集上取得了不錯的結果,同時將訓練引數控制在 AlexNet
本文將要介紹的是在 ILSVRC 2014 取得了最好的成績的 GoogLeNet,及其核心結構—— Inception。早期的V1 結構借鑑了 NIN 的設計思路,對網路中的傳統卷積層進行了修改,針對限制深度神經網路效能的主要問題,一直不斷改進延伸到 V4:
- 引數空間大,容易過擬合,且訓練資料集有限;
- 網路結構複雜,計算資源不足,導致難以應用;
- 深層次網路結構容易出現梯度彌散,模型效能下降。
2. Inception
GoogLeNet 對網路中的傳統卷積層進行了修改,提出了被稱為 Inception
其各個版本的設計思路:
2.1 Inception V1

Naive Inception
Inception module 的提出主要考慮多個不同 size 的卷積核能夠增強網路的適應力,paper 中分別使用1*1、3*3、5*5卷積核,同時加入3*3 max pooling。
隨後文章指出這種 naive 結構存在著問題:每一層 Inception module 的 filters 引數量為所有分支上的總數和,多層 Inception 最終將導致 model 的引數數量龐大,對計算資源有更大的依賴。
在 NIN 模型中與1*1卷積層等效的 MLPConv 既能跨通道組織資訊,提高網路的表達能力,同時可以對輸出有效進行降維,因此文章提出了Inception module with dimension reduction,在不損失模型特徵表示能力的前提下,儘量減少 filters 的數量,達到降低模型複雜度的目的:
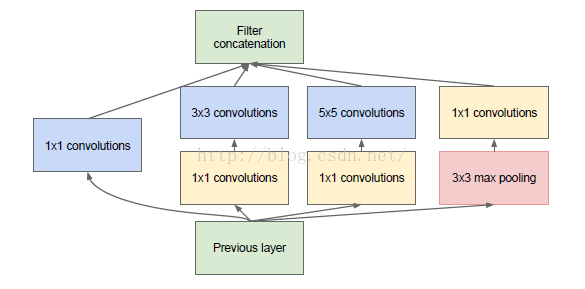
Inception Module
Inception Module 的4個分支在最後通過一個聚合操作合併(在輸出通道數這個維度上聚合,在 TensorFlow 中使用 tf.concat(3, [], []) 函式可以實現合併)。
完整的 GoogLeNet 結構在傳統的卷積層和池化層後面引入了 Inception 結構,對比 AlexNet 雖然網路層數增加,但是引數數量減少的原因是絕大部分的引數集中在全連線層,最終取得了 ImageNet 上 6.67% 的成績。
2.2 Inception V2
Inception V2 學習了 VGG 用兩個3´3的卷積代替5´5的大卷積,在降低引數的同時建立了更多的非線性變換,使得 CNN 對特徵的學習能力更強:
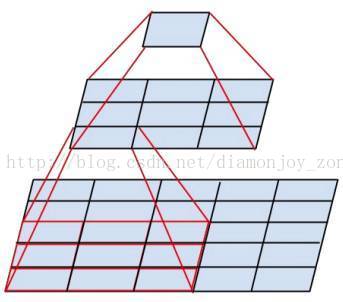
兩個3´3的卷積層功能類似於一個5´5的卷積層
另外提出了著名的 Batch Normalization(以下簡稱BN)方法。BN 是一個非常有效的正則化方法,可以讓大型卷積網路的訓練速度加快很多倍,同時收斂後的分類準確率也可以得到大幅提高。BN 在用於神經網路某層時,會對每一個 mini-batch 資料的內部進行標準化(normalization)處理,使輸出規範化到 N(0,1) 的正態分佈,減少了 Internal Covariate Shift(內部神經元分佈的改變)。
補充:在 TensorFlow 1.0.0 中採用 tf.image.per_image_standardization() 對影象進行標準化,舊版為 tf.image.per_image_whitening。
BN 的論文指出,傳統的深度神經網路在訓練時,每一層的輸入的分佈都在變化,導致訓練變得困難,我們只能使用一個很小的學習速率解決這個問題。而對每一層使用 BN 之後,我們就可以有效地解決這個問題,學習速率可以增大很多倍,達到之前的準確率所需要的迭代次數只有1/14,訓練時間大大縮短。而達到之前的準確率後,可以繼續訓練,並最終取得遠超於 Inception V1 模型的效能—— top-5 錯誤率 4.8%,已經優於人眼水平。因為 BN 某種意義上還起到了正則化的作用,所以可以減少或者取消 Dropout 和 LRN,簡化網路結構。
2.3 Inception V3
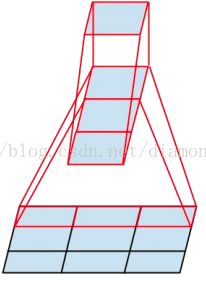


將一個3´3卷積拆成1´3卷積和3´1卷積
一是引入了 Factorization into small convolutions 的思想,將一個較大的二維卷積拆成兩個較小的一維卷積,比如將7´7卷積拆成1´7卷積和7´1卷積,或者將3´3卷積拆成1´3卷積和3´1卷積,如上圖所示。一方面節約了大量引數,加速運算並減輕了過擬合(比將7´7卷積拆成1´7卷積和7´1卷積,比拆成3個3´3卷積更節約引數),同時增加了一層非線性擴充套件模型表達能力。論文中指出,這種非對稱的卷積結構拆分,其結果比對稱地拆為幾個相同的小卷積核效果更明顯,可以處理更多、更豐富的空間特徵,增加特徵多樣性。
另一方面,Inception V3 優化了 Inception Module 的結構,現在 Inception Module 有35´35、17´17和8´8三種不同結構。這些 Inception Module 只在網路的後部出現,前部還是普通的卷積層。並且 Inception V3 除了在 Inception Module 中使用分支,還在分支中使用了分支(8´8的結構中),可以說是Network In Network In Network。最終取得 top-5 錯誤率 3.5%。
2.4 Inception V4
Inception V4 相比 V3 主要是結合了微軟的 ResNet,將錯誤率進一步減少到 3.08%。
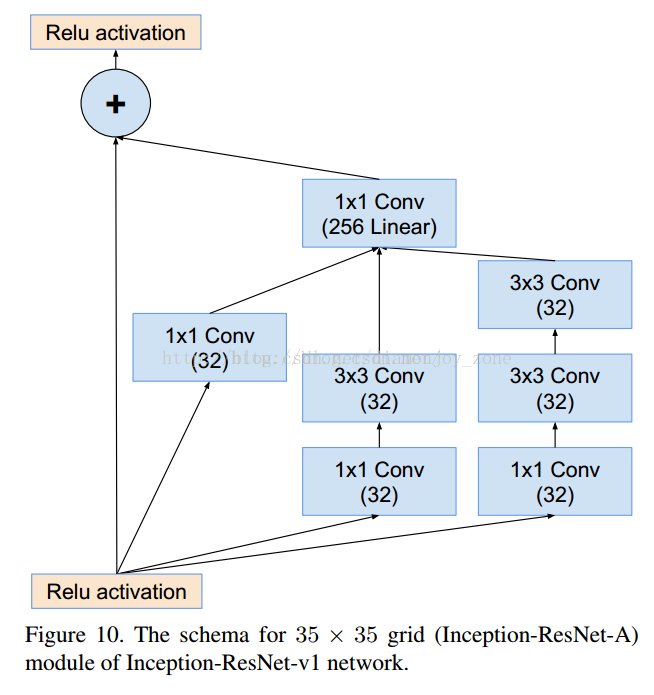
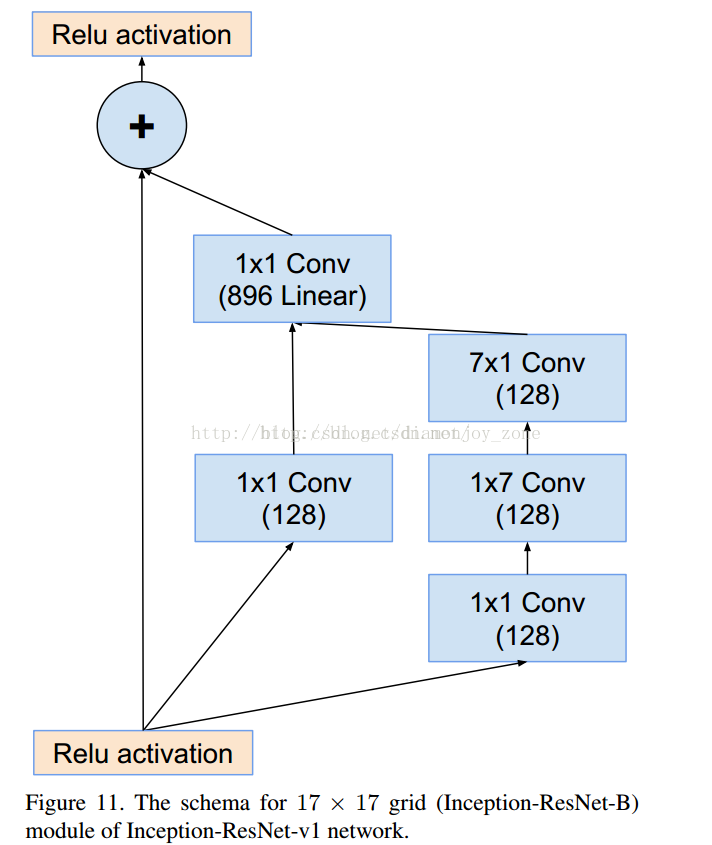
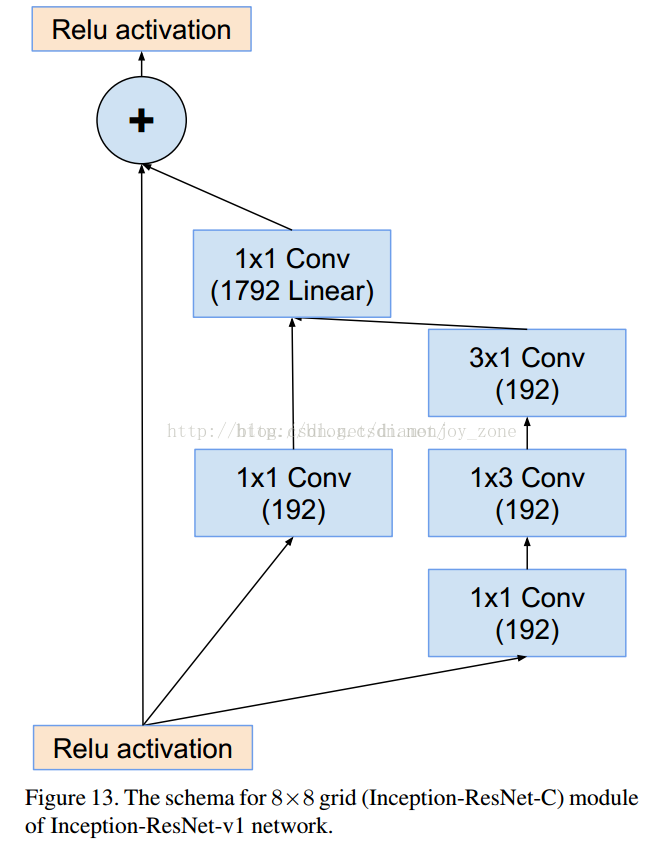
3. GoogLeNet V1
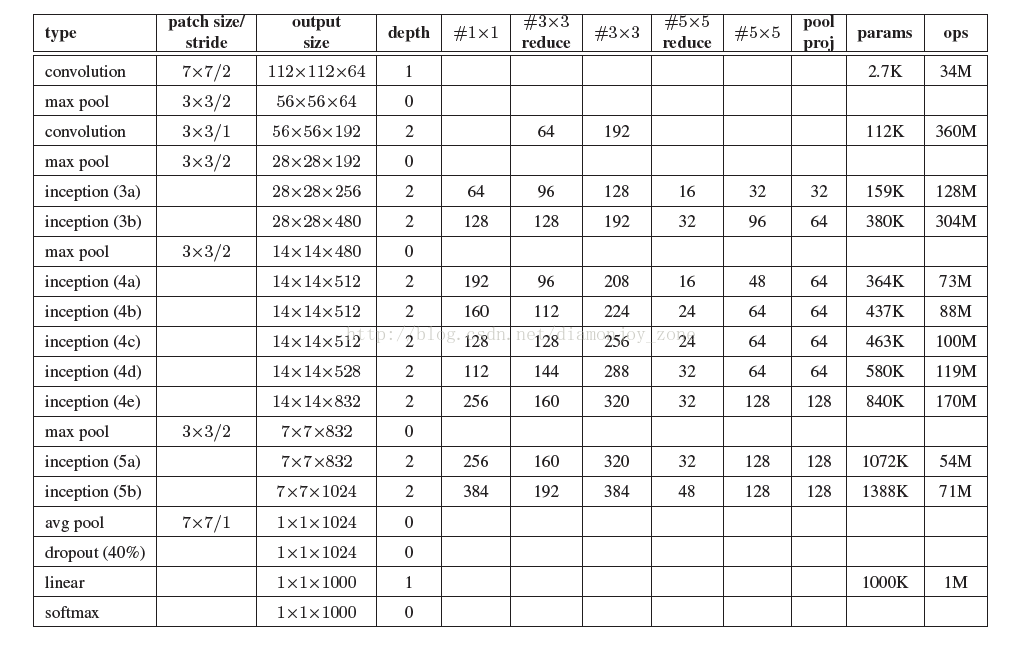
例如,在 tflearn 的 googlenet.py 中,定義 Inception(3a) 中的分支結構,用 merge 函式合併 feature map:
-
network = input_data(shape=[
None,
227,
227,
3])
-
conv1_7_7 = conv_2d(network,
64,
7, strides=
2, activation=
'relu', name =
'conv1_7_7_s2')
-
pool1_3_3 = max_pool_2d(conv1_7_7,
3,strides=
2)
-
pool1_3_3 = local_response_normalization(pool1_3_3)
-
conv2_3_3_reduce = conv_2d(pool1_3_3,
64,
1, activation=
'relu',name =
'conv2_3_3_reduce')
-
conv2_3_3 = conv_2d(conv2_3_3_reduce,
192,
3, activation=
'relu', name=
'conv2_3_3')
-
conv2_3_3 = local_response_normalization(conv2_3_3)
-
pool2_3_3 = max_pool_2d(conv2_3_3, kernel_size=
3, strides=
2, name=
'pool2_3_3_s2')
-
inception_3a_1_1 = conv_2d(pool2_3_3,
64,
1, activation=
'relu', name=
'inception_3a_1_1')
-
inception_3a_3_3_reduce = conv_2d(pool2_3_3,
96,
1, activation=
'relu', name=
'inception_3a_3_3_reduce')
-
inception_3a_3_3 = conv_2d(inception_3a_3_3_reduce,
128,filter_size=
3, activation=
'relu', name =
'inception_3a_3_3')
-
inception_3a_5_5_reduce = conv_2d(pool2_3_3,
16, filter_size=
1,activation=
'relu', name =
'inception_3a_5_5_reduce' )
-
inception_3a_5_5 = conv_2d(inception_3a_5_5_reduce,
32, filter_size=
5, activation=
'relu', name=
'inception_3a_5_5')
-
inception_3a_pool = max_pool_2d(pool2_3_3, kernel_size=
3, strides=
1, )
-
inception_3a_pool_1_1 = conv_2d(inception_3a_pool,
32, filter_size=
1, activation=
'relu', name=
'inception_3a_pool_1_1')
-
-
# merge the inception_3a__
-
inception_3a_output = merge([inception_3a_1_1, inception_3a_3_3, inception_3a_5_5, inception_3a_pool_1_1], mode=
'concat', axis=
3)
最後對於 Inception(5b) 的7*7*1024的輸出採用7*7的 avg pooling,40%的 Dropout 和 softmax:
-
pool5_7_7 = avg_pool_2d(inception_5b_output, kernel_size=
7, strides=
1)
-
pool5_7_7 = dropout(pool5_7_7,
0.4)
-
loss = fully_connected(pool5_7_7,
17,activation=
'softmax')
由於解決 Oxford 17 類鮮花 資料集分類任務,最後的輸出通道設為17。
4. 總結
Inception V1——構建了1x1、3x3、5x5的 conv 和3x3的 pooling 的分支網路,同時使用 MLPConv 和全域性平均池化,擴寬卷積層網路寬度,增加了網路對尺度的適應性;
Inception V2——提出了 Batch Normalization,代替 Dropout 和 LRN,其正則化的效果讓大型卷積網路的訓練速度加快很多倍,同時收斂後的分類準確率也可以得到大幅提高,同時學習 VGG 使用兩個3´3的卷積核代替5´5的卷積核,在降低引數量同時提高網路學習能力;
Inception V3——引入了 Factorization,將一個較大的二維卷積拆成兩個較小的一維卷積,比如將3´3卷積拆成1´3卷積和3´1卷積,一方面節約了大量引數,加速運算並減輕了過擬合,同時增加了一層非線性擴充套件模型表達能力,除了在 Inception Module 中使用分支,還在分支中使用了分支(Network In Network In Network);
Inception V4——研究了 Inception Module 結合 Residual Connection,結合 ResNet 可以極大地加速訓練,同時極大提升效能,在構建 Inception-ResNet 網路同時,還設計了一個更深更優化的 Inception v4 模型,能達到相媲美的效能。