
爬取某招聘網站的招聘資訊(獵聘)
阿新 • • 發佈:2019-02-03
這該找工作了,俗話說的胡奧,金九銀十嘛。一個一個招聘資訊找著看,有點麻煩。所以心動了下,不如把我想找的資訊都爬取下來,直接sql語句查詢所有相關資訊,多方便,是吧~
注:
如果start-urls只設置一個的話,那麼只會爬取等於或者小於40條資料(會有重複)
Spider塊:
資訊搜尋,原本是想搜python、爬蟲之類的,後來寫著寫著就變成java了。果真還是忘不了自己的母語言啊~
import scrapy
from liepinSpider.items import LiepinspiderItem
class LisPinSpider(scrapy.Spider): pipelines塊:
不要忘記在setting中開啟pipelines模組啊~~
ITEM_PIPELINES = {
‘liepinSpider.pipelines.LiepinspiderPipeline’: 1,
}
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
from scrapy.exceptions import DropItem
def dbHandle():
conn = pymysql.connect(
host='localhost',
user='root',
passwd='Cs123456.',
charset='utf8',
db='liepin',
use_unicode=False
)
return conn
class LiepinspiderPipeline(object):
def process_item(self, item, spider):
#連線資料庫
db = dbHandle()
#開啟遊標
cursor = db.cursor()
#拼接sql
sql = 'insert into liepin_list (url, title, company, money, address, times, job_query, tags, job_content) ' \
'value ("{html_url}", "{title}", "{company}", "{money}", "{address}", "{times}", "{job_query}", "{tags}", "{job_content}");'.format(
**item)
try:
#判斷
re = self.db_distinct(item['html_url'])
if re:
try:
cursor.execute(sql)
db.commit()
except:
raise DropItem('sql執行錯誤')
else:
raise DropItem('資料已存在')
except:
db.rollback()
cursor.close()
#通過招聘地址的url來判斷這個頁面是否被儲存過
def db_distinct(self, html_url):
db = dbHandle()
cursor = db.cursor()
sql = 'select * from liepin_list where url ="{}"'.format(html_url)
cursor.execute(sql)
data = cursor.fetchone()
cursor.close()
if data == None:
return True
else:
return False
表結構:
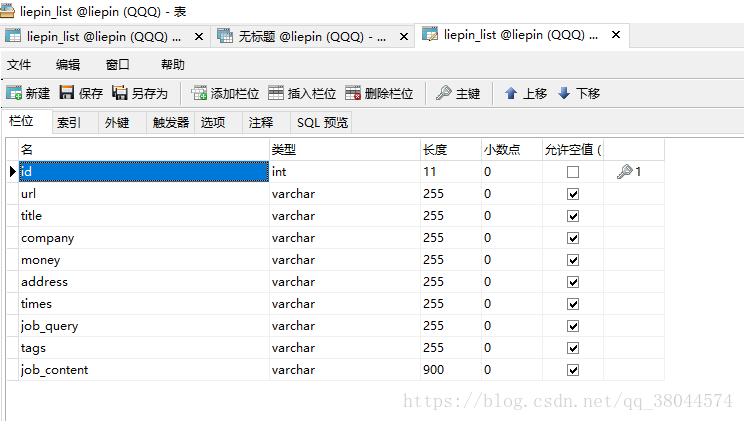
查詢的部分資料:
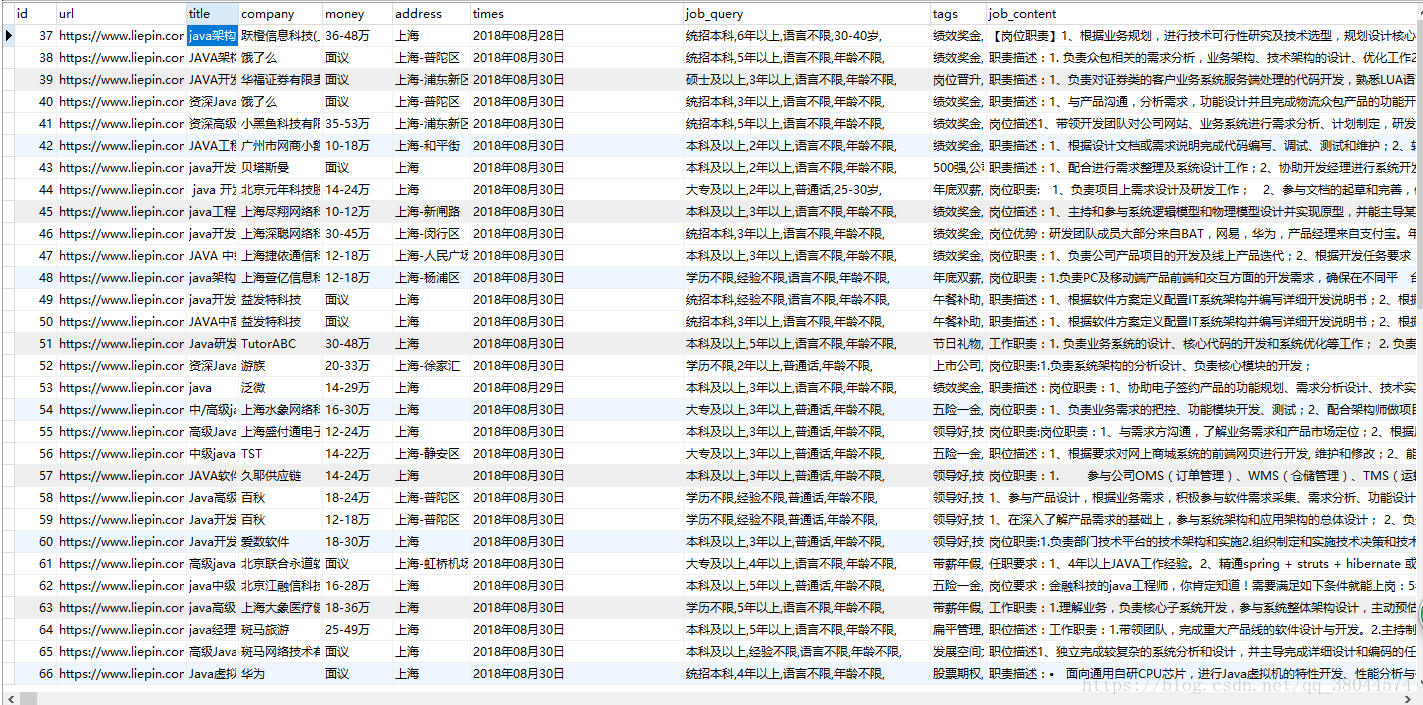
這樣就大功告成了,謝謝觀看。