批量爬取某圖片網站的圖片
阿新 • • 發佈:2018-11-01
批量爬取某圖片網站的圖片
宣告:僅用於爬蟲學習,禁止用於商業用途謀取利益
1、網頁解析
-
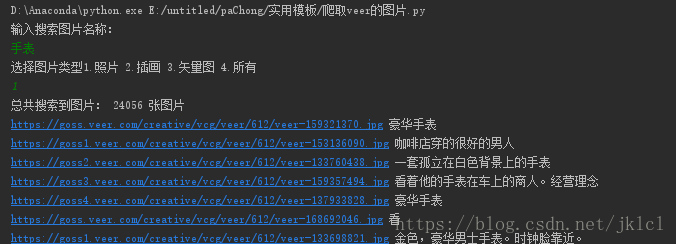
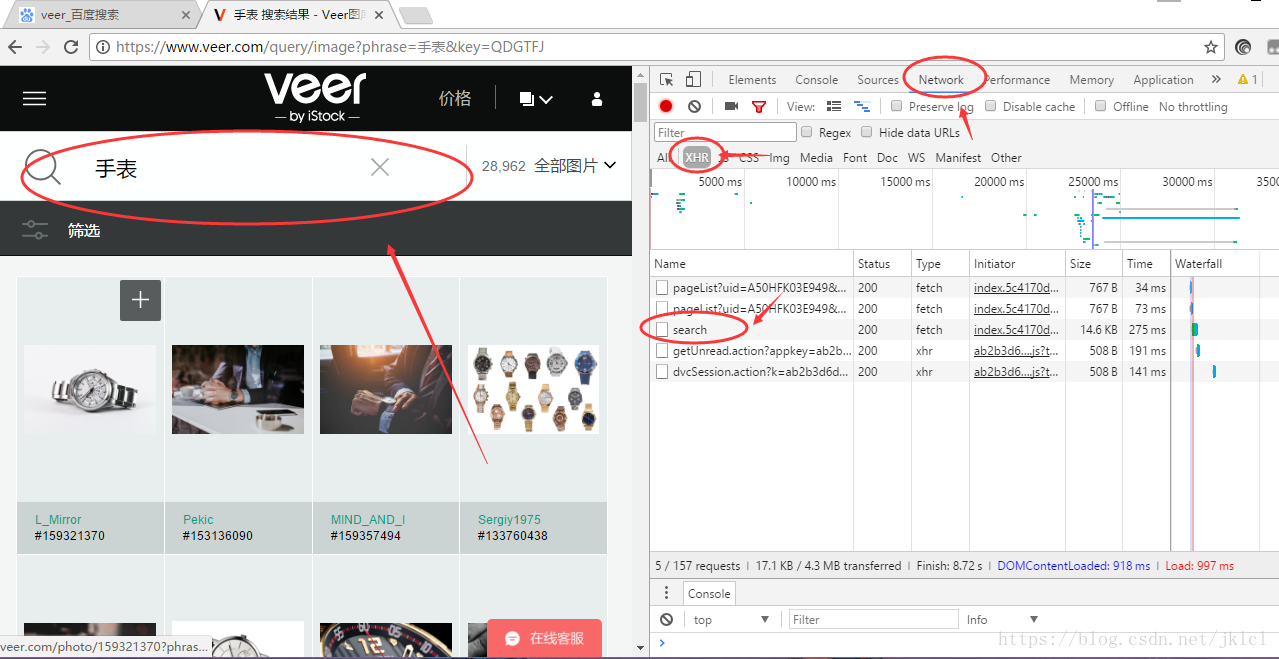
(1)開啟veer首頁,F12(谷歌瀏覽器),輸入關鍵字,點選搜尋,點選檢視如圖畫圈位置
-
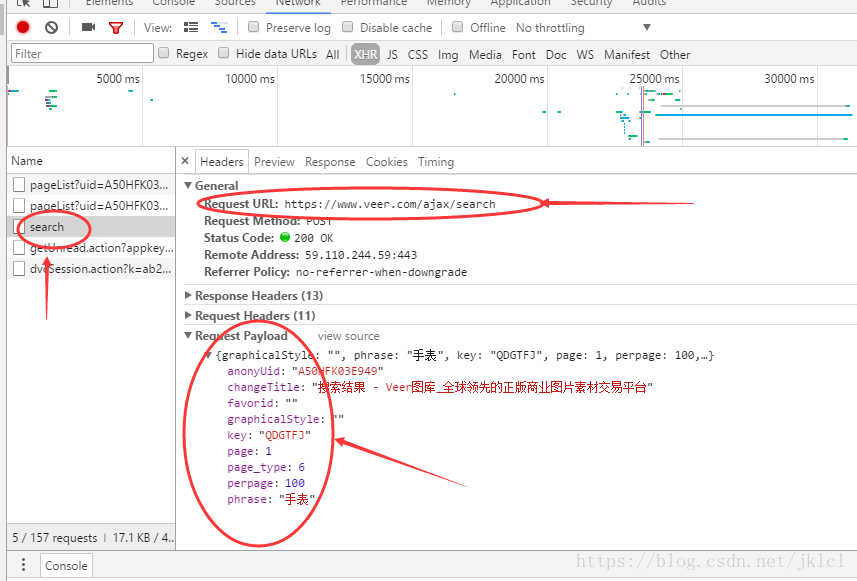
(2)檢視search中的Headers,找到請求的URL和請求的payload,URL是請求的網址,payload是傳送請求時的引數
對於各個詳細的引數在程式碼部分會詳細講
-
(3)檢視響應(請求發出後的返回的資料包),格式是字典格式也就是map,可以看到list中放的id
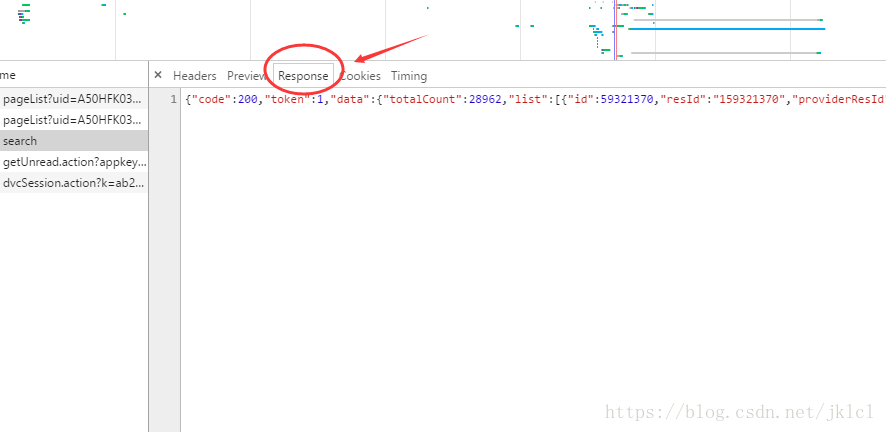
- (4)裡邊有對圖片的中文描述
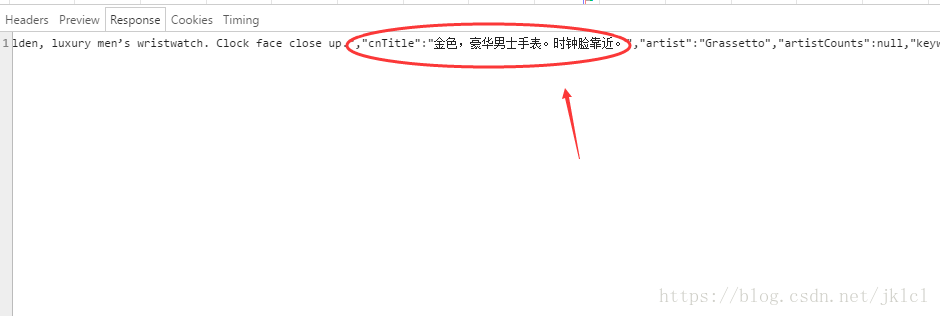
- (5)找到圖片所在網頁
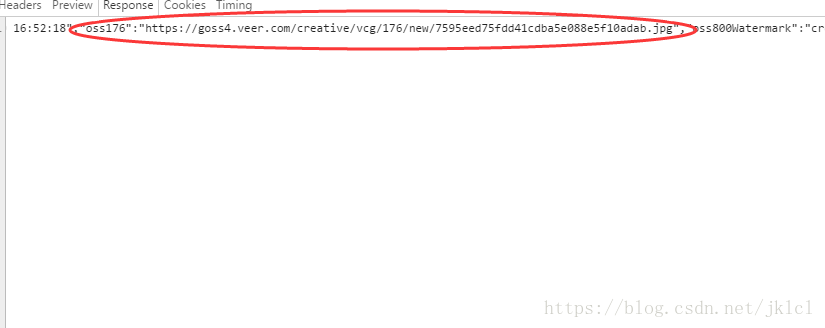
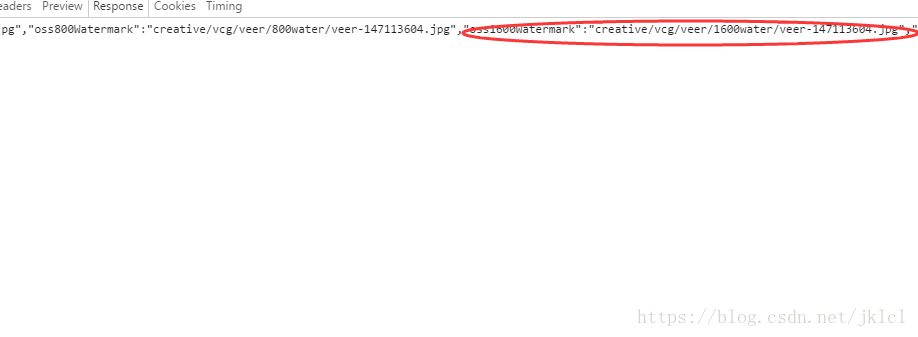
- (6)找到最大尺寸的圖片網址
2、程式碼解析
#conding=utf-8
import requests
import json
def download(img_url, img_name):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:62.0) Gecko/20100101'
}
req = requests.get(img_url, headers=headers)
path = r'F:\newimg'
file_name = 3、效果展示
-
(1)程式執行介面
-
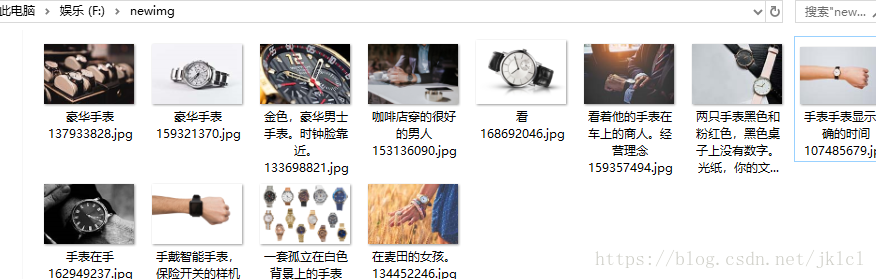
(2)檔案儲存介面