
Python爬蟲框架Scrapy學習一記——認識Scrapy
Preface
(Preface不知道啥意思?!總認識裡面那張臉吧,前+臉,恩,沒錯,前臉的意思)
同志既然你能找到這裡說明你起碼知道Python,知道Python的Scrapy框架,但是你是否瞭解,並且知道用法呢?如果不瞭解,我帶著你咱們走!
申明:本系列部落格成份包含官網重要且常用部分的翻譯、本人的實踐示例與戳圖、還有就是李白的唐詩三百首。好了,我們真的要走了!

1. Scrapy簡介(Scrapy at a glance)
相關可參考文件
-
Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的開源應用框架。 其最初是為了頁面抓取 (更確切來說, 網路抓取 )所設計的, 也可以應用在獲取API所返回的資料(例如 Amazon Associates Web Services ) 或者通用的網路爬蟲。Scrapy用途廣泛,可以用於資料探勘、監測和自動化測試。 Scrapy吸引人的地方在於它是一個框架,任何人都可以根據需求方便的修改。它也提供了多種型別爬蟲的基類,如BaseSpider、sitemap爬蟲等,最新版本又提供了web2.0爬蟲的支援。
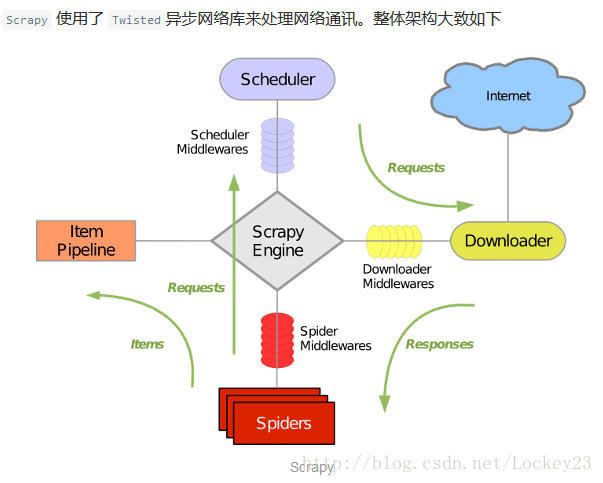
2.Scrapy主要元件:
引擎(Scrapy): 用來處理整個系統的資料流處理, 觸發事務(框架核心)
排程器(Scheduler): 用來接受引擎發過來的請求, 壓入佇列中, 並在引擎再次請求的時候返回. 可以想像成一個URL(抓取網頁的網址或者說是連結)的優先佇列, 由它來決定下一個要抓取的網址是什麼, 同時去除重複的網址
下載器(Downloader): 用於下載網頁內容, 並將網頁內容返回給蜘蛛(Scrapy下載器是建立在twisted這個高效的非同步模型上的)
爬蟲(Spiders): 爬蟲是主要幹活的, 用於從特定的網頁中提取自己需要的資訊, 即所謂的實體(Item)。使用者也可以從中提取出連結,讓Scrapy繼續抓取下一個頁面
專案管道(Pipeline): 負責處理爬蟲從網頁中抽取的實體,主要的功能是持久化實體、驗證實體的有效性、清除不需要的資訊。當頁面被爬蟲解析後,將被髮送到專案管道,並經過幾個特定的次序處理資料。
下載器中介軟體(Downloader Middlewares): 位於Scrapy引擎和下載器之間的框架,主要是處理Scrapy引擎與下載器之間的請求及響應。
爬蟲中介軟體(Spider Middlewares): 介於Scrapy引擎和爬蟲之間的框架,主要工作是處理蜘蛛的響應輸入和請求輸出。
排程中介軟體(Scheduler Middewares): 介於Scrapy引擎和排程之間的中介軟體,從Scrapy引擎傳送到排程的請求和響應。
3.Scrapy執行流程大概如下:
首先,引擎從排程器中取出一個連結(URL)用於接下來的抓取
引擎把URL封裝成一個請求(Request)傳給下載器,下載器把資源下載下來,並封裝成應答包(Response)
然後,爬蟲解析Response
若是解析出實體(Item),則交給實體管道進行進一步的處理。
若是解析出的是連結(URL),則把URL交給Scheduler等待抓取
4. Scrapy提供的特性
- HTML, XML源資料 選擇及提取 的內建支援
- 提供了一系列在spider之間共享的可複用的過濾器(即 Item Loaders),對智慧處理爬取資料提供了內建支援。
- 通過 feed匯出 提供了多格式(JSON、CSV、XML),多儲存後端(FTP、S3、本地檔案系統)的內建支援
- 提供了media pipeline,可以 自動下載 爬取到的資料中的圖片(或者其他資源)。
- 高擴充套件性。您可以通過使用 signals ,設計好的API(中介軟體, extensions, pipelines)來定製實現您的功能。
- 內建的中介軟體及擴充套件為下列功能提供了支援:
- cookies and session 處理
- HTTP 壓縮
- HTTP 認證
- HTTP 快取
- user-agent模擬
- robots.txt
- 爬取深度限制
。。。
- 針對非英語語系中不標準或者錯誤的編碼宣告, 提供了自動檢測以及健壯的編碼支援。
- 支援根據模板生成爬蟲。在加速爬蟲建立的同時,保持在大型專案中的程式碼更為一致。詳細內容請參閱 genspider 命令。
- 針對多爬蟲下效能評估、失敗檢測,提供了可擴充套件的 狀態收集工具 。
- 提供 互動式shell終端 , 為您測試XPath表示式,編寫和除錯爬蟲提供了極大的方便
- 提供 System service, 簡化在生產環境的部署及執行
- 內建 Web service, 使您可以監視及控制您的機器
- 內建 Telnet終端 ,通過在Scrapy程序中鉤入Python終端,使您可以檢視並且除錯爬蟲
- Logging 為您在爬取過程中捕捉錯誤提供了方便
- 支援 Sitemaps 爬取
具有快取的DNS解析器
the end什麼?這就完了?!
要想和我沒完那你先回答4個問題1.Scrapy是什麼? 2.Scrapy主要元件包含哪些,各自有什麼功能? 3.Scrapy執行流程是什麼樣的? 4.Scrapy提供了哪些特性?
好好思考一下我們進入下一節的環境安裝配置
注:本文內容不完全為原創,如有雷同,算我抄你的