
十大機器學習演算法之決策樹(用於信用風險)
演算法原理
Decision Trees (DTs) 是一種用來 和 regression 的無參監督學習方法。其目的是建立一種模型從資料特徵中學習簡單的決策規則來預測一個目標變數的值。決策樹類似於流程圖的樹結構,分支節點表示對一個特徵進行測試,根據測試結果進行分類,樹節點代表一個類別。
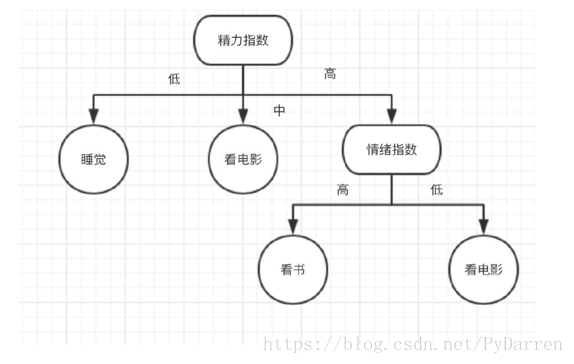
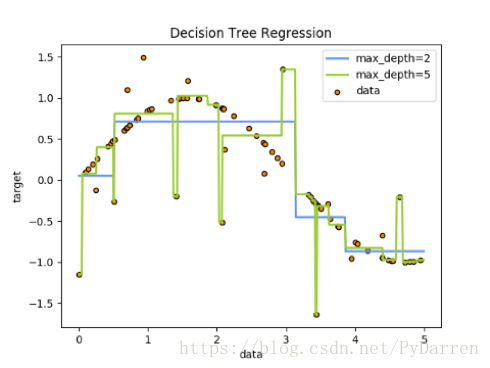
例如,在下面的圖片中,決策樹通過if-then-else的決策規則來學習資料從而估測數一個正弦影象。決策樹越深入,決策規則就越複雜並且對資料的擬合越好。
決策樹的優勢:
- 便於理解和解釋。樹的結構可以可視化出來。訓練需要的資料少。其他機器學習模型通常需要資料規範化,比如構建虛擬變數和移除缺失值,不過請注意,這種模型不支援缺失值。
- 由於訓練決策樹的資料點的數量導致了決策樹的使用開銷呈指數分佈(訓練樹模型的時間複雜度是參與訓練資料點的對數值)。
- 能夠處理數值型資料和分類資料。其他的技術通常只能用來專門分析某一種變數型別的資料集。詳情請參閱演算法。
- 能夠處理多路輸出的問題。
- 使用白盒模型。如果某種給定的情況在該模型中是可以觀察的,那麼就可以輕易的通過布林邏輯來解釋這種情況。相比之下,在黑盒模型中的結果就是很難說明清楚。
- 可以通過數值統計測試來驗證該模型。這對事解釋驗證該模型的可靠性成為可能。
- 即使該模型假設的結果與真實模型所提供的資料有些違反,其表現依舊良好。
決策樹的缺點:
- 決策樹模型容易產生一個過於複雜的模型,這樣的模型對資料的泛化效能會很差。這就是所謂的過擬合.一些策略像剪枝、設定葉節點所需的最小樣本數或設定數的最大深度是避免出現該問題最為有效地方法。
- 決策樹可能是不穩定的,因為資料中的微小變化可能會導致完全不同的樹生成。這個問題可以通過決策樹的整合來得到緩解。
- 在多方面效能最優和簡單化概念的要求下,學習一棵最優決策樹通常是一個NP難問題。因此,實際的決策樹學習演算法是基於啟發式演算法,例如在每個節點進 行區域性最優決策的貪心演算法。這樣的演算法不能保證返回全域性最優決策樹。這個問題可以通過整合學習來訓練多棵決策樹來緩解,這多棵決策樹一般通過對特徵和樣本有放回的隨機取樣來生成。
- 有些概念很難被決策樹學習到,因為決策樹很難清楚的表述這些概念。例如XOR,奇偶或者複用器的問題。
- 如果某些類在問題中占主導地位會使得建立的決策樹有偏差。因此,我們建議在擬合前先對資料集進行平衡。
資訊增益
資訊熵:一條資訊的資訊量和它的不確定性有直接的關係,一個問題不確定性越大,要搞清楚這個問題,需要了解的資訊就越多,其資訊熵也就越大。
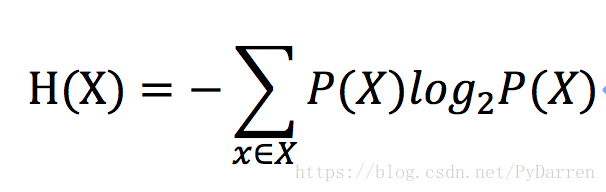
其中P(X)是事件發生的概率。
特徵選擇的依據是:遍歷所有特徵,分別計算,使用這個特徵劃分資料集前後熵的變化值,然後選擇變化值最大(即資訊增益最大)的特徵作為分裂節點,依次類推。
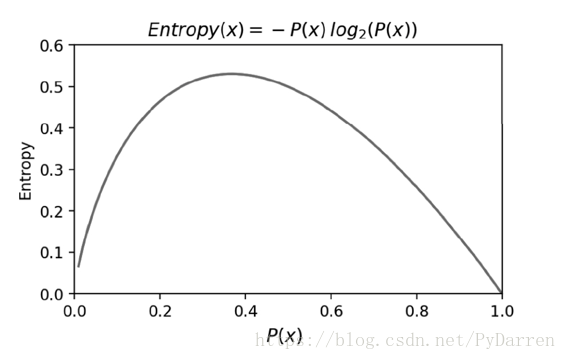
從圖可以看出,當概率P(X)接近於0或者1時,資訊熵的值越小,其不確定性越小,即資料越純,其中為1的時候資訊熵值為0,是最純的。在特徵選擇時,選擇資訊增益最大的特徵,即在物理上讓資料朝著更純淨的方向發展。
決策樹的建立
基本步驟(ID3演算法):
- 計算資料集劃分前的資訊熵;
- 遍歷所有未作為劃分條件的特徵,分別計算根據每個特徵劃分資料集後的資訊熵;
- 選擇資訊增益最大的特徵,利用該特徵作為分支節點來劃分資料;
- 遞迴的處理被劃分後的子資料集,從未被選擇的特徵裡繼續選擇最優分類特徵來劃分子資料集。
- 遞迴終止的條件:
- 沒有新的特徵來進一步劃分資料集;
- 資訊增益足夠小了,需要設定門限值。
幾個注意事項
<1> 離散化
如果特徵是連續型變數,進行離散化後才可以運用決策樹。
<2> 正則項
利用最大化資訊增益的原則來選擇特徵,在決策樹構建的過程中,容易選擇類別最多的特徵來進行分類,比如極端的一種情況——用ID進行分類,毫無意義。
一個解決的辦法是,在計算劃分子集後的資訊熵時,加上一個與類別個數成正比的正則項,來作為最後的資訊熵。這樣,當演算法選擇某個分類較多的特徵,使資訊熵較小時,由於受到類別個數的正則項懲罰,導致最終的資訊熵也比較大,這樣可以通過引數的選擇,達到演算法在訓練時的某種平衡。
另一種方法是通過資訊增益比來作為特徵選擇的標準。
<3> 基尼不純度
資訊熵是衡量資訊不確定性的指標,實際上也是衡量資訊純度的指標。基尼不純度是衡量資訊不純度的指標。研究表明,採用這兩種演算法得到的預測準確率是差不多的,但是採用資訊熵時演算法的效率會低一些,因為裡面有對數運算。
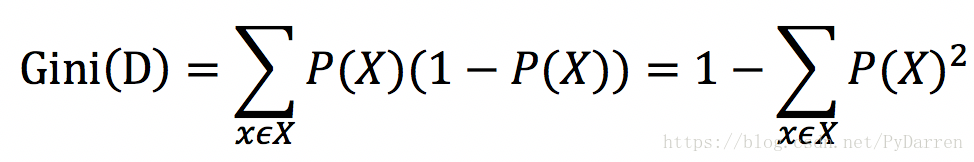
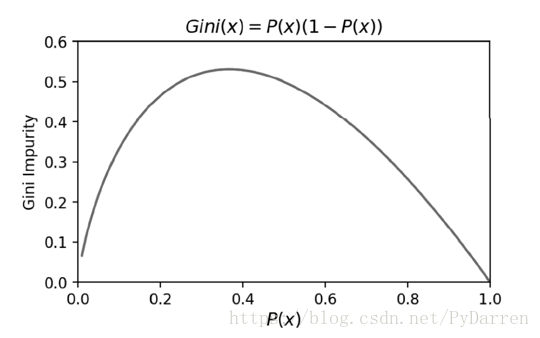
當PX=1時,GiniD=0,即不純度最低,純度最高。CART決策樹是採用基尼不純度作為特徵選擇的一種演算法。
1.4 剪枝演算法
在運用決策樹的過程中,容易造成過擬合,一種解決辦法是進行剪枝處理,分為兩種——前剪枝(Pre-Pruning)和後剪枝(Post-Pruning)。
<1> 前剪枝
前剪枝是在構造決策樹時同時進行剪枝。在決策樹的建立過程中,如果無法進一步降低資訊熵,就停止建立分支。為了避免過擬合,可以設定一個閾值,當資訊增益小於這個閾值時,即使可以進一步降低資訊熵,也會停止建立分支。還有一些簡單的前剪枝方法,如限制葉子節點的樣本數,當樣本數小於閾值時,停止剪枝。
<2> 後剪枝
後剪枝是在決策樹構造完成之後剪枝。過程是對具有相同父節點的一組點進行檢查,判斷如果將其合併,資訊熵的增加量是否小於某一閾值。如果小於該閾值,則這一組節點合併為一個節點。後剪枝是目前最常用的方法,新節點的類別通過多數原則確定,樣本最多的類別作為該節點的類別。
常用的一種後剪枝演算法是降低錯誤率演算法(Reduced-Error Pruning),其思路是,自底向上,從以構建的決策樹中剪去一個子樹,並用剪枝後的根節點作為新的葉子節點,從而得到一個簡化版的決策樹。接著用交叉驗證法來測試新舊決策樹的準確率,保留準確率高的決策樹。遍歷所有子樹,直到針對交叉驗證集無法進一步降低錯誤率為止。
幾種常見演算法:
ID3(Iterative Dichotomiser 3)由 Ross Quinlan 在1986年提出。該演算法建立一個多路樹,找到每個節點(即以貪心的方式)分類特徵,這將產生分類目標的最大資訊增益。決策樹發展到其最大尺寸,然後通常利用剪枝來提高樹對未知資料的泛華能力。
C4.5 是 ID3 的後繼者,並且通過動態定義將連續屬性值分割成一組離散間隔的離散屬性(基於數字變數),消除了特徵必須被明確分類的限制。C4.5 將訓練的樹(即,ID3演算法的輸出)轉換成 if-then 規則的集合。然後評估每個規則的這些準確性,以確定應用它們的順序。如果規則的準確性沒有改變,則需要決策樹的樹枝來解決。
C5.0 是 Quinlan 根據專有許可證釋出的最新版本。它使用更少的記憶體,並建立比 C4.5 更小的規則集,同時更準確。
CART(Classification and Regression Trees (分類和迴歸樹))與 C4.5 非常相似,但它不同之處在於它支援數值目標變數(迴歸),並且不計算規則集。CART 使用在每個節點產生最大資訊增益的特徵和閾值來構造二叉樹。scikit-learn 使用 CART 演算法的優化版本。
# coding: utf-8
# In[2]:
import numpy as np
import pandas as pd
import os,time,datetime
# In[3]:
train_df = pd.read_csv("traindata.csv")
test_df = pd.read_csv("testdata.csv")
# In[4]:
train_df.columns
# In[5]:
X_train = train_df.drop(['Unnamed: 0', 'userId', 'overDued', 'startTime', 'surv'],axis=1).values
y_train = train_df.overDued.values
# In[6]:
X_test = test_df.drop(['Unnamed: 0', 'userId', 'overDued', 'startTime', 'surv'],axis=1).values
y_test = test_df.overDued.values
# In[7]:
from sklearn.tree import DecisionTreeClassifier
# In[8]:
dtc = DecisionTreeClassifier()
# In[9]:
dtc.fit(X_train, y_train)
# In[10]:
dtc.score(X_train, y_train)
# In[11]:
dtc.score(X_test, y_test)
# In[12]:
test_y_predict = dtc.predict(X_test)
# In[13]:
from sklearn.metrics import classification_report
# In[14]:
print(classification_report(y_test, test_y_predict, target_names=['no default', 'default']))
# In[22]:
####優化模型引數
#max_depth決定模型的深度,當到達深度時不再進行分裂
def cv_score(d):
dtc = DecisionTreeClassifier(max_depth=d)
dtc.fit(X_train, y_train)
# train_score = dtc.score(X_train,y_train)
# cv_score = dtc.score(X_test,y_test)
# return (train_score,cv_score)
test_y_predict = dtc.predict(X_test)
print(classification_report(y_test, test_y_predict, target_names=['no default', 'default']))
print('*' * 100)
# In[23]:
depths = range(2,15)
# score_list = [cv_score(d) for d in depths]
# train_score_list = [s[0] for s in score_list]
# cv_score_list = [s[1] for s in score_list]
# In[24]:
for d in depths:
cv_score(d)
precision recall f1-score support
no default 1.00 0.89 0.94 12137
default 0.32 0.99 0.48 643
avg / total 0.97 0.89 0.92 12780
****************************************************************************************************
precision recall f1-score support
no default 1.00 0.92 0.96 12137
default 0.40 0.97 0.57 643
avg / total 0.97 0.93 0.94 12780
****************************************************************************************************
precision recall f1-score support
no default 1.00 0.91 0.95 12137
default 0.37 0.98 0.54 643
avg / total 0.97 0.92 0.93 12780
****************************************************************************************************
precision recall f1-score support
no default 1.00 0.92 0.96 12137
default 0.39 0.98 0.56 643
avg / total 0.97 0.92 0.94 12780
****************************************************************************************************
precision recall f1-score support
no default 1.00 0.92 0.96 12137
default 0.40 0.97 0.56 643
avg / total 0.97 0.92 0.94 12780
****************************************************************************************************
precision recall f1-score support
no default 1.00 0.92 0.96 12137
default 0.40 0.97 0.57 643
avg / total 0.97 0.93 0.94 12780
****************************************************************************************************
precision recall f1-score support
no default 1.00 0.93 0.96 12137
default 0.41 0.95 0.58 643
avg / total 0.97 0.93 0.94 12780
****************************************************************************************************
precision recall f1-score support
no default 1.00 0.94 0.97 12137
default 0.44 0.92 0.59 643
avg / total 0.97 0.94 0.95 12780
****************************************************************************************************
precision recall f1-score support
no default 0.99 0.94 0.97 12137
default 0.44 0.91 0.60 643
avg / total 0.97 0.94 0.95 12780
****************************************************************************************************
precision recall f1-score support
no default 0.99 0.94 0.97 12137
default 0.46 0.89 0.60 643
avg / total 0.97 0.94 0.95 12780
****************************************************************************************************
precision recall f1-score support
no default 0.99 0.95 0.97 12137
default 0.47 0.86 0.61 643
avg / total 0.97 0.94 0.95 12780
****************************************************************************************************
precision recall f1-score support
no default 0.99 0.95 0.97 12137
default 0.47 0.83 0.60 643
avg / total 0.96 0.94 0.95 12780
****************************************************************************************************
precision recall f1-score support
no default 0.99 0.95 0.97 12137
default 0.49 0.81 0.61 643
avg / total 0.96 0.95 0.95 12780
****************************************************************************************************