
機器學習十大經典演算法之決策樹(學習筆記整理)
一、決策樹概述
決策樹是一種樹形結構,其中每個內部節點表示一個屬性上的測試,每個分支代表一個測試輸出,每個葉節點代表一種類別。決策樹是一個預測模型,代表的是物件屬性與物件值之間的一種對映關係。
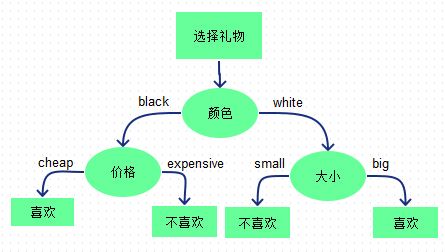 最初的節點稱為根節點(如圖中的"顏色"),有分支的節點稱為中間節點(如圖中的"價格"),無分支的節點稱為葉節點(如圖中的"喜歡")
最初的節點稱為根節點(如圖中的"顏色"),有分支的節點稱為中間節點(如圖中的"價格"),無分支的節點稱為葉節點(如圖中的"喜歡")
優點:計算複雜度不高,輸出結果容易理解,對中間值的缺失不敏感,可以處理不相關特徵資料 缺點:可能產生過擬合問題 適用資料型別:數值型和標稱型
二、節點變數的選擇
應該選擇哪些變數作為根節點或中間節點生成決策樹,目前主流的有三種方法。
1.ID3演算法
(1) 資訊的定義: 事件的不確定性越大,則其資訊越多其中xi是某一事件的第i個可能值,P(xi)為其概率。 (2) 資訊熵的定義: 資訊熵為資訊的數學期望某一事件有K個值,pk表示第k個值發生的概率。 實際應用中可以用頻率替換實際概率pk其中|D|表示事件中的所有樣本點,|Ck|表示事件的第k個可能值出現的次數。 (3) 條件熵: 其中P(Ai)為事件A第i種值對應的概率,P(Dk|Ai)為已知Ai的情況下D事件為第k種值的概率,即條件概率。 以頻率代替概率: 其中|Di|為Ai的頻數,|Dik|為Ai下D事件為第k種值的頻數。 (4) 資訊增益: 事件A對事件D的影響越大,則其條件熵H(D|A)就會越小,資訊增益就越大。根節點或中間節點變數的選擇,就是選擇使因變數的資訊增益最大的自變數。
2.C4.5演算法
ID3演算法資訊增益會偏向於取值較多的變數,極端例子如果一個變數的取值正好是N個,則其熵會等於0,在該變數下因變數的資訊增益一定是最大的,為了克服這種缺點,C4.5演算法使用資訊增益率對根節點或中間節點進行選擇。 其中HA為事件A的資訊熵。時間A的取值越多,資訊增益GainA(D)可能越大,但同時HA也會越大,這樣就以商的形式實現了對資訊增益的懲罰。
3.CART演算法
ID3和C4.5只能對離散型因變數進行分類,而CART可以處理連續型因變數。CART演算法以基尼指數對根節點或中間節點進行選擇。Python的sklearn模組使用的便是CART演算法。 其中pk為事件第k個可能值發生的概率。 以頻率代替實際概率: 條件基尼指數
三、決策樹的剪枝
無論是用ID3、C4.5還是CART生成的決策樹,都可能存在過擬合的問題,因此經常需要對決策樹進行剪枝。
預剪枝
預剪枝是在樹的生長過程中就對其進行必要的剪枝,如限制樹的最大深度、限制中間節點和葉節點所包含的最小樣本量、限制生成的最多葉節點數量等。
後剪枝
後剪枝是在樹充分生長後再對其返工剪枝。
1.誤差降低剪枝法(Reduced-Error Pruning, REP)
將某一非葉節點的子孫節點刪除,使其變為新的葉節點。新葉節點的類別確定是利用該節點剪枝前包含的所有葉節點投票,頻數最高的類別作為新的類別。利用測試集的資料對比剪枝前後的誤判樣本量,如果新樹的誤判樣本量少於老樹,則可以剪枝,否則不可剪枝。重複此步驟直到達到最大的預測準確率。由於使用測試集,該方法可能導致剪枝過度。
2.悲觀剪枝法(Pessimistic Error Pruning, PEP)
自上向下的剪枝會增加誤判率,因此對葉節點的誤判個數增加一個經驗性的懲罰係數0.5。 剪枝後的誤判率:剪枝前的誤判率: