
【深度學習】---行人檢測應用
行人檢測綜述
涉及論文
主要圍繞王曉剛的幾篇關於深度學習在行人檢測的應用。
Ouyang, W. and X. Wang (2013). “Joint Deep Learning for Pedestrian Detection.” 2056-2063.*
Ouyang, W. and X. Wang (2012). A discriminative deep model for pedestrian detection with occlusion handling. Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on, IEEE.Ouyang, W. and X. Wang (2013). Single-pedestrian detection aided by multi-pedestrian detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
Walk, S., et al. (2010).New features and insights for pedestrian detection. Computer vision and pattern recognition (CVPR), 2010 IEEE conference on, IEEE.
Zeng, X., et al. (2013). “Multi-stage Contextual Deep Learning for Pedestrian Detection.” 121-128.
主要思路
利用深度學習的方法解決行人檢測的Feature extraction, deformation handling, occlusion handling, and classification四個問題進行聯合學習的思想,尤其處理occlusion handling遮擋的問題花費的篇幅比較多。
本次筆記主要圍繞Joint Deep Learning for Pedestrian Detection這篇文章來進行討論,其他幾篇文章屬於其前驅文章,有借鑑內容會詳細說。
論文討論
論文原文
摘要
特徵提取、形變處理、遮擋處理、分類是四個行人檢測中的重要部分。目前的方法一般都是把這四個部分孤立起來處理,本文的思路是將這四部分聯合來學習,來發揮他們之間協同的最大作用。本文將這四部分在一個深度模型中進行學習,並且在幾個資料集上進行測試得到的結果在漏檢上提高了9%的概率。
Contributions
1.將四個主要部分聯合學習,利用這個深度模型,這幾個部分協同作用使得每部分發揮更大作用。
2.我們通過在cnn加入形變層層(deformation layer)來豐富了深度模型,使得許多形變處理可以依賴於我們的深度模型。
3.特徵是通過形變處理和遮擋處理兩個部分協同下的畫素得到,由此可以得到更多不同的特徵。
核心內容
深度模型概要
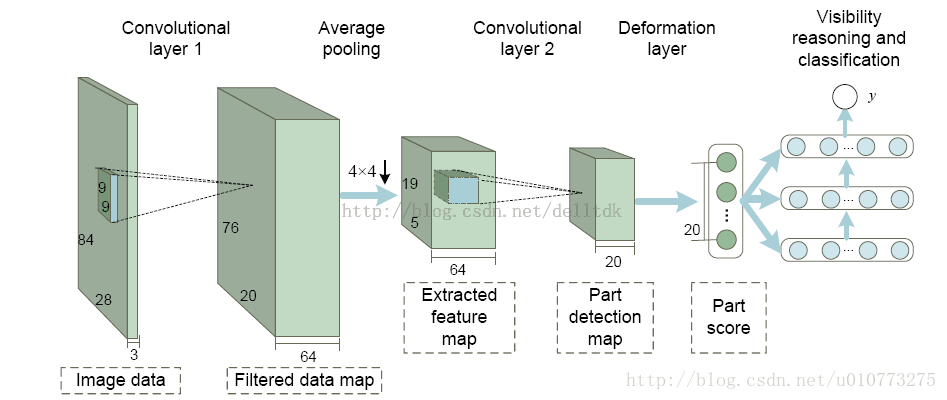
圖 1 網路結構圖
主要用CNN+Part Detection+Deformation Model+Visibility reasoning構建神經網路,但是前端需要預檢測,本文作者採用的之前的一篇文章的方法進行預處理,得出candidate window(HOG+CSS+SVM基本方法),然後後面用的本網路進行檢測,主要結構如圖 1。
(注:CSS特徵出自
https://wenku.baidu.com/view/612db676302b3169a45177232f60ddccdb38e674)
大致流程如下:
1.以修改過的YUV特徵和map作為輸出
2.一個卷積層(應該是看成root)
3.又一個卷積層(引入不同大小的卷積核,帶有part資訊)
4.處理deformable的一個層
5.處理occlusion的層,並得到最後結果
輸入層雖然是3channel,但卻不是直接的RGB或者YUV等等三通道圖,而是經過預處理階段之後的。第一個map是原圖的Y通道,第二個map被均分為四個block,分別是 U通道,V通道,Y通道和全0,見下圖2a;第三個map是sobel運算元計算的第二個map的邊緣,不同的是第四個block是前面三個block的邊緣的最大值,如圖 2。(注意,最終每個map都要歸一到零均值-單位方差的分佈)。

圖 2輸入層的第二、第三層map
構建部分檢測map(part detection map)
本文建立了三個等級的部分map,具體如圖 3,每個等級由身體的部分大小分類,高等級部分又低等級部分組成。用這20個大小不同的part卷積核與detection map進行處理,然後得到20個part的帶檢測map。
從這裡面得到的model要比HOG特徵得到的結果更細緻。
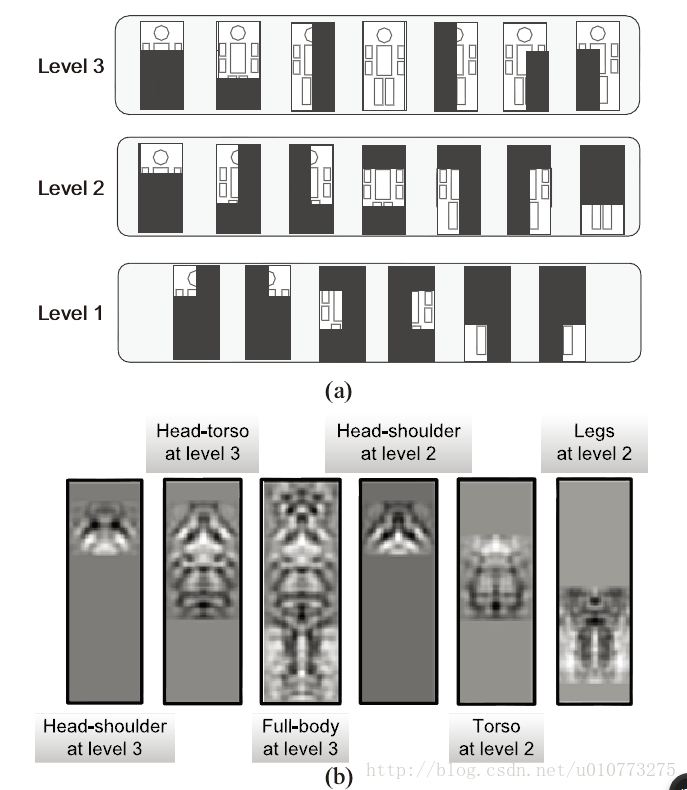
圖 3(a)部分模型(b)第二層卷基層學習的部分模型
形變層(deformation layer)
為了得到不同部分的約束,我們為cnn添加了形變處理層。感覺上這部分是這個論文對行人檢測的關鍵貢獻吧。
輸入為P部分detection map,輸出為P部分的得分s = {s1, … , sP },由圖 1得到P為20個。
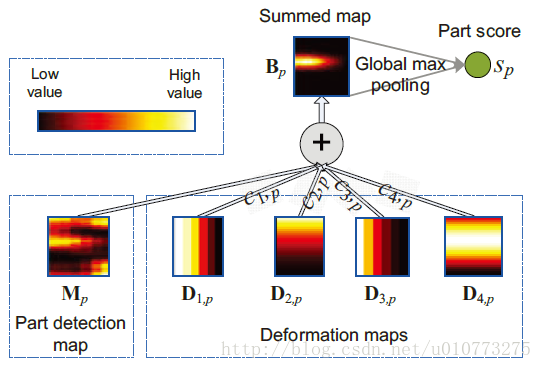
圖 4得分系統和最終得分,其中B_p是得到的和結果,
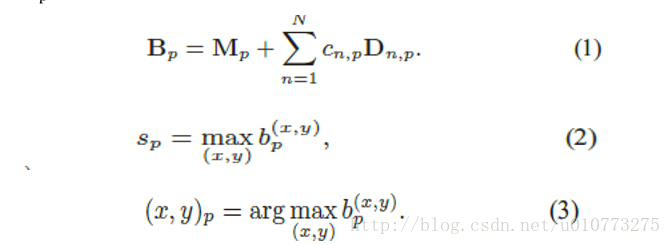
(1)式中的c_(n,p) D_(n,p)是建立模型的關鍵,是需要學習的引數。然後進行融合得到一張deformation part的map(summed map),之後求全圖得到max就為part的得分。
文中舉了三種特殊情況的例子,主要是圍繞著代價來討論的,然後用到了
其他兩篇文章的處理辦法,貌似是區域形變和二次約束之類的方法,那兩篇文章大概翻了一下沒有看懂,這部分就沒有細看。
可見性根據和分類器
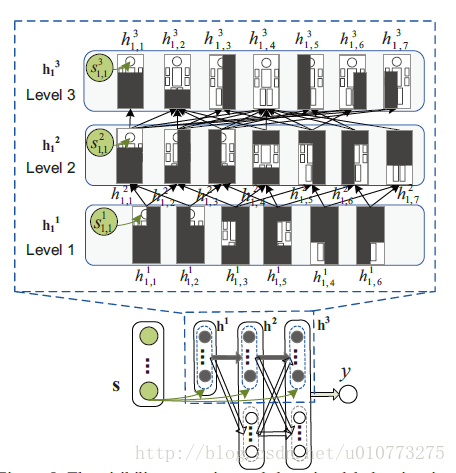
圖 5 DBN網路層
每個部分可以有不止一個父節點,和子節點。基於本網路,一個節點的可視性可以看做是與同層其他節點存在相關性的(通過他們之間的父節點)。
很多的文章的方法也是進行每部分的評分然後進行得到最終的結論,但是每個部分之間的相關性沒有被開發,本文就是利用深度模型學習出每部分模型的相關性的。
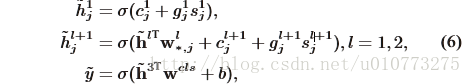
其中 σ是sigmoid函式,g是s的權重,c是偏置項。W塑造了h在l與l+1層之間的聯絡。g,h,w,b是需要學習的引數。
本文對上述引用論文的網路改進主要有下面兩個方面:
1.在第1層和第2層的資訊需要通過第3層傳給分類器,但是第3層的不好的樣本不會影響到之前層的資訊,於是在第2層和第3層中間加了一些隱藏節點,來幫助第1,第2層來直接傳導資訊到分類器,而不會被其他的部分影響。隱藏節點不採用之前的detection的分數,並且在g_j^(l+1) s_j^(l+1)=0,在圖 5中是用白圈代表,而g_j^(l+1) s_j^(l+1)≠0的用灰圈表示。
2.(*)原來的網路只是通過部分的分數來學習了可視之間的聯絡(visiblity relationship),HOG特徵和形變處理的參量都是固定的。本文中形變模型,可視聯絡都是通過聯合學習的,為了學習兩個卷基層的引數和形變層的引數,利用反向傳導來求得預測誤差。
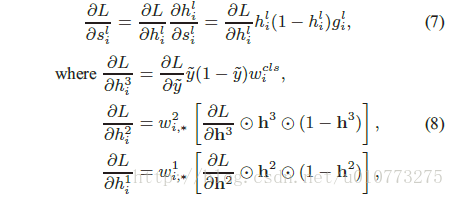
其中 為hadamard積, 具體就不是太懂了。L是損失函式。
為了訓練這個深度模型,我們提出了一種多級訓練策略,開始時採用監督學習訓練一層cnn,因為Gabor濾波器和人類視覺系統比較相似,用來初始化最初的cnn,我們在每一級新增一層,前一級得到的結果來初始化下一層。層層學習得到最終結果,然後BP演算法調整。
總結
本文主要著眼於將行人檢測中的重要的四部分工作進行聯合學習。把他們聯絡在一起可以獲得之間比較好的相關性,然後得到更準確的檢測。
但是論文的預處理還是要進行candidate window的獲得,也就是說之前的核心檢測還是沒有發生本質的變化,而是在原來現有的演算法的基礎上進行了一個增加的深度學習的方法來進行確認,從而提高檢測的成功率。