
邏輯斯蒂迴歸原理
1.邏輯斯蒂迴歸模型
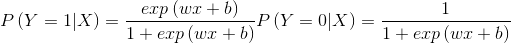
LR模型主要用於分類模型,細心的人不難發現LR模型線上性迴歸模型上加了一個sigmoid轉換。為了更加深入地瞭解這個模型,我們可能要思考以下幾個問題
(1)sigmoid從何而來,篇幅比較大,下面會單獨討論
(2)sigmoid轉換的優勢
- 求梯度方便
- 資料統一分佈在0-1之間,從下面的LR分佈也可以看出
(3)這種轉換需要注意的地方,LR分佈可以此種轉換的特徵
2.邏輯斯蒂迴歸分佈
分佈函式
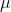
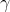
密度函式
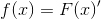
邏輯斯蒂迴歸分佈的密度函式和分佈函式

不難看出,F(x)曲線在中心附近增長速度比較快,在兩端增長速度較慢。形狀引數
3.模型引數估計
應用極大似然估計法估計模型
(1)設
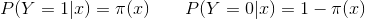
(2)似然函式
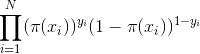
(3)對數似然函式
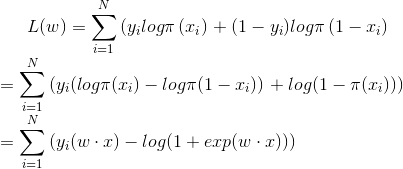
(4)梯度下降
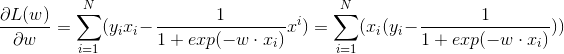
最後括號中表達式就是訓練時的誤差,從而我們可以通過batch等方法進行隨機梯度下降
4.sigmoid
定義表示式
A(u,v):如果u == v,則A(u,v) = 1 ,否則為0 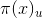
滿足條件
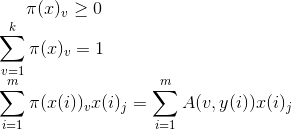
第三個條件可以簡單的從頻率學派和貝葉斯學派理解
優化目標(拉格朗日)
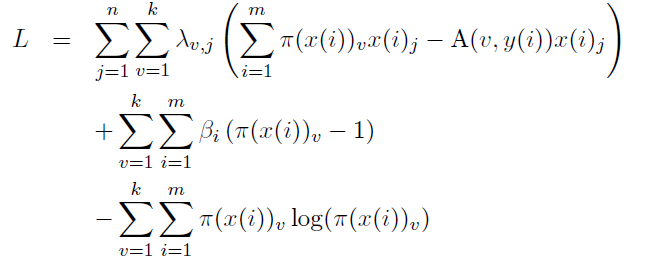
求梯度 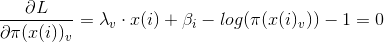
最終可以得到
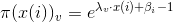
對於分類問題,我們最終要確保每個類別概率之和為1 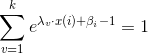
因此
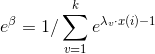
通過化簡可得
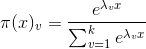
5.在二分類問題中,為什麼棄用傳統的線性迴歸模型,改用邏輯斯蒂迴歸?
線性迴歸用於二分類時,首先想到下面這種形式,p是屬於類別的概率:
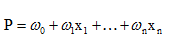
但是這時存在的問題是:
1)等式兩邊的取值範圍不同,右邊是負無窮到正無窮,左邊是[0,1],這個分類模型的存在問題
2)實際中的很多問題,都是當x很小或很大時,對於因變數P的影響很小,當x達到中間某個閾值時,影響很大。即實際中很多問題,概率P與自變數並不是直線關係。
所以,上面這分類模型需要修整,怎麼修正呢?統計學家們找到的一種方法是通過logit變換對因變數加以變換,
具體如下:
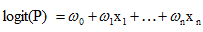
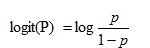
從而,
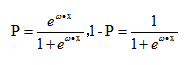
這裡的P完全解決了上面的兩個問題。
6.從最根本的廣義線性模型角度,匯出經典邏輯迴歸
1)指數家族
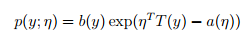
當固定T時,這個分佈屬於指數家族中的哪種分佈就由a和b兩個函式決定。下面這種是伯努利分佈,對應於邏輯迴歸問題
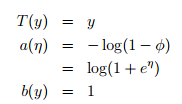
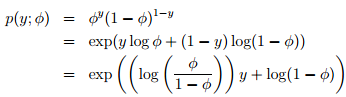
注:從上面可知
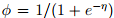
下面這種是高斯分佈,對應於經典線性迴歸問題
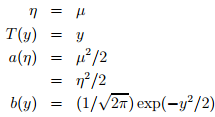
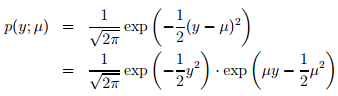
2)GLM(廣義線性模型)
指數家族的問題可以通過廣義線性模型來解決。如何構建GLM呢?在給定x和引數後,y的條件概率p(y|x,θ) 需要滿足下面三個假設:
assum1) y | x; θ ∼ ExponentialFamily(η).
assum2) h(x) = E[y|x]. 即給定x,目標是預測T(y)的期望,通常問題中T(y)=y
assum3) η = θTx,即η和x之間是線性的
3)經典邏輯迴歸
邏輯迴歸:以二分類為例,預測值y是二值的{1,0},假設給定x和引數,y的概率分佈服從伯努利分佈(對應構建GLM的第一條假設)。由上面高斯分佈和指數家族分佈的對應關係可知,,根據構建GLM的第2、3條假設可model表示成:
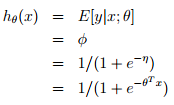
可以從GLM這種角度理解為什麼logistic regression的公式是這個形式~
7.例項
二分類問題,分類邊界實乃重中之重。訓練樣本是否均衡、樣本權重都會對邊界有影響
C1、C2為類別,圖片引用於PRML
瞭解下Fisher判別函式對理解分類問題本質會有很大幫助

8.多項邏輯斯蒂迴歸
假設離散型隨機變數Y的取值集合是{1,2…,K},那麼多項邏輯斯蒂迴歸模型是
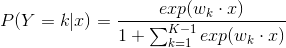
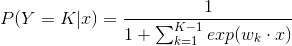
類似於CNN分類最後一層softmax
9.Tips
- 訓練速度快
- 資料量比較少的時候容易過擬合,這與使用極大似然估計(本質上為均值)是有關的
- 特徵One-hot
- 設計組合特徵
- 進行多分類的時候,思考下不同label之間是否有關係,從而覺得到底使用多個二分類還是一個多分類
參考文獻 : 統計學習方法
邏輯迴歸原理,雖然叫做“迴歸”,但是這個演算法是用來解決分類問題的。迴歸與分類的區別在於:迴歸所預測的目標量的取值是連續的(例如房屋的價格);而分類所預測的目標變數的取值是離散的(例如判斷郵件是否為垃圾郵件)。當然,為了便於理解,我們從二值分類(binary classification)開始,在這類分類問題中,y只能取0或1。更好的理解問題,先舉個小例子:假如我們要製作一個垃圾郵件過濾系統,如果一封郵件是垃圾系統,y=1,否則y=0 。給定訓練樣本集,當然它們的特徵和label都已知,我們就是要訓練一個分類器,將它們分開。
迴歸分析用來描述自變數x和因變數Y之間的關係,或者說自變數X對因變數Y的影響程度,並對因變數Y進行預測。其中因變數是我們希望獲得的結果,自變數是影響結果的潛在因素,自變數可以有一個,也可以有多個。一個自變數的叫做一元迴歸分析,超過一個自變數的叫做多元迴歸分析。下面是一組廣告費用和曝光次數的資料,費用和曝光次數一一對應。其中曝光次數是我們希望知道的結果,費用是影響曝光次數的因素,我們將費用設定為自變數X,將曝光次數設定為因變數Y,通過一元線性迴歸方程和判定係數可以發現費用(X)對曝光次數(Y)的影響。
1、 邏輯迴歸模型
迴歸是一種極易理解的模型,就相當於y=f(x),表明自變數x與因變數y的關係。最常見問題有如醫生治病時的望、聞、問、切,之後判定病人是否生病或生了什麼病,其中的望聞問切就是獲取自變數x,即特徵資料,判斷是否生病就相當於獲取因變數y,即預測分類。
最簡單的迴歸是線性迴歸,在此借用Andrew NG的講義,有如圖1.a所示,X為資料點——腫瘤的大小,Y為觀測值——是否是惡性腫瘤。通過構建線性迴歸模型,如hθ(x)所示,構建線性迴歸模型後,即可以根據腫瘤大小,預測是否為惡性腫瘤hθ(x)≥.05為惡性,hθ(x)<0.5為良性。

圖1 線性迴歸示例
然而線性迴歸的魯棒性很差,例如在圖1.b的資料集上建立迴歸,因最右邊噪點的存在,使迴歸模型在訓練集上表現都很差。這主要是由於線性迴歸在整個實數域內敏感度一致,而分類範圍,需要在[0,1]。邏輯迴歸就是一種減小預測範圍,將預測值限定為[0,1]間的一種迴歸模型,其迴歸方程與迴歸曲線如圖2所示。邏輯曲線在z=0時,十分敏感,在z>>0或z<<0處,都不敏感,將預測值限定為(0,1)。

圖2 邏輯方程與邏輯曲線
邏輯迴歸其實僅為線上性迴歸的基礎上,套用了一個邏輯函式,但也就由於這個邏輯函式,邏輯迴歸成為了機器學習領域一顆耀眼的明星,更是計算廣告學的核心。對於多元邏輯迴歸,可用如下公式似合分類,其中公式(4)的變換,將在邏輯迴歸模型引數估計時,化簡公式帶來很多益處,y={0,1}為分類結果。
對於訓練資料集,特徵資料x={x1, x2, … , xm}和對應的分類資料y={y1, y2, … , ym}。構建邏輯迴歸模型f(θ),最典型的構建方法便是應用極大似然估計。首先,對於單個樣本,其後驗概率為:

那麼,極大似然函式為:
 log似然是:
log似然是:

2、 梯度下降
由第1節可知,求邏輯迴歸模型f(θ),等價於:

採用梯度下降法:

從而迭代θ至收斂即可:

2.1 梯度下降演算法
梯度下降演算法的虛擬碼如下:
################################################
初始化迴歸係數為1
重複下面步驟直到收斂{
計算整個資料集的梯度
使用alpha x gradient來更新迴歸係數
}
返回迴歸係數值
################################################
注:因為本文中是求解的Logit迴歸的代價函式是似然函式,需要最大化似然函式。所以我們要用的是梯度上升演算法。但因為其和梯度下降的原理是一樣的,只是一個是找最大值,一個是找最小值。找最大值的方向就是梯度的方向,最小值的方向就是梯度的負方向。不影響我們的說明,所以當時自己就忘了改過來了,謝謝評論下面@wxltt的指出。另外,最大似然可以通過取負對數,轉化為求最小值。程式碼裡面的註釋也是有誤的,寫的程式碼是梯度上升,登出成了梯度下降,對大家造成的不便,希望大家海涵。
2.2 隨機梯度下降SGD (stochastic gradient descent)
梯度下降演算法在每次更新迴歸係數的時候都需要遍歷整個資料集(計算整個資料集的迴歸誤差),該方法對小資料集尚可。但當遇到有數十億樣本和成千上萬的特徵時,就有點力不從心了,它的計算複雜度太高。改進的方法是一次僅用一個樣本點(的迴歸誤差)來更新迴歸係數。這個方法叫隨機梯度下降演算法。由於可以在新的樣本到來的時候對分類器進行增量的更新(假設我們已經在資料庫A上訓練好一個分類器h了,那新來一個樣本x。對非增量學習演算法來說,我們需要把x和資料庫A混在一起,組成新的資料庫B,再重新訓練新的分類器。但對增量學習演算法,我們只需要用新樣本x來更新已有分類器h的引數即可),所以它屬於線上學習演算法。與線上學習相對應,一次處理整個資料集的叫“批處理”。
隨機梯度下降演算法的虛擬碼如下:
###############################################
初始化迴歸係數為1
重複下面步驟直到收斂{
對資料集中每個樣本
計算該樣本的梯度
使用alpha xgradient來更新迴歸係數
}
返回迴歸係數值
###############################################
2.3 改進的隨機梯度下降
1)在每次迭代時,調整更新步長alpha的值。隨著迭代的進行,alpha越來越小,這會緩解係數的高頻波動(也就是每次迭代係數改變得太大,跳的跨度太大)。當然了,為了避免alpha隨著迭代不斷減小到接近於0(這時候,係數幾乎沒有調整,那麼迭代也沒有意義了),我們約束alpha一定大於一個稍微大點的常數項,具體見程式碼。
2)每次迭代,改變樣本的優化順序。也就是隨機選擇樣本來更新迴歸係數。這樣做可以減少週期性的波動,因為樣本順序的改變,使得每次迭代不再形成周期性。
改進的隨機梯度下降演算法的虛擬碼如下:
################################################
初始化迴歸係數為1
重複下面步驟直到收斂{
對隨機遍歷的資料集中的每個樣本
隨著迭代的逐漸進行,減小alpha的值
計算該樣本的梯度
使用alpha x gradient來更新迴歸係數
}
返回迴歸係數值
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.linear_model import LogisticRegression
# 構造一些資料點
centers = [[-5, 0], [0, 1.5], [5, -1]]
X, y = make_blobs(n_samples=1000, centers=centers, random_state=40)
transformation = [[0.4, 0.2], [-0.4, 1.2]]
X = np.dot(X, transformation)
clf = LogisticRegression(solver='sag', max_iter=100, random_state=42).fit(X, y)
print (clf.coef_ )
print (clf.intercept_)
'''
[[-4.41615534 -2.23077034]
[-0.36796618 1.64022091]
[ 4.7027708 0.18133443]]
[-4.61020975 -1.91396323 -4.17213317]
'''