
大資料系列之分散式釋出訂閱訊息系統Kafka(一)Kafka簡介,組成,叢集安裝
1.Kafka簡介
Kafka如同JMS(Java Message Service)一樣,是一箇中間件,在異構系統間通訊,為不同的系統之間提供服務。我們知道JMS通過佇列(一對一)與主題(一對多)兩種形式提供服務,而Kafka則通過主題(topic),來給一組消費者提供服務,但是這一組消費者中只能有一個消費者消費,這樣就將JMS的佇列與主題提供的服務整合在一起(一對一:針對一組消費者裡的一個消費者,一對多:針對多組消費者)。
Kafka是由Apache軟體基金會開發的一個開源流處理平臺,由Scala和Java編寫。Kafka是一種高吞吐量的分散式釋出訂閱訊息系統,它可以處理消費者規模的網站中的所有動作流資料。 這種動作(網頁瀏覽,搜尋和其他使用者的行動)是在現代網路上的許多社會功能的一個關鍵因素。 這些資料通常是由於吞吐量的要求而通過處理日誌和日誌聚合來解決。 對於像
Kafka是一個分散式流處理平臺,在不同的系統之間構建實時的資料流通管道。以主題(topic)分類對記錄進行儲存。每個記錄包含key-value+timestamp,每秒鐘百萬訊息吞吐量。
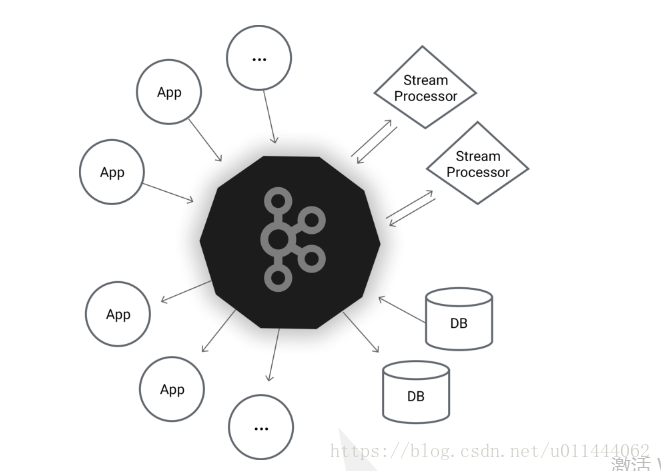
2.Kafka組成
producer //訊息生產者
consumer //訊息消費者
consumer group //消費者組
kafka server //broker,kafka伺服器
topic //主題
zookeeper //系統服務
3..Kafka叢集安裝
0.選擇s10 ~ s12三臺主機安裝kafka
1.準備zk(之前已經配置)
略
2.jdk(之前已經配置)
略
3.tar檔案
tar -zxvf kafka_2.11-0.10.2.1
建立符號連結: ln -s kafka_2.11-0.10.2.1 kafka
4.環境變數[/etc/profile]
#kafka
export KAFKA_HOME=/home/zpx/soft/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
5.配置kafka
[kafka/config/server.properties]
...
broker.id=10
...
listeners=PLAINTEXT://:9092
...
log.dirs=/home/zpx/kafka/logs
...
zookeeper.connect=s10:2181,s11:2181,s12:2181
6.分發server.properties到所有的主機節點上,同時修改每個檔案的broker.id(我設定3個數值是10,11,12)
7.啟動kafka伺服器
a)先啟動zk
b)啟動kafka(前提是已經開啟zookeeper)
[s10 ~ s12]
如下啟動之後會阻塞
$>bin/kafka-server-start.sh config/server.properties
建議使用如下方式,在後臺執行:
$> kafka-server-start.sh -daemon ../config/server.properties
c)驗證kafka伺服器是否啟動
$>netstat -anop | grep 9092

軟體包:
連結:https://pan.baidu.com/s/1SJC_huvlp1_4bHHiBse8jA 密碼:nsv5