【深度學習】python用RNN中LSTM進行正弦函式擬合
阿新 • • 發佈:2019-01-22
深度學習框架:Tensorflow 0.8.0
Python:2.7.6
資料的兩種輸入模型:
①data和label是同一個變數,整個模型相當於自迴歸(本文先演示第一種)
②data和label是不同的變數,整個模型相當於尋找data和label的函式關係
生成資料類:
class BatchGenerator:
def __init__(self,window_size,window_range):
self.cursor=0.
self.window=window_size
self.range=window_range
def 一層的LSTM網路搭建:
with graph.as_default():
#引數初始化
#input gate
ix=tf.Variable(tf.truncated_normal([window_size-1,num_nodes],-0.1,0.1),name="ix")
ih=tf.Variable(tf.truncated_normal([num_nodes,num_nodes],-0.1,0.1),name="ih")
ib=tf.Variable(tf.zeros([1,num_nodes]),name="ib")
#output_gate 完整程式碼:
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 14 08:52:47 2017
@author: ZMJ
"""
from __future__ import print_function
import numpy as np
import tensorflow as tf
from six.moves import range
import collections
import random
import csv
from matplotlib import pyplot as plt
class BatchGenerator:
def __init__(self,window_size,window_range):
self.cursor=0.
self.window=window_size
self.range=window_range
def next(self):
x=np.zeros([self.window,1])
y=np.zeros([self.window,1])
d=np.arange(self.cursor,self.cursor+1.,1./self.window)
for i in range(self.window):
l=np.sin(d[i])
x[i,0]=d[i]
y[i,0]=l
self.cursor+=1./self.window
return y[:self.window-1],y[1:],x[:self.window-1]
num_nodes=64
window_size=5
window_range=10
num_unrollings=100
graph=tf.Graph()
with graph.as_default():
#引數初始化
#input gate
ix=tf.Variable(tf.truncated_normal([window_size-1,num_nodes],-0.1,0.1),name="ix")
ih=tf.Variable(tf.truncated_normal([num_nodes,num_nodes],-0.1,0.1),name="ih")
ib=tf.Variable(tf.zeros([1,num_nodes]),name="ib")
#output_gate
ox=tf.Variable(tf.truncated_normal([window_size-1,num_nodes],-0.1,0.1),name="ox")
oh=tf.Variable(tf.truncated_normal([num_nodes,num_nodes],-0.1,0.1),name="oh")
ob=tf.Variable(tf.zeros([1,num_nodes]),name="ob")
#forget_gate
fx=tf.Variable(tf.truncated_normal([window_size-1,num_nodes],-0.1,0.1),name="fx")
fh=tf.Variable(tf.truncated_normal([num_nodes,num_nodes],-0.1,0.1),name="fh")
fb=tf.Variable(tf.zeros([1,num_nodes]),name="fb")
#cell
gx=tf.Variable(tf.truncated_normal([window_size-1,num_nodes],-0.1,0.1),name="gx")
gh=tf.Variable(tf.truncated_normal([num_nodes,num_nodes],-0.1,0.1),name="gh")
gb=tf.Variable(tf.zeros([1,num_nodes]),name="gb")
#variables saving state across unrollings
saved_output=tf.Variable(tf.zeros([1,num_nodes]),trainable=False,name="saved_output")
saved_state=tf.Variable(tf.zeros([1,num_nodes]),trainable=False,name="saved_state")
#classifier's weights and biases
w=tf.Variable(tf.truncated_normal([num_nodes,window_size-1],-0.1,0.1),name="w")
b=tf.Variable(tf.zeros([window_size-1]),name="b")
##定義LSTM cell
def lstm_cell(x,h,c):
input_gate=tf.sigmoid(tf.matmul(x,ix)+tf.matmul(h,ih)+ib)
output_gate=tf.sigmoid(tf.matmul(x,ox)+tf.matmul(h,oh)+ob)
forget_gate=tf.sigmoid(tf.matmul(x,fx)+tf.matmul(h,fh)+fb)
gt=tf.tanh(tf.matmul(x,gx)+tf.matmul(h,gh)+gb)
ct=input_gate*gt+forget_gate*c
return output_gate*tf.tanh(ct),ct
#Input Data
train_data=list()
train_label=list()
for _ in range(num_unrollings+1):
train_data.append(\
tf.placeholder(tf.float32,shape=[1,window_size-1]))
train_label.append(\
tf.placeholder(tf.float32,shape=[1,window_size-1]))
train_inputs=train_data
train_labels=train_label
#將LSTM展開
outputs=list()
output=saved_output
state=saved_state
for i in train_inputs:
output,state=lstm_cell(i,output,state)
outputs.append(output)
#將最後一層LSTM的輸出和隱藏層儲存
with tf.control_dependencies([saved_output.assign(output),\
saved_state.assign(state)]):
#一層LSTM的RNN搭建
logits=tf.nn.xw_plus_b(tf.concat(0,outputs),w,b)
loss=tf.reduce_mean(\
tf.reduce_sum(tf.square(tf.concat(0,train_labels)-logits))
)
#optimizer
global_step=tf.Variable(0)
learning_rate=tf.train.exponential_decay(0.8,global_step,1000,0.5)
optimizer=tf.train.GradientDescentOptimizer(learning_rate)
gradients,v=zip(*optimizer.compute_gradients(loss))
gradients,_=tf.clip_by_global_norm(gradients,1.25)
optimizer=optimizer.apply_gradients(\
zip(gradients,v),global_step=global_step)
#Predictions
train_prediction=logits
#test eval:batch 1,no unrolling
sample_input=tf.placeholder(tf.float32,shape=[1,window_size-1])
saved_sample_output=tf.Variable(tf.zeros([1,num_nodes]))
saved_sample_state=tf.Variable(tf.zeros([1,num_nodes]))
reset_sample_state=tf.group(\
saved_sample_output.assign(tf.zeros([1,num_nodes])),\
saved_sample_state.assign(tf.zeros([1,num_nodes])))
sample_output,sample_state=lstm_cell(\
sample_input,saved_sample_output,saved_sample_state)
with tf.control_dependencies([saved_sample_output.assign(sample_output),\
saved_sample_state.assign(sample_state)]):
sample_prediction=tf.nn.xw_plus_b(sample_output,w,b)
num_steps=10001
summary_frequency=100
f=file("out.csv","a+")
writer=csv.writer(f)
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print("Initialized!!")
mean_loss=0
feed_dict=dict()
count=0
test=BatchGenerator(window_size,window_range)
for i in range(num_unrollings+1):
temp1,temp2,_=test.next()
feed_dict[train_data[i]]=temp1.reshape([1,window_size-1])
feed_dict[train_label[i]]=temp2.reshape([1,window_size-1])
for step in range(num_steps):
_,l,predictions,lr=session.run([optimizer,loss,train_prediction,learning_rate],feed_dict=feed_dict)
if step%100==0:
print(l)
X=list()
Label=list()
Prediction=list()
for i in range(100):
data,label,x=test.next()
feed=data.reshape([1,window_size-1])
prediction=sample_prediction.eval({sample_input:feed})
X.append(x)
Label.append(label)
Prediction.append(prediction)
Prediction=np.array(Prediction).reshape([1,100*(window_size-1)])
Label=np.array(Label).reshape([1,100*(window_size-1)])
X=np.array(X).reshape([1,100*(window_size-1)])
print(Label,Prediction)
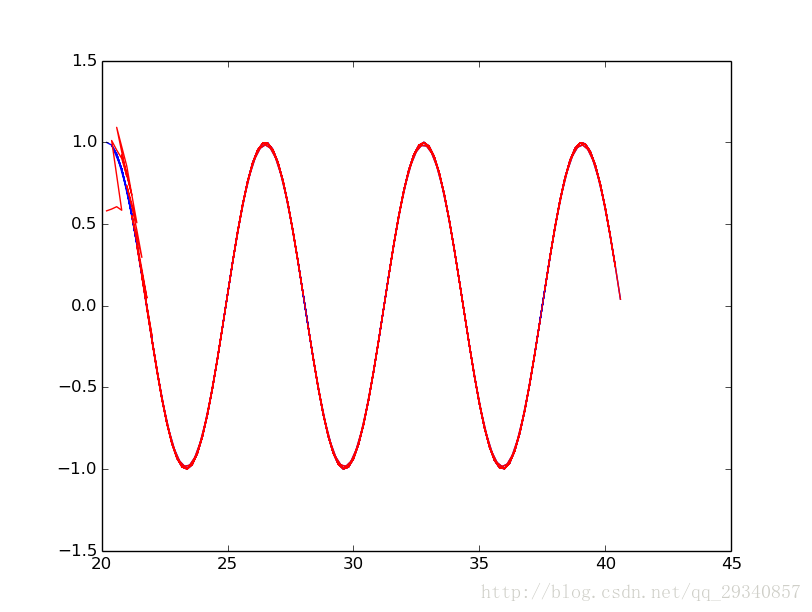
plt.plot(X[0],Label[0],color="blue")
plt.plot(X[0],Prediction[0],color="red")
plt.show()
plt.savefig("out.png")
writer.writerows([data.T[0],label.T[0],prediction[0]])
f.close()擬合的資料結果: