
Python3[爬蟲實戰] scrapy爬取汽車之家全站連結存json檔案
昨晚晚上一不小心學習了崔慶才,崔大神的部落格,試著嘗試一下爬取一個網站的全部內容,福利吧網站現在已經找不到了,然後一不小心逛到了汽車之家 (http://www.autohome.com.cn/beijing/)
很喜歡這個網站,女人都喜歡車,更何況男人呢。(捂臉)
說一下思路:
1 . 使用CrawlSpider 這個spider,
2. 使用Rule
上面這兩個配合使用可以起到爬取全站的作用
3. 使用LinkExtractor 配合Rule可以進行url規則的匹配
4. FormRequest 這是scrapy 登陸使用的一個包
注意:這裡進行全站的爬取只是單純的把以 .html
這裡我們還可以繼續往下深入的,進行url下的內容提取。
說一下提取的思路:這裡我們可以隨便找一個url下的內容,然後找到想要提取到的內容,進行xpath提取,
xpath 的一般提取規則:選中想要提取內容的那一行,然後右鍵copy --> copy xpath 就可以啦,這裡老司機說是最好用chrom瀏覽器的xpath,火狐可能有時候提取不到想要的元素,
xpath提取的簡單並且常用的規則:
//*[@id=”post_content”]/p[1]
意思是:在根節點下面的有一個id為post_content的標籤裡面的第一個p標籤(p[1 上面就是簡單的提取規則,是不是很容易懂,我覺著也是,比之前學的容易懂多了,可能我現在還是個小白吧。哈哈哈。
附錄一下:
關於imgurl那個XPath:
你先隨便找一找圖片的地址Copy XPath類似得到這樣的:
//*[@id=”post_content”]/p[2]/img
你瞅瞅網頁會發現每一個有幾張圖片 每張地址都在一個p標籤下的img標籤的src屬性中
把這個2去掉變成:
//*[@id=”post_content”]/p/img
就變成了所有p標籤下的img標籤了!加上 /@src 後所有圖片就獲取到啦!(不加[0]是因為我們要所有的地址、加了 就只能獲取一個了!)
關於XPath更多的用法與功能詳解,建議大家去看看w3cschool看來我確實沒有怎麼看w3c啊。還是抓個時間去看一下比較好, 畢竟是基礎嘛。
大概:廢話就這麼多,我真是個話癆,感覺。
貼上程式碼片吧,裡面的內容註釋都很詳細。
步驟1:
spider裡面的檔案
# -*- coding: utf-8 -*-
# @Time : 2017/8/27 0:43
# @Author : 蛇崽
# @Email : [email protected] (主要進行全站爬取的練習)
# @File : LongXunDaoHangSpider.py
# crawlspider,rule配合使用可以起到遍歷全站的作用,request為請求的介面
from scrapy.spider import CrawlSpider,Rule,Request
# 配合使用Rule進行url規則匹配
from scrapy.linkextractors import LinkExtractor
# scrapy 中用作登陸使用的一個包
from scrapy import FormRequest
from allNet.items import LongXunDaoHang
class longxunDaoHang(CrawlSpider):
name = 'longxun'
allowed_domains = ['autohome.com.cn']
start_urls = ['http://www.autohome.com.cn/shanghai/']
rules = (
Rule(LinkExtractor(allow=('\.html',)),callback='parse_item',follow=True),
)
def parse_item(self,response):
print(response.url)
daohang = LongXunDaoHang()
daohang['categoryLink'] = response.url
yield daohang步驟2:
settings.py的內容:
# -*- coding: utf-8 -*-
# Scrapy settings for allNet project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'allNet'
SPIDER_MODULES = ['allNet.spiders']
NEWSPIDER_MODULE = 'allNet.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'allNet (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = True
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'allNet.middlewares.AllnetSpiderMiddleware': 543,
# }
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'allNet.middlewares.MyCustomDownloaderMiddleware': 543,
# 'allNet.middleware.JsonWritePipline':300,
# }
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'allNet.pipelines.AllnetPipeline': 300,
'allNet.pipelines.JsonWritePipline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
步驟3:
piplines.py的內容
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class AllnetPipeline(object):
def process_item(self, item, spider):
return item
# 寫入json檔案
class JsonWritePipline(object):
def __init__(self):
self.file = open('汽車之家全站url.json','w',encoding='utf-8')
def process_item(self,item,spider):
line = json.dumps(dict(item),ensure_ascii=False)+"\n"
self.file.write(line)
return item
def spider_closed(self,spider):
self.file.close()很奇怪的是,汽車之家這裡用的cookie什麼的都沒有進行設定,但是爬取全站這玩意,它就一直沒有報錯,昨天晚上十二點左右寫的程式碼,想著用scrapy應該不一會就爬取完了吧,但是現在早上還一直在爬,我也是醉了,晚上好幾次電腦進行休眠了,然後我又把他重新弄亮了,現在有點奇葩的是,現在spider還在執行著,但是json檔案寫不進去了,蠻怪怪的。最後上張爬取成果圖吧:
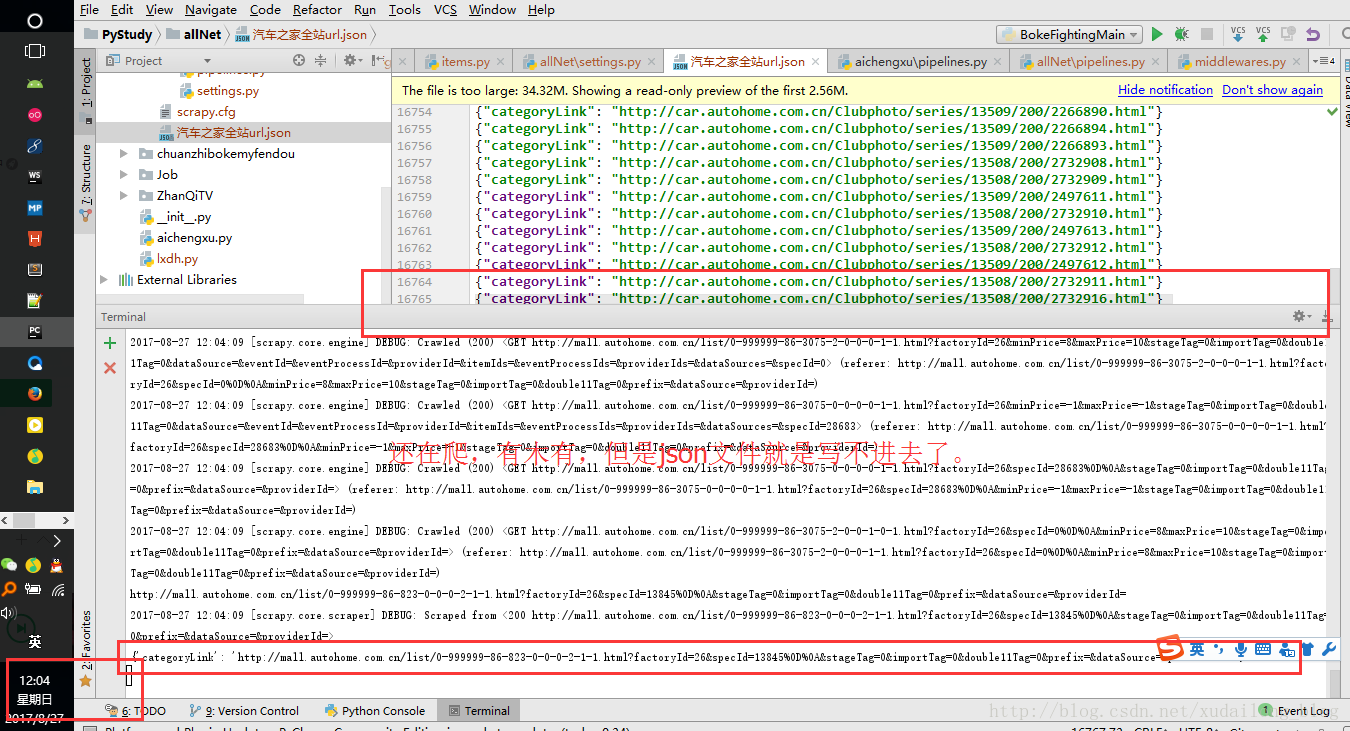
這裡留給自己一個作業:在爬取的url中進行資料的提取,儲存,簡單點:就是url下面內容的進行儲存。(捂臉.jpg)
相關推薦
Python3[爬蟲實戰] scrapy爬取汽車之家全站連結存json檔案
昨晚晚上一不小心學習了崔慶才,崔大神的部落格,試著嘗試一下爬取一個網站的全部內容,福利吧網站現在已經找不到了,然後一不小心逛到了汽車之家 (http://www.autohome.com.cn/beijing/) 很喜歡這個網站,女人都喜歡車,更何況男人呢。(
Python練習 scrapy 爬取汽車之家文章
autohome.py #spider檔案 # -*- coding: utf-8 -*- import scrapy from Autohome.items import AutohomeItem class AutohomeSpider(scrapy.Spider)
python爬蟲實戰 爬取汽車之家上車型價格
相關庫 import pymysql import pymysql.cursors from bs4 import BeautifulSoup import requests import random
python3 爬取汽車之家所有車型操作步驟
題記: 網際網路上關於使用python3去爬取汽車之家的汽車資料(主要是汽車基本引數,配置引數,顏色引數,內飾引數)的教程已經非常多了,但大體的方案分兩種: 1.解析出汽車之家某個車型的網頁,然後正則表示式匹配出混淆後的資料物件與混淆後的js,並對混淆後的js使用pyv8進行解析返回
python網路爬蟲爬取汽車之家的最新資訊和照片
實現的功能是爬取汽車之家的最新資訊的連結 題目和文章中的照片 爬蟲需要用到我們使用了 requests 做網路請求,拿到網頁資料再用 BeautifulSoup 進行解析 首先先檢查是否安裝了pip,如果已經安裝了pip,直接pip install requests,pip uninstal
WebMagic爬蟲入門教程(三)爬取汽車之家的例項-品牌車系車型結構等
本文使用WebMagic爬取汽車之家的品牌車系車型結構價格能源產地國別等;java程式碼備註,只是根據url變化爬取的,沒有使用爬取script頁面具體的資料,也有反爬機制,知識簡單爬取html標籤爬取的網頁: 需要配置pom.xml <!-
python爬蟲——爬取汽車之家新聞
按F12審查一下元素:找到了對應的資訊。而且發現要爬取的圖片都在id=auto-channel-lazyload-article的div標籤下的li標籤裡。 li標籤下的a標籤就是新聞的url;image標籤,src就是獲取圖片的url; 請求圖片地
【Python3爬蟲】Scrapy爬取豆瓣電影TOP250
今天要實現的就是使用是scrapy爬取豆瓣電影TOP250榜單上的電影資訊。 步驟如下: 一、爬取單頁資訊 首先是建立一個scrapy專案,在資料夾中按住shift然後點選滑鼠右鍵,選擇在此處開啟命令列視窗,輸入以下程式碼: scrapy startprojec
Python3爬蟲實戰:爬取大眾點評網某地區所有酒店相關資訊
歷時一下午加一晚上,終於把這個爬蟲程式碼寫好,後面還有很多想完善的地方(譬如資料儲存用redis、使用多執行緒加快速度、爬取圖片、細分資料等等),待有空再做更改,下面是具體的步驟與思路: 工具:PyC
python入門-----爬取汽車之家新聞,---自動登錄抽屜並點贊,
ike color div標簽 pla spa art com col 3-9 爬取汽車之家新聞,代碼如下 import requests res=requests.get(url=‘https://www.autohome.com.cn/news/‘) #向汽車直接
爬取汽車之家
ref article brush att split channel odin lazy com import requests from bs4 import BeautifulSoup response = requests.get(‘https://www.aut
爬取汽車之家北京二手車資訊
爬取汽車之家北京二手車資訊 經測試,該網站:https://www.che168.com/beijing/list/ 反爬機制較低,僅需要偽造請求頭設定爬取速率,但是100頁之後需要登入,登入之後再爬要慎重,一不小心就會永久封號。爬取的資料以各種型別存放,下面展示儲存到mysql資料
python3程式設計08-爬蟲實戰:爬取網路圖片
本篇部落格爬取內容如下: 爬取校花網的圖片 準備工作: 1.安裝python3 2.安裝pycharm 3.安裝Scrapy,參考:Scrapy安裝 cmd命令新建Scrapy工程 1. 在D:\PythonProjects目錄下新建
python3程式設計07-爬蟲實戰:爬取新聞網站資訊3
本篇部落格在爬取新聞網站資訊2的基礎上進行。 主要內容如下: 1.定義獲取一頁20條連結內容的函式 2.構造多個分頁連結 3.抓取多個分頁連結新聞內容 4.用pandas整理爬取的資料 5.儲存資料到csv檔案 6.Scrapy的安裝
初識Scrapy框架+爬蟲實戰(7)-爬取鏈家網100頁租房資訊
Scrapy簡介 Scrapy,Python開發的一個快速、高層次的螢幕抓取和web抓取框架,用於抓取web站點並從頁面中提取結構化的資料。Scrapy用途廣泛,可以用於資料探勘、監測和自動化測試。Scrapy吸引人的地方在於它是一個框架,任何人都可以根
Python爬蟲實戰詳解:爬取圖片之家
前言 本文的文字及圖片來源於網路,僅供學習、交流使用,不具有任何商業用途,版權歸原作者所有,如有問題請及時聯絡我們以作處理 如何使用python去實現一個爬蟲? 模擬瀏覽器請求並獲取網站資料在原始資料中提取我們想要的資料 資料篩選將篩選完成的資料做儲存 完成一個爬蟲需要哪些工具 Python3.6 p
python 爬蟲實戰4 爬取淘寶MM照片
寫真 換行符 rip 多行 get sts tool -o true 本篇目標 抓取淘寶MM的姓名,頭像,年齡 抓取每一個MM的資料簡介以及寫真圖片 把每一個MM的寫真圖片按照文件夾保存到本地 熟悉文件保存的過程 1.URL的格式 在這裏我們用到的URL是 http:/
【Python3 爬蟲】14_爬取淘寶上的手機圖片
head 並且 淘寶網 pan coff urllib images 圖片列表 pic 現在我們想要使用爬蟲爬取淘寶上的手機圖片,那麽該如何爬取呢?該做些什麽準備工作呢? 首先,我們需要分析網頁,先看看網頁有哪些規律 打開淘寶網站http://www.taobao.com/
教你分分鐘學會用python爬蟲框架Scrapy爬取你想要的內容
python 爬蟲 Scrapy python爬蟲 教你分分鐘學會用python爬蟲框架Scrapy爬取心目中的女神 python爬蟲學習課程,下載地址:https://pan.baidu.com/s/1v6ik6YKhmqrqTCICmuceug 課程代碼原件:課程視頻:教你分分鐘學會用py
python3爬蟲-快速入門-爬取圖片和標題
瀏覽器 ebr tle path requests itl edi 大致 應用 直接上代碼,先來個爬取豆瓣圖片的,大致思路就是發送請求-得到響應數據-儲存數據,原理的話可以先看看這個 https://www.cnblogs.com/sss4/p/7809821.html